
IT邵年 发表于:14年07月01日 10:28 [原创] DOIT.com.cn
世界的那端,世界杯球赛激战正酣,而在世界的另一端,一场人类所研发的机器智慧也在挑战着新的极限。上周初,在德国的莱比锡ISC2014国际超级计算大会上中国的天核二号再一次拿到世界第一,非常振奋,这也应该算是6月对于中国来说最好的消息了。
了解服务器的人可能都知道,国际超算大会是计算机应用界的奥林匹克运动会,世界上顶尖的工程师,要通过计算机的研发与采购,系统架构的设计和软件调优,最后让整个超级运算系统达到一个更高的水平。这次蝉联Top500冠军的天河二号由1.6万个浪潮节点组成,配备了3.2万颗Intel Ivy Bridge-EP Xeon E5 2692 v2 2.2GHz 12核心处理器、4.8万个Intel Xeon Phi 31S1P 57核心协处理计算卡,Linpack峰值浮点计算能力为54902.4TFlops(54.9PFlops),也就是每秒钟5.49亿亿次,最大计算能力为33862.7TFlops,亦即接近3.4亿亿次每秒。
超级计算机看似离我们的工作生活很远,其实我们每天都在间接享受它所提供的服务,比如每天的气象预测,都需要用超级计算机来运算,另外石油的勘探、汽车设计的仿真模拟、医疗病毒的观测和基因测序,都离不开超级计算机在背后的帮助。
但是,在最近新上榜的114套设备中,其中111套都来自于搭载Intel处理器的设备,这惊人的变化让我们看到了Intel在超级计算领域的强大实力。

正好,英特尔中国区平台产品事业部产品市场经理汤炜伟先生为我们讲解了英特尔在超级计算领域的策略和未来一年的产品计划,让我们一睹未来产品的震撼性能。
首先,汤炜伟先生与大家共享了英特尔在TOP500强上的出色成绩,500套上榜系统英特尔占据了427套,比例是85.4%, 114套新晋系统中的111套,97%的比例,同时还获得2014PRACE-ISC大奖,在英特尔架构上持续提供了PetaFlops一个真实科学计算性能,不是普通的标准而是真实的科学计算性能在大规模的技术上。
另外值得提到一点的就是英特尔至强融核,在这次TOP500的榜单上有19套采用了Xeon Phi加Xeon的微异构系统,并且天河二号以33.9 PFlops保持了TOP500的第一名。
那么取得了这么多的荣誉后,英特尔也在思考超级计算的未来,在冲击更高的峰值计算的目标上,越高挑战就会越大,如何构建新的策略来完成这个目标,是非常重要的。
英特尔认为需要从根本上进行一个改变,这个改变源自软件模型,也就是标准的定型的编程的模型,包括软件的底层,就OPEN MP或者顶层的各种ISV的软件,开源社区的软件,以及各家科研机构、大学等等研发的自己的代码。图中是英特尔的硬件如何跟这些软件无缝的兼容,大家看到处理器的性能,需要适应应用的变化。内存和存储,包括能耗、能效,大家看到能耗越来越高。高速的互连,可靠性和弹性弹性指的是横向可扩展的能力,以及各种根据软件定义的这种计算能力的变化。
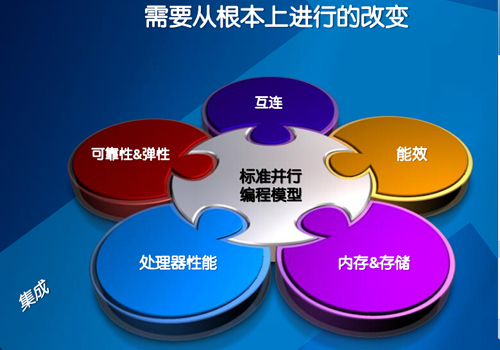
所以在这张图中英特尔用集成来概括了所有的内涵。面对高性能计算,他需要一个软硬件融合,硬件平台集成的产品,那也就是接下来要发布的产品——Knights Landing。
Knights Landing的上一代产品是Knights Corner,也就是我们说的Intel Xeon Phi协处理器,从2012年发布到现在也有18个月的时间了,接下来英特尔会将Knights Landing带给市场,其投入商用的时间大约是2015年下半年。
英特尔在基于业界目前的市场状况以及业界对于将来的技术和产品的趋势的需求,准备发布这样一款产品,它有很多非常好的一个新的特性,比如说它有超过三个TERAFLOPS的单个封装的并行性能,这是比现在的Knights Corner要高大概2.5倍的规模,特别值得一提的一点Knights Corner的产品形态是PCIE的形式,那么在Knights Landing有一个革命性的变化,它不光有PCIe的插卡的形态,也将会有安装在主办插槽的作为主处理器的产品形态。汤炜伟先生特意解释了这个革命性的变化:“革命性体现在哪里呢?首先通过对于计算,计算我们是采用的低功耗的IA的内核,专门为高性能的计算优化的一个微架构,每个线程会提高到原来的三倍的性能的提升。同时呢,一个非常重要的一点,就是可以和英特尔至强处理器,这是和我们的Haswell的处理器的代码,实现一个二进制的兼容。同时,它的代码也会兼容Knights Corner,也就意味着所有的开发者、工程师在目前开发的平台上做的并行优化的努力,一直的努力在Knights Landing依然是有效的,他们的工作积累是可以得到保留和优化的。”

内存来说,英特尔Knights Landing五倍于下一代DDR4的带宽,DDR3的带宽大家都清楚,DDR4的带宽比DDR3提高了50%,而Knights Landing这个内存又是DDR4的五倍的带宽,所以这个提升非常的惊人。同时能效的提升高达5倍,因为片上的集成它会比比过去装载在PC板上的得到极大的提升,是三分之一空间。
另外两个重点一个是集成互连技术(Integrated Fabric),这是一个非常重要的特性,它会把下一代高速互连技术,也就是Fabric (互连)首先集成到Knights Landing的众核架构中。第二是英特尔Omni Scale 下一代互连技术,这个是为最大的可扩展性而设计的,拥有了极其丰富的一个片上的模型,灵活的配置,同时也是一个良好的端到端的解决方案,不管是在HOST也好,在交换机也好,在Director端也好,都是无缝的端到端的解决方案,这样的技术将会首先集成入Knights Landing。同时也将集成14纳米的Omni Scale的至强处理器。
关于这款产品的革命性突破,汤炜伟先生先生给了最后的总结:“如果我把互连也集成进来了,这个高速互连的控制器,比如我的CPU,如我的至强处理器融合处理器之间,这个带宽、延时是现有的技术无法比拟的,将达到极高的带宽,极高的产品的性能,并且极大的降低了过去系统计其所需要的一个比较大的体积和空间,对于产品的整机系统密度也会有极大的提升。”
我们知道,英特尔是一个做与计算相关的厂商,在今天这样的云计算和大数据的时代,超级计算成为一个快速发展的领域,也正是因为新产品的出现,才给未来的世界带来更多的精彩,从科学计算到我们看的3D大片,从智慧城市到车联网,到处都需要高性能计算,我们也会因为这些而得到更好的生活。




