
枫林 发表于:13年10月15日 15:28 [原创] DOIT.com.cn
存储系统的缓存作用是加速数据读取与写入的速度,从而提升整体的存储性能。Symmetrix缓存机制,作为存储阵列的核心技术,对阵列的性能和高可用性起着至关重要的作用。本文对Symmetrix最新的两代产品缓存中的数据类型进行介绍。帮助存储管理员更好的了解Symmetrix的缓存工作机制。
缓存中的数据:
缓存主要的目的是用来缓冲磁盘上的I/O。Symmetrix的缓存分为两个部分,用户数据区域(User Data Slots)和系统数据区域(Global System Data)。
•用户数据区域(User Data Slots): 用户数据区域会被划分成很多的Slots用来缓冲前端的I/O。一旦前端的读写要求缓存存放数据,系统会分配相应的Slot用作存储数据。缓存会对于前端呈现相关的磁盘设备的的Track给前端主机,直到该Slot被释放或者被重用。并且对于DMX-3或者更高版本的阵列,User Data是以镜像的方式存储的(DMX是两块内存卡,VMAX的话则是两个Director)。
•系统数据区域(Global System Data):缓存中除了存放用户数据以外,还会存放一些供Director使用的系统数据,例如磁盘设备列表(Device Table)列出了每个Slot对应的磁盘设备位置,可以让Director在缓存中找到对应的数据。Director Mailboxes存放了各个Director相互通讯的命令集。对于DMX阵列,Global System Data会以条带的方式存放在每个物理内存板中。

缓存区域大小:
扇区(Sector),磁道(Track),柱面(Cylinder)是Symmetrix阵列中磁盘存储的三个基础数据大小。
•Sector: Sector是一磁盘上上最小的单元,后端的硬件不会传输小于一个Secotr大小的数据到缓存中。Symmetrix会对所有在阵列中传输的数据进行CRC校验,一旦校验发现数据损坏,数据会被重新传输或者标注相应的物理磁盘区域为已损坏。DMX-3以后的Symmetrix中Sector的大小为8KB。DMX至DMX-2的版本中大小为4KB。
•Track: Track是由8个Sector所组成。当磁盘数据中一个Track在缓存中呈现,该缓存区域就会成为一个可用的Slot。DMX-3以后的Symmetrix中Track的大小为64KB。DMX至DMX-2的版本中大小为32KB 。这个改变也是为了增加缓存读取击中的比例。
•Cylinder:单个Cylinder由15个连续的Track组成,但是并非根据Symmetrix中所配置的物理磁盘所分布,是一个虚拟的概念,这连续的Track可能分布在不同的物理磁盘上。Cylinder的大小有时候也会用作计量磁盘设备Device和Meta Device的大小。DMX-3以后的Symmetrix中Cylinder的大小为960KB。DMX至DMX-2的版本中大小为480KB。
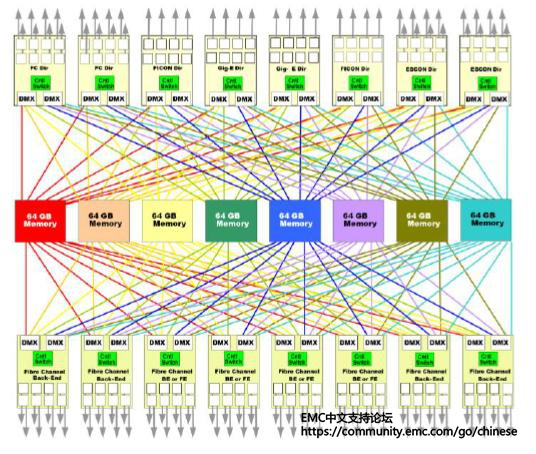
DMX和VMAX的缓存架构:
DMX存储阵列中包含了2-8个缓存卡,每个缓存卡最大容量是64GB,每个Director都会有直连的Fibre Channel连接到每个缓存卡上面。总的连接数量取决于卡的数量。
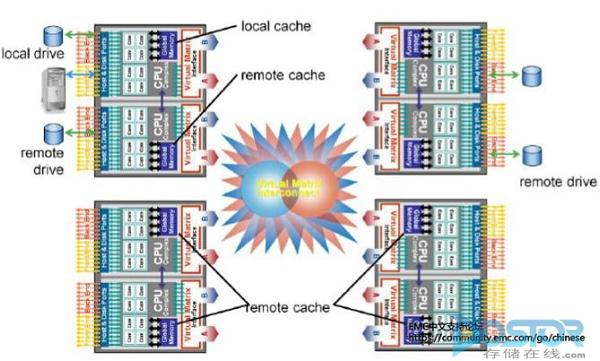
VMAX中,缓存存储在每个Director的缓存中。有Local Cache和Remote Cache之分。Director之间通过Virtual Matrix交换网络相互访问各自的缓存。
前端主机I/O请求在Symmetrix缓存中数据的访问模式主机端发起了I/O操作以后,I/O读取或者写入请求传送到Symmetrix前端口。根据数据存在于缓存与否,以及读写类型,Symmetrix会将I/O操作分为以下几种情况:
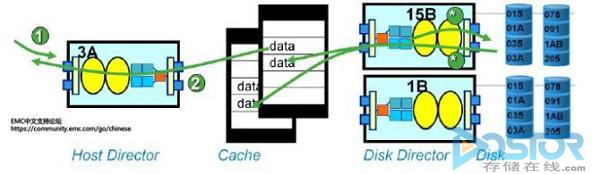
1. 读命中(Read Hit):在这种情况下,如下图所示。当主机端发送I/O请求到Symmetrix以后。如果所请求的数据,已经存在与缓存中(可能是之前的I/O已经被数据加载到缓存中),Director会直接将缓存中的数据传送回主机。虽然数据在缓存中已镜像的方式存储,但是任何读取操作都只会读取其中的一份镜像。

