2012年4月11日、12日,IDF(英特尔信息技术峰会)在北京国家饭店隆重举行。本届IDF以“引领潮流,直面未来”为主题。
英特尔在高性能计算的目标是在2018年实现“百亿亿次浮点运算”,然而,在实现“百亿亿次”的途中,在计算性能、能耗、可靠性等方面仍然面临着一些技术壁垒。在IDF2012的技术课程中,来自英特尔的首席服务器平台架构师Faye A Briggs博士介绍了《面向百万万亿次级计算的英特尔架构发展方向》。【更多精彩内容:DOIT IDF2012专题报道】

图1 英特尔的首席服务器平台架构师Faye A Briggs博士
“为了更加逼真的模拟现实生活中的问题,英特尔的目标是在2018年创造出世界第一台ExaFlops(10的18次方)计算机,功耗在20-40MW之间。”Faye表示,要实现这一目标,还有许多问题需要解决,需要在微处理器、内存、能耗、可靠性和弹性、并行计算和互连等方面的技术有很大的突破。
百亿亿次浮点运算面临的五大挑战
计算性能:核数和IPC是主要的性能提升因素,但是对于高性能计算来说,内存带宽也是显著因素之一。
内存:内存方面的技术挑战包括Byte/Flop比、成本/面积、功耗和并行程度等方面。
能耗:随着计算能力的不断增强,能耗已经成为高性能计算的首要问题。对于百亿亿次的浮点运算目标而言,能耗问题更是不言而喻。对于超级计算机的能耗而言,通常使用pJ/Op指标来衡量,也就是说每单位浮点运算所需要的能耗,数量越小,表示HPC系统的能耗越理想。要实现百亿亿次超级计算系统,能耗指标需要降低到10pJ/Op,这是当前情况的30—60分之一。
可靠性和弹性:高性能计算的可靠性一直以来都是一个最根本的问题,这也是高性能计算的应用对于计算平台所提出来的需求。如何增加DRAM的芯片数量?如何降低每插槽每年的失效次数,以确保在插槽数不断增加的情况下整个系统的可靠性?这些都是百亿亿次运算所需要考虑的问题。
并行软件:当然,在强大的计算能力,归根结底是为了满足人类的需求,这必须要通过高性能计算的软件来实现。随着计算架构的不断扩大,如何编写出MIC架构下的并行软件?如何保证之前的基于至强平台的软件能够在MIC架构上运行?这也是一个需要解决的问题。
英特尔百亿亿次的思路展望
事实上,在上述挑战中,性能与能耗是一个天生的矛盾体。百亿亿次以为这性能的提升,而如何在性能提升的同时,这才是解决问题的关键。在课程中,Faye介绍了他的一些新的想法,解决上述的挑战。
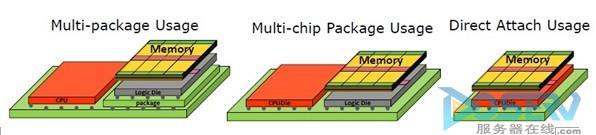
多层内存技术:对于高性能计算来说,内存带宽也是显著因素之一。GDDR已经显得力不从心,需要一种全新的内存架构来解决性能与能耗之间的矛盾。英特尔提出多层内存技术(如下图所示),这或许是未来内存技术发展的一个新的方向。
Cache:对于多数HPC应用来说,大Cache能够带来性能的提升,还能避免内存到Cache的频繁访问,从而降低能耗。MPKI(Miss Per Thousand Instructions,每千条指令指令的未命中次数)分析表示:当Cache大小在1MB-4MB的时候,MPKI值最小。并且,统计学的结果显示,L2 Cache的命中率为11%的时候,达到最优值。
基于MIC架构的两大开发工具集:英特尔提供了Parallel Studio和Cluster Studio两个开发工具集(如下图所示),分别用于编写基于MIC架构的优化的程序和分布式的程序。

Faye表示,只有上述问题全部得到解决,才能真正迈向百亿亿次架构。英特尔究竟能否按照预期,在2018年实现百亿亿次运算?让我们拭目以待吧。