
EMC在2012年5月10日收购了闪存阵列制造商XtremIO。全闪存,听起来就很带劲,在性能上一定非常强悍。那XtremIO是否就是插满SSD的传统存储?如果是这样,EMC把自家存储上的机械硬盘全部换成SSD不也就成了“全闪”嘛,为什么还要大费周章花钱特意去买一家公司?今天我从性能的角度浅谈一下这个问题。
为什么传统存储设计不适合承载”ALL SSD”?
磁盘阵列的根本依然是基于硬盘的,硬盘的特点就是存在moving parts,所以特别讨厌random I/O,因为过多的seek影响性能。因此,对于基于硬盘的阵列,设计者一开始的想法就是尽可能的让阵列处理sequential I/O。一个简单的例子就是用Cache!思路就是先将incoming I/O囤积在Cache,然后通过Coalescing尽可能将【地址临近的I/O】合并以sequential的方式写入磁盘,减少seek带来的delay。
再来看控制器,有试过把你目前存储上的硬盘全部换成等额数量的SSD(假设有一定数量规模)并以给定的压力来测试性能吗?我相信CPU很快就会100% UT -> system down,why? 因为原本瓶颈就不是CPU,而是磁盘,在保证磁盘不过载的前提下,如此数量的硬盘不足以榨干CPU的性能,但换成等额数量的SSD后,SSD IOPS burst,不等你榨干SSD的性能,CPU就几近崩溃了。另外,我对传统硬盘存储的PCIe bus & SAS backend bus的带宽也表示“亚历山大”。打个不恰当的比喻,想象一下日本海堤之前是如何被虐的,号称世界最牛的海岸防线对付小型海啸还凑合,来个怪兽级别的基本就被秒了,因为在设计上根本无法抵抗。归根结底,如果你用favoring sequential I/O的系统来host favoring random read I/O的SSD,那么所有这些设计优化对于SSD来讲,相关性是很小,这种mismatch的结果一定不会如你预期的那么好。
所以系统需要redesign,无论是硬件还是软件架构,必须rebuild,为SSD专门设计。XtremI/O看到了这个市场机遇,所以造了台机器,然后EMC就给收了。性能只是系统需要重新构建的考虑因素之一,其它存储系统功能,比如快照、克隆、去重、精简资源调配和复制原本也都是基于底层磁盘管理引擎所构建的,采用同样的规则和限制,而且favoring sequential I/O。虽然为传统存储插满SSD不会破坏这些功能,但你同样看不到给它们带来的增强。
一句话,新系统的设计要符合SSD的胃口,而SSD的特质就是random access without performance penalty。
为什么全闪存存储会有市场?
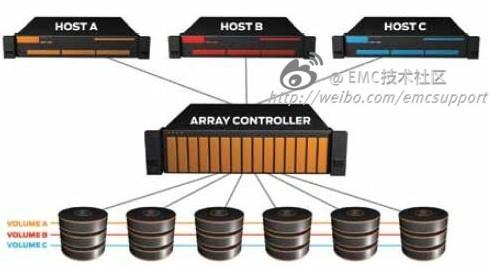
这个标题有点废话,“全闪”当然是因为性能好,不差钱又对性能要求极高的客户大有人在。不过我们是做技术的,再稍微深入一下。一台存储通常需要连接许多服务器,很多时候一个LUN并不是给单个App使用的,在这种情况下,即便多个App本身是Sequential I/O,但当多个sequential data stream冲向同一个LUN,最终存储看到的都是random I/O。虽然存储设计为尽可能对后端磁盘做sequential I/O,但我可以告诉你,在大量datastream冲向同一个LUN的时候,sequential I/O是不可能的。这种情况称为I/O Randomization。下图是以前最为常见的服务器使用存储的方式,为什么说“以前”?因为现在是Virtualization的天下。
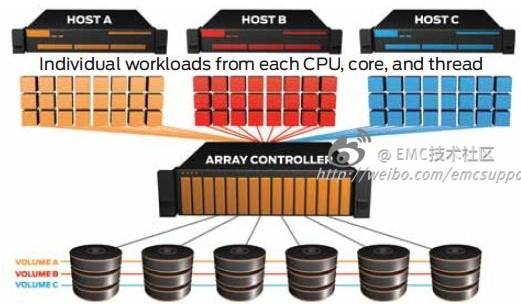
如果三个data stream还不够多的话,那是什么加速了data stream的增加?一个最直接的答案就是:more CPU power + Virtualization -> increased VM density -> more pressure on storage -> I/O Blender
我来解释一下上面的这段话。CPU原本是通过增加晶体管和时钟频率来提升性能的,但近年来的一个转变是【multi-core + multithreading】,这本身就助长了I/O Randomization。考虑这样一个服务器配置【dual socket, 6 cores/socket, 2 threads/core】 -> 2*6*2 = 24 unique data streams。如此强悍的服务器只承载单个App是否过于浪费了(Map-Reduce style data-intensive workload除外)?所以越来越的企业采用Server Virtualization来host multi-VM,这再一次加剧了I/O Randomization。如果多台这样的物理服务器连接同一台存储,来自成百上千的混合流量立刻会使得存储的workload变得completely random,这就是所谓的I/O Blender。
再简单一点,Massive Consolidation + Intensive Randomization -> I/O Blender。下图是我们目前服务器使用存储的常见情况,虽然服务器依旧只有三台,但对于存储来说,已不仅仅是三个workload,而是一堆。
所以I/O Blender给尽可能顺序化I/O的设计初衷带来了挑战,但人类总喜欢master complexity,所以会继续面对挑战,目前的对策有如下这些:
增加存储缓存容量:支持TB级别的缓存对于企业级存储来讲已经不稀奇了,更大的Cache加大了聚合分散随机I/O的可能性。缺点也显而易见,cache memory贵啊,而且read performance依然是个问题,random reads导致cache miss,从而不得不访问后端磁盘。
把流量分散到更多的磁盘:如果workload越来越随机化,那么我们就需要更多的盘来增加IOPS。缺点也很多,cost + space + power consumption + inefficient capacity UT,而且东西多了,规划自然也就更复杂。
添加flash tier or flash cache:添加SSD的确加速了性能,不过本质问题依旧,设计不匹配,SSD一不小心就会overload整个存储,适得其反。值得注意的是,用于cache之后,flash将经常遭遇write cycle(promotion <->write back),所以需要耐久度(endurance)更高的SLC闪存。另外,caching和tiering的效率取决于App,即便只有10%的I/O go to backend disk,App的serialization transaction通常都会受到响应时间的限制。所以要维持一个始终可预测的高性能对于caching/tiering这种方案来说并不总是可行的。
不错,你可以通过这些方案来应对I/O Blender,但CPU性能的增长势头也预示着海啸般的流量冲垮caching/tiering是迟早的事情,大量的活跃数据要求more memory + more flash as cache,要知道这种无限增长是不可能的。再者,即便前边的caching/tiering防线守住了,为机械硬盘所设计的控制器可能根本挡不住这么大的流量,这也是为什么我们在VNX/CLARiiON上会考虑如何不让FAST Cache冲垮CPU和backend bus的问题了(虽然VNX SAS的24Gbps后端抵抗力要强很多)。
其实很多问题都是相同的,一种架构不可能服务到永远,master complexity也只会导致更为复杂的系统,带来新的问题。解决方案只有一个,推到重来。最近SDN的概念其实如出一辙,Internet架构是几十年前的设计了,之所以还能建在是因为人类的伟大,无数牛人绞尽脑汁来master complexity,是时候back to simplicity了。







