
使用美信CreCloud云网管的同学多数都是技术出身,这对于快速掌握美信CreCloud云网管来说当然是得天独厚的优良基础。然而现在IT行业基本是为市场服务,如何能够让我们在市场人员和老板的眼中体现出价值,就需要我们把自己的工作更好的展现出来。
繁冗的日志报表显然不是非技术人员愿意看到的,如何更快、更简洁、更专业的表明自己的意图,才是最为重要的。
作为运维人员,老板有时会提出一些稀奇古怪的东西,或者其他部门出现了问题把责任怪罪到你头上。你应该如何申辩?把事实通过汇报的形式表现出来,能让非技术的他们看得懂,同时也要体现出专业性,不能干巴巴几句话,也就是所谓的“举证要充分”。
今天我们就来学习一下,通过美信CreCloud云网管强大的图表功能,为自己的汇报总结做出“充分的举证”。
前几日,部门接到业务部门的一个紧急事件通告,问题的状况是某两台服务器(0.176、0.61)之间随机性的ping失败,每次持续10分钟左右。业务部门怀疑基础网络这块存在故障,希望我们给与排查和处理。
接到通告后,我们首先是发邮件通知业务部门,告之我们会尽快处理。很庆幸的是,之前已经通过美信CreCloud云网管对着两台服务器有过监测,对CPU、内存、网络流量、磁盘空间以及ping都做了监测点。
