
6月18日,第39届全球高性能计算机TOP500公布,设在美国加州劳伦斯利弗莫尔国家实验室的“红杉”超级计算机以每秒16.32千万亿次的计算能力折桂。中国的“天河一号”和“星云”分别为列第五和第十。
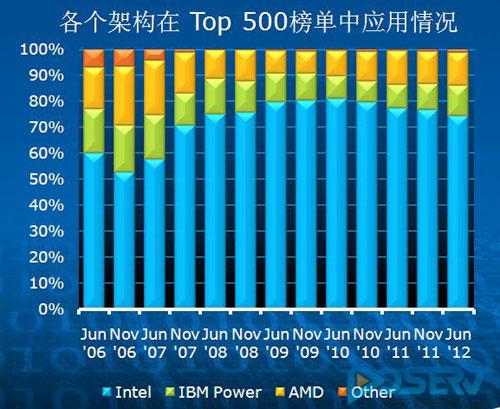
然而,纵观本届TOP500榜单,最大的赢家依然是英特尔。在全球最快的500台超级计算机中,共有372套系统采用了英特尔处理器,这个比例超过了74%。而即使是新入榜的系统,采用英特尔处理器的系统占据了超过78%的份额。这意味着未来英特尔在TOP500中的份额还会有所提升。

令人惊叹的是,尽管英特尔至强E5处理器问世才3个月,但本次TOP500中已有多达45套基于E5处理器的系统入榜,其中包括3套拥有每秒千万亿次浮点计算能力的系统。
此外,英特尔还在国际超级计算大会上宣布未来所有基于英特尔集成众核架构(英特尔MIC 架构)的产品将采用全新品牌——英特尔至强融核(Intel Xeon Phi)。英特尔(中国)有限公司服务器平台产品经理张振宇透露,第一代英特尔至强融核产品家族(代号为“Knights Corner”的协处理器)将于 2012 年年底推出,届时它将成为英特尔至强处理器E5-2600/4600产品家族的重要补充,并为高度并行的工作负载带来全新性能。
至强E5为高性能计算而生
英特尔至强E5在本届TOP500中的表现,除了45套系统入围外,更是夺得了第四名的佳绩。
位于德国莱布尼茨超级计算中心(LRZ)的“SuperMUC”,达到每秒2900万亿次浮点计算的的计算能力,是当前欧洲计算能力最强的高性能计算机,也是目前基于英特尔至强处理器E5产品家族的最大的高性能计算机,在本届榜单上排名第四。
回首全球高性能计算机的发展之路,1997年当时最快的计算机叫“ASCI RED”,其运行速度仅为1TFLOP,当时一个放20台2路服务器的机柜,其典型的计算能力是0.5GFLOP。到2012年6月,最快的IBM的“红杉”达到了16PFLOP。目前,一个20千瓦标准机柜能提供高达5TFLOP的计算能力。而到2018年,业内最快的计算机将达到百亿亿次级别,届时一个20千瓦标准机柜就能提供0.5到1PFLOP的计算能力。“在1997年我们需要用16万个标准机柜才能达到80TFLOP的计算能力,现在用至强处理器的服务器仅需16个机柜就能实现了。”张振宇说,“处理器以及相关技术的发展,使得人类的计算能力日新月异。”
作为高性能计算的上游和领导厂商,英特尔一直在致力于提供更快更高能效的高性能计算机。2012年3月,英特尔推出了至强E5-2600处理器,采用Sandy-Bridge架构的英特尔至强E5更是为高性能计算增添了新的动力。
首先,至强E5具有8个核心,相比上一代的至强5600多出两个内核,具备20MB L3缓存,平均每核心2.5MB,这比上一代的每核心2MB要多25%,核心和缓存的增强对计算能力的提升明显。因而至强E5在性能上比上一代的至强5600有80%的性能提升。

