
现在Hadoop已经发展成为包含多个子项目的集合。虽然其核心内容是MapReduce和Hadoop分布式文件系统(HDFS),但 Hadoop下的Common、Avro、Chukwa、Hive、HBase等子项目也是不可或缺的。它们提供了互补性服务或在核心层上提供了更高层的服务。图1-1展现了Hadoop的项目结构图。
下面将对Hadoop的各个子项目进行更详细的介绍。
1)Core/Common:从Hadoop 0.20版本开始,Hadoop Core项目便更名为Common。Common是为Hadoop其他子项目提供支持的常用工具,它主要包括FileSystem、RPC和串行化库,它们为在廉价的硬件上搭建云计算环境提供基本的服务,并且为运行在该运平台上的软件开发提供了所需的API。
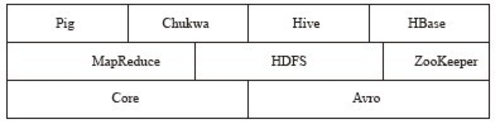
▲图1-1 Hadoop的项目结构图
2)Avro:Avro是用于数据序列化的系统。它提供了丰富的数据结构类型、快速可压缩的二进制数据格式、存储持久性数据的文件集、远程调用RPC的功能和简单的动态语言集成功能。其中,代码生成器既不需要读写文件数据,也不需要使用或实现RPC协议,它只是一个可选的对静态类型语言的实现。
Avro系统依赖于模式(Schema),Avro数据的读和写是在模式之下完成的。这样就可以减少写入数据的开销,提高序列化的速度并缩减其大小。同时,也可以方便动态脚本语言的使用,因为数据连同其模式都是自描述的。
在RPC中,Avro系统的客户端和服务端通过握手协议进行模式的交换。因此当客户端和服务端拥有彼此全部的模式时,不同模式下的相同命名字段、丢失字段和附加字段等信息的一致性问题就得到了很好的解决。
3)MapReduce:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。“映射”(map)、“化简” (reduce)等概念和它们的主要思想都是从函数式编程语言中借来的。它使得编程人员在不了解分布式并行编程的情况下也能方便地将自己的程序运行在分布式系统上。MapReduce在执行时先指定一个map(映射)函数,把输入键值对映射成一组新的键值对,经过一定的处理后交给 reduce,reduce对相同key下的所有value进行处理后再输出键值对作为最终的结果。
图1-2是MapReduce的任务处理流程图,它展示了MapReduce程序将输入划分到不同的map上,再将map的结果合并到reduce,然后进行处理的输出过程。
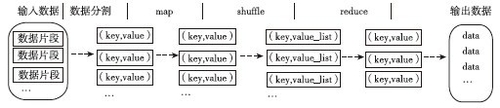
▲图1-2 MapReduce的任务处理流程图
4)HDFS:是一个分布式文件系统。由于HDFS具有高容错性(fault-tolerant)的特点,所以可以设计部署在低廉(low-cost) 的硬件上。它可以通过提供高吞吐率(high throughput)来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了可移植操作系统接口(POSIX,Portable Operating System Interface)的要求,这样就可以实现以流的形式访问文件系统中的数据。HDFS原本是开源的Apache项目Nutch的基础结构,最后它成为了Hadoop的基础架构之一。
以下是HDFS的设计目标:
检测和快速恢复硬件故障。硬件故障是常见的问题,整个HDFS系统由数百台或数千台存储着数据文件的服务器组成,而如此多的服务器意味着高故障率,因此,故障的检测和自动快速恢复是HDFS的一个核心目标。
流式的数据访问。HDFS使应用程序能流式地访问它们的数据集。HDFS被设计成适合进行批量处理,而不是用户交互式的处理。所以它重视数据吞吐量,而不是数据访问的反应速度。
简化一致性模型。大部分的HDFS程序操作文件时需要一次写入,多次读取。一个文件一旦经过创建、写入、关闭之后就不需要修改了,从而简化了数据一致性问题和高吞吐量的数据访问问题。
通信协议。所有的通信协议都在TCP/IP协议之上。一个客户端和明确配置了端口的名字节点(NameNode)建立连接之后,它和名称节点 (NameNode)的协议便是客户端协议(Client Protocal)。数据节点(DataNode)和名字节点(NameNode)之间则用数据节点协议(DataNode Protocal)。
5)Chukwa:Chukwa是开源的数据收集系统,用于监控和分析大型分布式系统的数据。Chukwa是在Hadoop的HDFS和 MapReduce框架之上搭建的,它同时继承了Hadoop的可扩展性和健壮性。Chukwa通过HDFS来存储数据,并依赖于MapReduce任务处理数据。Chukwa中也附带了灵活且强大的工具,用于显示、监视和分析数据结果,以便更好地利用所收集的数据。
6)Hive:Hive最早是由Facebook设计的,是一个建立在Hadoop基础之上的数据仓库,它提供了一些用于数据整理、特殊查询和分析存储在 Hadoop文件中的数据集的工具。Hive提供的是一种结构化数据的机制,它支持类似于传统RDBMS中的SQL语言来帮助那些熟悉SQL的用户查询 Hadoop中的数据,该查询语言称为Hive QL。与此同时,那些传统的MapReduce编程人员也可以在Mapper或Reducer中通过Hive QL查询数据。Hive编译器会把Hive QL编译成一组MapReduce任务,从而方便MapReduce编程人员进行Hadoop应用的开发。
7)HBase:HBase是一个分布式的、面向列的开源数据库,该技术来源于Google的论文“Bigtable:一个结构化数据的分布式存储系统”。如同Bigtable利用了Google文件系统(Google File System)提供的分布式数据存储方式一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Hadoop 项目的子项目。HBase不同于一般的关系数据库,其一,HBase是一个适合于存储非结构化数据的数据库;其二,HBase是基于列而不是基于行的模式。HBase和Bigtable使用相同的数据模型。用户将数据存储在一个表里,一个数据行拥有一个可选择的键和任意数量的列。由于HBase表示疏松的,用户可以给行定义各种不同的列。HBase主要用于需要随机访问、实时读写的大数据(Big Data)。
8)Pig:Pig是一个对大型数据集进行分析和评估的平台。Pig最突出的优势是它的结构能够经受住高度并行化的检验,这个特性让它能够处理大型的数据集。目前,Pig的底层由一个编译器组成,它在运行的时候会产生一些MapReduce程序序列,Pig的语言层由一种叫做Pig Latin的正文型语言组成。
作者简介
陆嘉恒,《Hadoop实战》作者,中国人民大学副教授,新加坡国立大学博士,美国加利福尼亚大学尔湾分校(University of California, Irvine) 博士后。