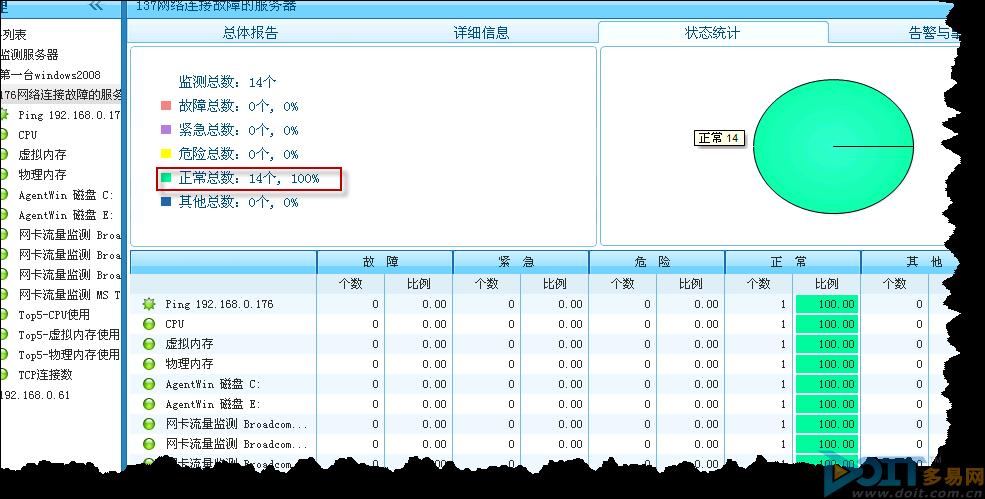
首先检查美信CreCloud云网管中0.176的服务器状态。通过图表可以看出,没有任何报错的项目。
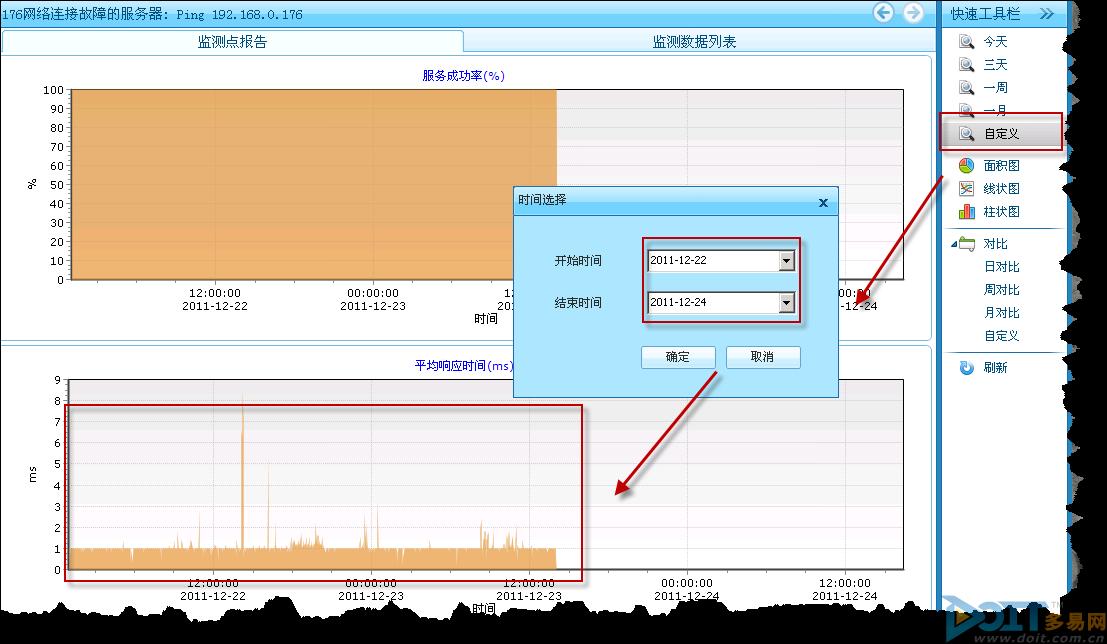
考虑到业务部门是随机性的出现10分钟左右的中断,如果机器存在硬件故障,那么美信CreCloud云网管肯定也会有所体现。美信CreCloud云网管对ping值的反馈是默认每2分钟一次,3000ms算超时,7*24小时任务制。我们查看ping的监控点,同时自定义发生故障的日期,可以查看到在此期间,ping的服务成功率是100%,同时相应时间最长也不超过8ms,并没有发现如业务部门所说的情况。
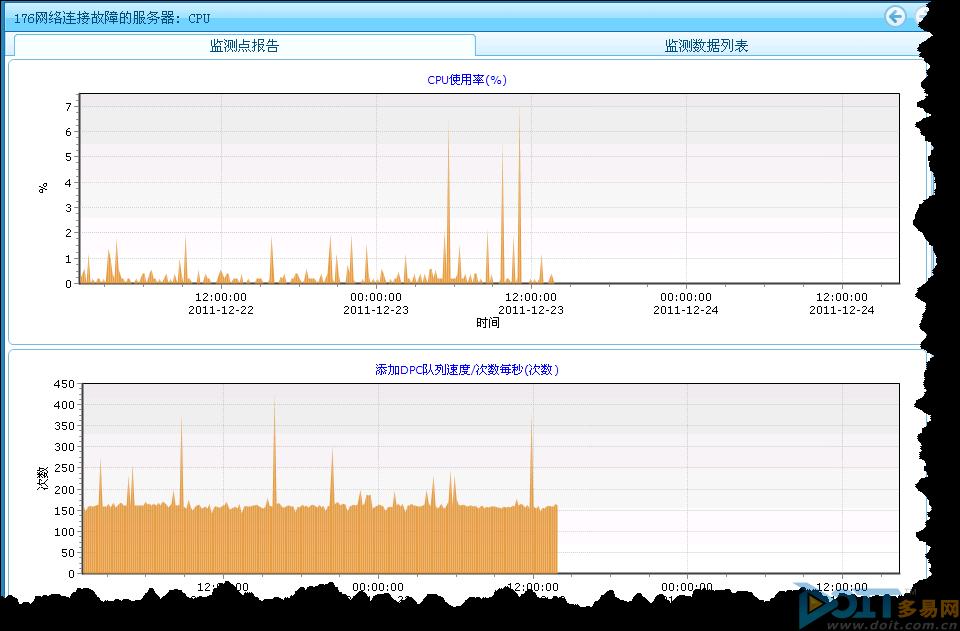
继续检查CPU利用率的情况,发现利用率较低,同时服务成功率也是100%。
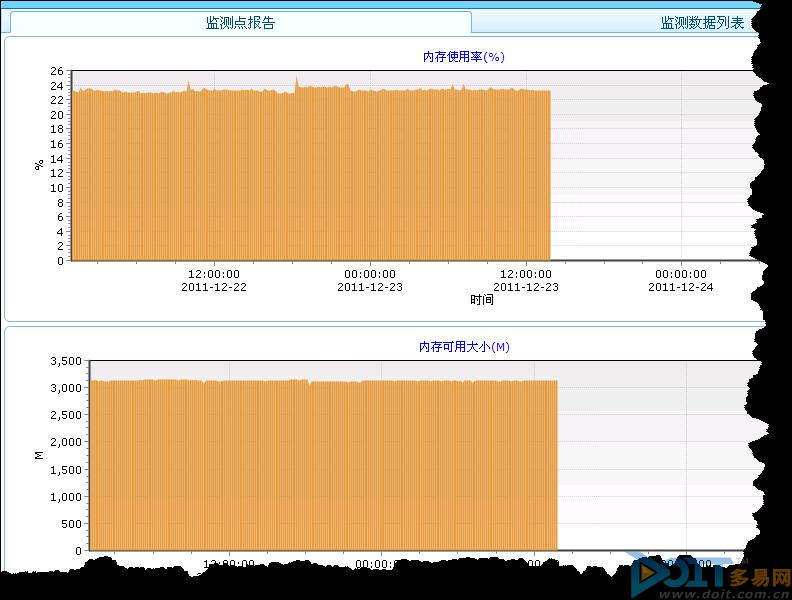
