
Intel Tick-Tock策略已经进行了好几年,而且会在未来继续贯彻下去,无论服务器、桌面还是移动领域。德国网站ComputerBase.de今天曝光了 一份路线图,显示了Intel 2012-2018年间的服务器架构、工艺路线图,这也是我们第一次能够提前如此长的时间看到如此清晰的规划。
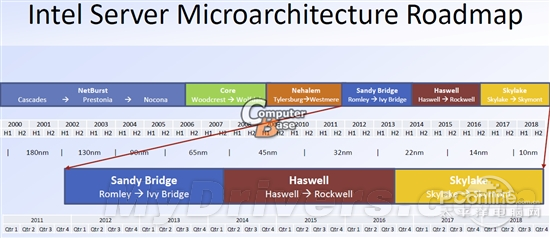
需要特别注意的是,这份路线图展示的服务器产品规划,和桌面上并不完全同步。一般来说,Intel的新工艺、新架构都是首先用在桌面领域,移动领域基本同时或者稍晚一些,而服务器领域则要延后很长一段时间,而且不同定位的系列产品也有很大差异。
Intel目前已经进入32nm工艺的鼎盛时期,服务器架构正在从上代Westmere向新的Sandy Bridge过渡,接下来就是22nm新工艺的改进版Ivy Bridge,以及未来的10nm Skymont。下面我们就来一起梳理一下Intel服务器架构这些年的发展路线。
Intel 65nm Core
因为市场需求,Intel高性能处理器产品线转移。

停产的“扣肉”
早在2008年65nm Core就已经陆续停产,在此我们就不做过多赘述了。
Intel 45nm Penryn
Penryn核心
45nm的Penryn虽然同样标示为65W TDP,在同一功耗下Penryn的性能将比65nm的Core更佳,全因Penryn核心频率将会由3GHz起跳,双核心将会拥有3MB及6MB :2版本,四核心则最高可达至12MB L2容量,虽然L2增加了,但由于采用上45纳米,Wolfdale Die Size只有107平方毫米,相比上代Conroe的143平方毫米减少约25%,令成本进一步下降。

在电源管理方面,Intel在下一代Penryn微架构加入全新的power state,称为Deep Down Power State。加上新的power state后,Penryn的C-State将增至五个。C0为正常状态,C2、C3及C4则为不同的省电模式。新增的Deep Down (C6)与C4模式类近,除关闭核心频率、PLL及消除Cache外,在Deep Down模式下,整个Cache亦将会被关闭以达到更佳的省电效果。与C4相较,据称 Deep Down耗电量将可减少达300%。
在下一代Penryn微架构中,Intel亦首次加入全新Intel Dynamic Acceleration(IDA)单线程加速技术于桌面处理器上,令系统在运作单线或串行多线程程序时,可提供自动超频作运算,而另一颗则进入闲置状态。
当双核心处理器运作单线或串行行线程程序时,当中只有一颗核心是处于运算状态,而另一颗只会处于闲置(C3或更高的省电模式)时, IDA技术则可以在系统只需要运作一组串行的程序时,把运算中的核心的频率提高,令系统可以提早完成这一组串行程序,而另一颗核心仍然保持闲置状态。
虽然其中一颗核心频率被自动超频,但由于另一颗核心处于省电的C3或更高的闲置状态,因此处理器的最高功耗指不会因IDA技术而被提高,在不用增加成本的情况下,用家可获得更优秀的单线程运算效果。
>>
Intel 45nm Nehalem
Nehalem处理器同样上一代的 Penryn至强一样,都是采用了45nm的生产工艺,它属于第二代的45nm产品,但它却和上一代产品有着很大的区别。简单说来,Nehalem还是基 本建立在Core微架构(Core Microarchitecture)的基础上,外加增添了SMT、3层Cache、TLB和分支预测的等级化、IMC、QPI和支持DDR3等技术。