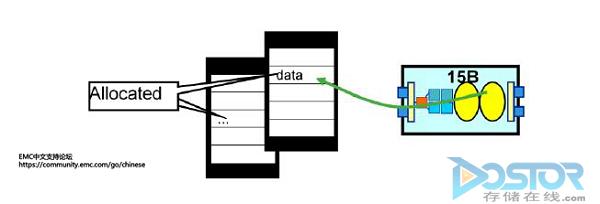
2. 读取未命中(Read Miss): 在这种情况下,如下图所示,主机端I/O请求的数据没有在缓存中。相关的Director会从后端的磁盘上获取所需要的数据。一旦磁盘返回数据,Director中的后端Disk Adaptor会将相应的数据存放到缓存中,如果是缓存镜像,则后端Disk Adaptor会在缓存中写入两份数据。最后Director会将数据再发送给主机。读取未命中比读取命中消耗更多的时间,因为主机端必须等待Symmetrix从后端磁盘中获取数据。

因为从DMX-3开始的版本中,使用的缓存镜像机制。Enginuity也对于这种镜像缓存进行了优化算法。镜像缓存选择优化主要的改进是,Enginuity允许Director对于读取请求同时定位两个缓存Slot,但是只读取其中的一个。从而减少后端的传输开销。一旦缓存出现错误,也可以简单的再从磁盘中重读。这种优化对于大I/O的读取未命中会有30%的性能提升,
3. 顺序读和预读:预读机制用来产生额外的读取命中。当Symmetrix检测到两个数据读请求是从连续的位置获取的,则相应的后端Director会启动预读任务。后端Director会尝试先于前端主机的请求,从额外的Track中读取数据到缓存中,随着被存放在缓存中的数量增加,如果前端主机连续的读取顺序的数据,就会发现数据已经存在与缓存中了。当然,后端Director不会知道到底主机的顺序读会在哪里停止,一些预读工作可能会被浪费,不过鉴于读取命中的速度会比读取未命中来的高出血多,所以通过预读进性能提升还是非常显著的。
4. 写入命中(Write Hit):也叫快速写入,写入命中的情况发生在缓存中有足够空间用来存储需要写入的数据。对于主机端的写入请求,后端Director找到可用的缓存Slot,然后将数据传输到缓存中,然后立刻给主机写入完成信号。主机端即认为写入已经完成。对应的缓存Slot会被标记为写入等待状态(Write Pending),直到数据写入到物理磁盘以后才能够再被使用。如果缓存是镜像的,Director需要在镜像中分别写入数据。写入到后端磁盘(de-stage)是批量进行的,通常会处于比较低的优先级下进行,但是如果当写入等待状态的缓存使用率达到比较高的值的话(DMX默认是50%,VMAX是75%),则Symmetrix会进入优先de-stage模式,加快写入磁盘的速度。
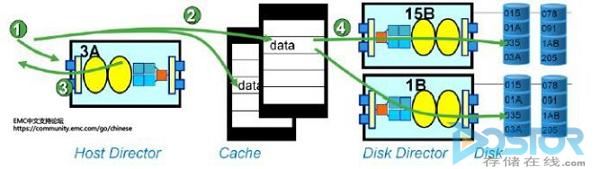
5. 写入未命中(Deplayed Fast Write):也叫延迟快速写入,写入未命中的情况发生在当Symmetrix的缓存已经达到了写入等待上限的时候(VMAX是80%), 新的写入请求无法进行快速写入,会触发将现有的写入等待数据立刻写入到磁盘的操作,当Director观察到缓存中有空闲空间的时候,完成写入命中操作,将数据写入到缓存中。也就是说延迟快速写入也就是有等待时间的快速写入。