在物理内存方面的检测依然没有发现任何问题。
以同样的方法在0.61的服务器上进行了排查,结果和上面的并无二致。因此可以判断问题并不在网络硬件方面。
最终与业务部门共同检查,发现问题出在“应用”上。0.176上跑的是业务部门自己写的一个服务。于是我们将该服务添加到美信CreCloud云网管的监控点上继续排查故障。最终发现该服务随机性的挂死,在测试的两个小时内,服务就挂掉了两次。(在图表中,实心区域是正常时间段,空心区域是服务失败的时间段。)
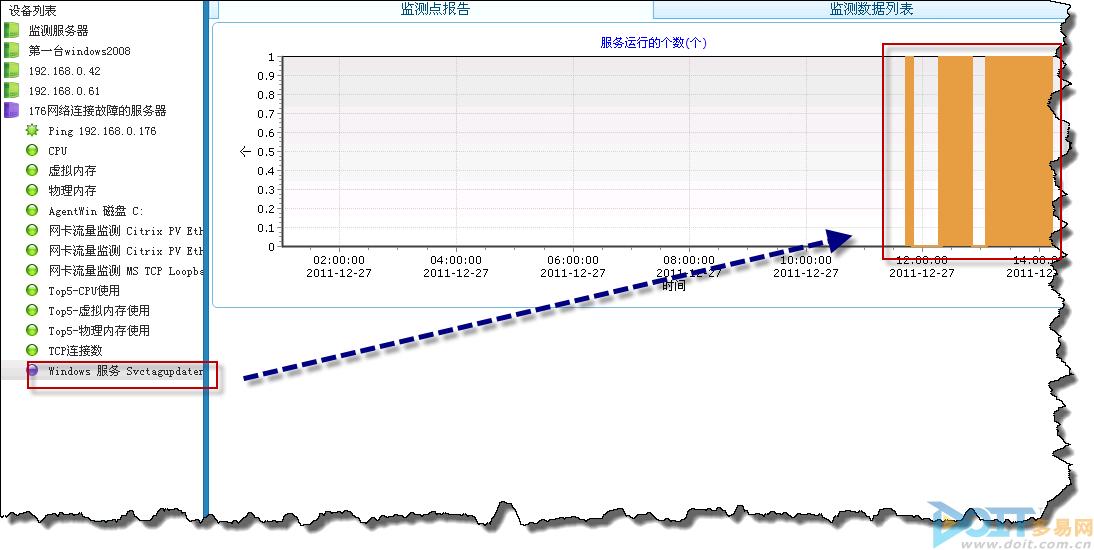
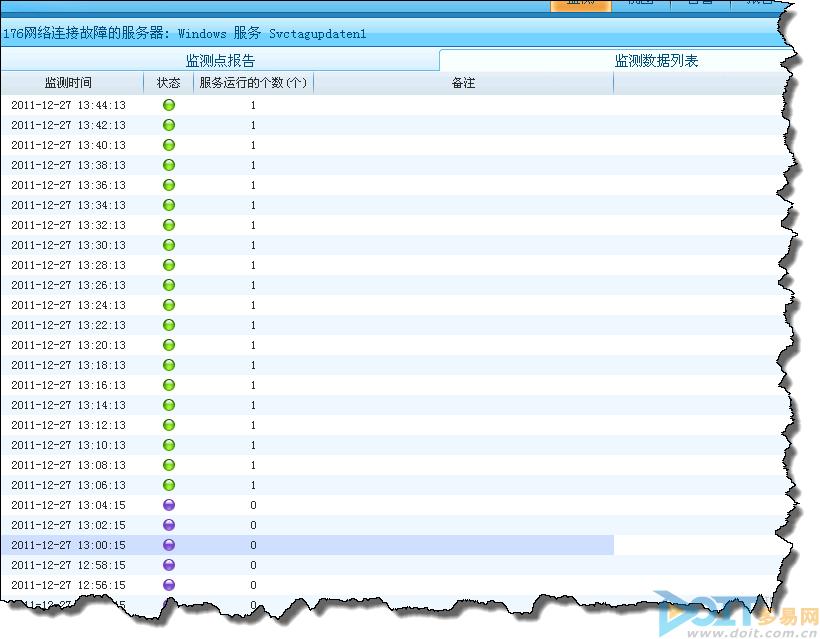
在监测数据列表中,还可以查看到发生故障状态的具体时间,以及持续时间等详细信息。
从业务部门提出疑惑,到我们给出专业的答案,整个过程不超过1个小时。领导对我们解决问题的速度和专业性提出了肯定。而这个过程中,美信CreCloud云网管这种高效的工作机制和准确简单的图表可以说是功不可没。通过美信CreCloud云网管的图表数据,我们和业务部门找到一种更快捷也更准确的沟通方式。