其次,至强E5在带宽方面采用了环形链路总线,提升了带宽降低了延迟。在QPI总线上,至强E5具备两条最高8GT/s的QPI,相比至强5600家族每条链接带宽增加了25%;在内存支持上,至强E5具有四个内存通道,内存规格支持也提升到了DDR3-1600,而至强5600最高支持DDR3-1333。从这些规格来看,E5在数据带宽上要明显领先于至强5600,更加适合HPC苛求高带宽的应用。
第三,至强E5还引入了专门针对HPC应用的AVX高级向量扩展指令集,来加强浮点运算性能。AVX指令集将现存的浮点向量指令从128位扩展到256位,这种改进可以让每核每时钟浮点运算峰值翻倍。英特尔认为,AVX技术是加大计算密度的起点。
此外,英特尔还发布了至强E5-4600,这是针对紧凑型4路服务器的新平台。至强E5-4600能在单个系统中最多可提供32个内核和48个DIMM,适用于诸如科学研究和金融服务等各种广泛的技术计算应用,适合做大规模集群的“胖”节点使用。
众核进入倒计时
英特尔在高性能计算的另一利器——集成众核架构(MIC)处理器亦将进入倒计时。在国际超级计算大会上, 英特尔公司宣布未来所有集成众核架构产品将采用全新品牌——英特尔至强融核。同时第一代英特尔至强融核产品家族(代号为“ Knights Corner”的协处理器)将于 2012 年年底推出,届时它将成为英特尔至强处理器 E5-2600/4600 产品家族的重要补充,并为高度并行的工作负载带来全新性能。英特尔(中国)有限公司服务器平台产品经理张振宇透露,至强融核第一代产品将主要用于高性能计算( HPC)市场,而未来的英特尔至强融核产品还将满足企业数据中心和工作站的需求。
为了加深用户对至强融核系统的了解和认知,英特尔还搭建了首个基于至强融核协处理器的集群并投入了使用,该系统目前在本届TOP500榜单上位列第150位,它具备了每秒118万亿次浮点计算的性能。
张振宇介绍,至强融核处理器具备出色的易用性,能够充分利用在英特尔架构上使用的常见编程模式、技术和开发者工具。由于它能够更充分地利用并行 CPU 代码,软件公司和 IT 部门将无需重新为其开发人员提供与加速器有关的专用编程模型的培训。除了兼容 x86 编程模式外,英特尔至强融核协处理器还能够适用于专为高性能计算优化且高度并行的独立计算节点。它可以独立于主机操作系统来运行自己的基于Linux的操作系统。这一特性将可以为实施无法采用其它 GPU 技术的集群解决方案带来更大的灵活性。

具体规格和技术细节方面,首个英特尔至强融核协处理器将采用22 纳米3-D三栅极晶体管制程技术,可在 PCI-e插卡形态下集成超过 50 颗内核和支持最低 8GB容量的GDDR5 内存。此外,它还具备支持512b SIMD 指令的特点,可在单个指令控制下同时处理多个数据元素,从而能显著提升性能。
从去年开始,英特尔还在全球范围内精心挑选了100家企业和科研单位,开始对“ Knights Corner”进行测试和试用,其中中国的企业有6家,涵盖了石油、互联网等领域。英特尔工程师正帮助他们将应用移植到MIC上,因而张振宇认为,到今年年底有可能出现真正的集成众核系统。

此外,英特尔至强融核协处理器还获得了广泛的行业支持,包括 Bull、Cray、戴尔、惠普、IBM、浪潮和NEC在内的44家制造商已承诺将推出采用该款协处理器的系统。
向百亿亿次进军
英特尔在高性能计算领域的目标,就是到2018年向全球提供每秒浮点计算能力达百亿亿次的超级计算机,为此英特尔正朝着这个目标不断努力。
张振宇表示,目前在推动千万亿次向百亿亿次级的过程当中,至强扮演着非常重要的角色,它本身是非常强大的平台,最重要是能够适应各种各样的工作负载。但到百亿亿次的发展阶段仅仅靠至强是不够的。需要用众核架构来提供高度定型应用的效率,提高计算效率。
张振宇透露,首个搭配采用英特尔至强E5处理器和至强融核协处理器的千万亿级(可实现每秒千万亿次浮点计算能力)的高性能计算机将于 2013 年年初推出,并将命名为“Stampede”。英特尔预计在英特尔至强融核协处理器的可编程性和卓越性能的支持下,明年还将会有大量千万亿级的系统涌现。

为了实现到2018年达到百亿亿级计算目标的承诺,英特尔还在多个领域进行了大量投资,旨在满足未来对于庞大性能的需求。英特尔最近收购了Qlogic的Infiniband业务和Cray的互连技术,以进一步在此基础上创新,消除在未来提供可扩展的百亿亿次级计算平台所面临的障碍。







