2012年4月11日、12日,IDF(英特尔信息技术峰会)在北京国家饭店隆重举行。本届IDF以“引领潮流,直面未来”为主题。
Intel Advanced Vector Extensions (Intel AVX)是在之前的128bit扩展到和256bit的SIMD(Single Instruction, Multiple Data)。在IDF下午的技术课程中,来自英特尔的专家介绍了下一代AVX指令集——AVX 2.0。【更多精彩内容:DOIT IDF2012专题报道】
AVX 2.0将用于预计在2013年推出的Haswell处理器,Haswell在制程工艺上与Ivy Bridge一样,都是22nm制程工艺,但是Haswell将采用不同的架构。AVX 2.0将会扩展到256位整数,并加入离散数据加载指令。
AVX2.0并未引入新的寄存器,使用的同样是16个寄存器。但是下列6方面的创新将会进一步推动向量运算的发展:
256位整数:这是AVX2.0一个重要的变化。
跨通道的混选指令:之前SSE的时候,很多整数指令都可以无缝地迁移到AVX2.0。AVX1.0和SSE基本上只能做同一通道拿数据,2.0实现低通道可以从高通道拿数据。

跨通道的混选指令,由上图可见,AVX2.0中可以实现任何位置见的混选
可变的移位操作:每一个元素对应不同的移位控制数,使得每一个元素可以实现移动不同的位数。共有三种移位指令,包括逻辑左移、逻辑右移和算术右移(算术左移与逻辑左移完全一样)。

新的广播操作:256位寄存器中可以放8个浮点数,有时,程序员希望把8个浮点数复制成同一个数,可以使用数组、排列、混合指令等操作实现,但是现在有了广播指令,只需要一条指令就可以实现。事实上,AVX1.0就有广播操作,只支持内存和寄存器,现在数据既可以放内存又可以放寄存器。
加载离散数据:数据放在内存中可能不是连续的,通过AVX2.0可以把离散数据集中起来,避免了矢量化。加载离散数据操作既支持整数又支持浮点数。
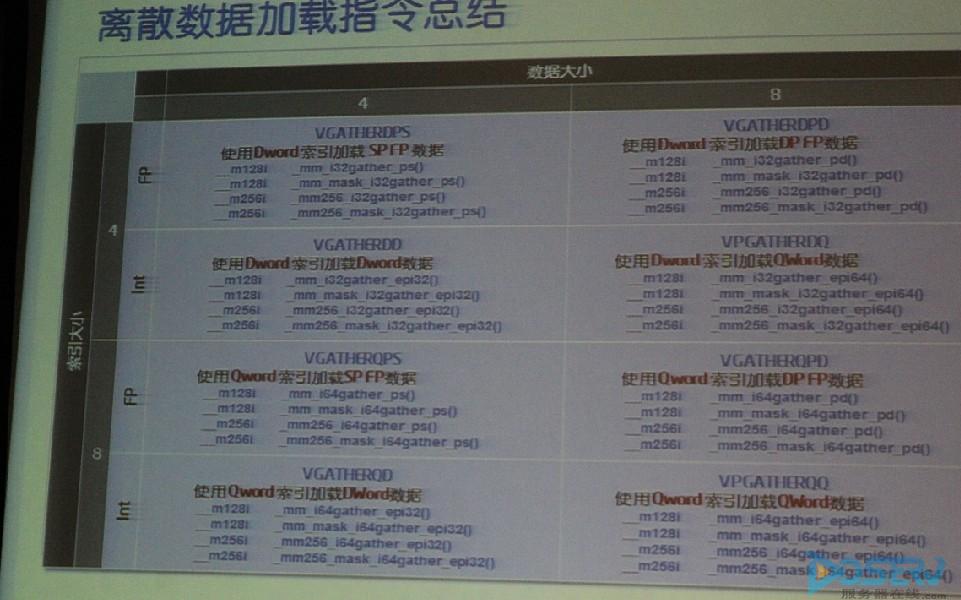
乘加融合指令:完成(axb)+/-c只需一条指令,并且,-axb的中间结果在做加减之前不会进行舍入,这样既提高了计算速度又提高了计算精度。乘加融合之灵对于矩阵乘法、点乘和多项式求和等运算十分有用。