接下来解读解读影响Symmetrix性能的几种缓存参数,System Write Pending Limits、Device Write Pending Limits和DA Write Pending Limits。
System Write Pending Limits:
我们介绍了写入等待Write Pending Limit的概念。Write Pending Limit缓存Slot是用来存放(对应快速写入)已经在内存中修改,但还未最后写入到后端磁盘上的数据。当Write Pending的Slot达到一定的数量,并且达到系统中的上限以后,会触发Delay Fast Write,从而使整个阵列的性能有所降低。而Write Pending Limit就是Symmetrix存储阵列中用作写入等待的最大上限。VMAX Enginuity 5875以后是75%,之前的VMAX和DMX都是80%的总缓存比例:
Device Write Pending Limits:
除了System Write Pending Limits以外,缓存中还有针对Symmetrxi磁盘设备(逻辑卷)的Device Write Pending Limits。它的作用是保证单个磁盘设备的不会占用太多的Write Pending缓存Slot,从而影响到其他磁盘设备的性能。所有的磁盘设备都包含了一样的上限值,而且所有磁盘设备的上限相加会大于整个缓存slot的数量。对于Symmetrix的Meta Device,组成它的Member都会包含有一个相应的Device Write Pending值。
DA Write Pending Limits:
DA WritePending Limits默认情况下等于50%的System Write Pending Limits。这个值通常是用来触发缓存压力事件的“Cache Stress“。 Cache Stress是Symmetrix用来定义是否有过多的Write Pending Slot,其中一个主要的指标就是DA Write Pending Limits值。但整体的Write Pending的数量达到DA Write Pending Limits的时候,Symmetrix就会进入Cache Stress模式。进入Cache Stress模式以后symmetrix会改变缓存操作的模式。例如Director会进入优先Destatge模式,使用相同时间来处理destage数据和应付Read Miss操作。这些活动都会短暂的降低系统性能,读取和写入都会受到影响。不过长期来看,当缓存释放以后,整体的性能将恢复。
达到Write Pending Limits的影响:
当Symmetrix阵列达到Write Pending Limit的时候,会对整体的写入性能有比较大的影响。如果写入发生,Symmetrix阵列在接到写入请求以后会尝试分配Cache Slot,然后检查Write Pending Limits是否已经到达,如果是,会直接触发Write Miss。新的Cache Slot不会被分配,直至Write pending的slot destage到后端的磁盘上。虽然Director会进入最高级别的destage模式,但是主机的写入还是因为这种情况而变慢。但是如果,前端的写入频繁发生在一个磁盘区域中,同一个Cache Slot会被标注成Write Pending模式,但是对于多次写或者重复写发生在一个Cache Slot中,因为不需要重新分配新的Cache Slot,则影响会相对小一些。
下图给出了一个Symmetrix阵列达到Write Pending Limit后影响的例子。这个测试是在128个Device上进心的,前端模拟了大量的写入请求,以至于超过当前阵列的承受范围。最初,由于有足够的缓存,则阵列处于告诉的Write Hit状态,下图我们可以看到每秒可以有15000 IOPS,但是随着时间的推移,当40%的Cache Slot被Write pending所用的时候,Symmetrix进入到cache stress模式。后端Director会使用更多的资源来进心destage。磁盘本身也达到了自身的Write Pending Limit。这种情况下,我们可以看到整体的IOPS开始下降,写入的反应时间也开始随之升高,IOPS达到了10000左右。40秒以后,System Write Pending达到了80%。虽然symmetrix加快了destage的速度,还是没有来得及处理写入请求。在某一个时间点会出现一个下降的峰值,随后缓存将无法在加速写入请求。写入的反应速度与后端destage的速度保持一致,IOPS下降到5000左右。

本文作者为EMC中文技术社区(https://community.emc.com/go/chinese)技术版主。如果您对本文有任何疑问和不同见解,也欢迎到EMC中文支持论坛参与讨论。