45nm晶圆
Intelligent Performance 超强的性能
首先,XEON 5500系列集成内存控制器(IMC),说到这里,我们不得不把时间拉回到XEON 5300系列的时代,由于其竞争对手AMD在其K8架构时代,就集成了内存控制器,正因为如此,这大大的提升了AMD处理器的性能,这也成了AMD骄傲的 资本,再来看看intel,CPU访问内存的延迟,大大的影响了XEOn产品的性能,所以在XEON 5400时代,intel开发了一种高速全缓冲内存技术,就是我们通常说的Fully-buffer DIMM,他是在内存上面加载了一个处理芯片,来提高与CPU交换的速度,从实际情况来看,这确实为解决之法,但是,从另外的技术方面,我都为intel 捏了一把汗,这为治标不治本。从各大OEM厂商和使用者的回馈反应来分析:FBD内存发热量大,为此还穿上了金属的马甲,功耗也比REG ECC内存高出许多。
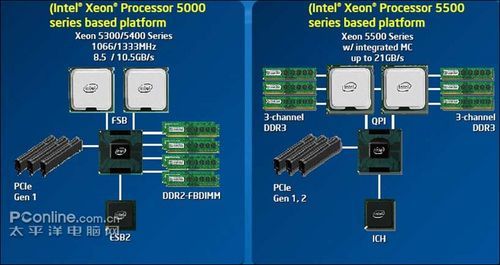
集成内存控制器
其次是超线程技术,超线程技术是在一颗CPU同时执行多个程序而共同分享一颗CPU的资源,理论上要像两颗CPU一样在同一时间执行两个线程,处理器需 要多加入一个Logical CPU Pointer(逻辑处理单元)。而其余部分如ALU(整数运算单元)、FPU(浮点运算单元)、L2 Cache(二级缓存)则保持不变,这些部分是被分享的。
虽然采用超线程技术能同时执行两个线程,但它并不象两个真正的CPU那样,每各CPU都具有独立的资源。当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续。因此超线程的性能并不等于两颗CPU的性能。
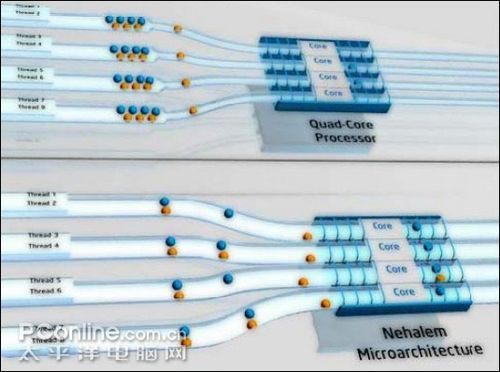
超线程技术
需要注意的是,含有超线程技术的CPU需要芯片组、软件支持,才能比较理想的发挥该项技术的优势。
再次是XEON的自动超频,Turbo Boost,(也叫涡轮推进技术),很多时候,CPU在处理数据或者在运行的时候,都达到了100% 的使用率,为了解决这个问题,在新一代的XEOn处理器中,可以自动实现2级超频功能,从原来频率基础上,增加2个133M的频率。
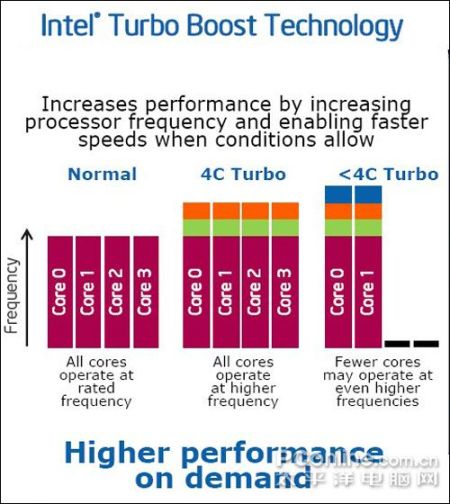
自动超频Turbo Boost
不过,并不是所有的XEON都会支持这个功能,例如面对低端市场的XEON 5502和XEON5504,这两个型号的CPU,也将会有可能只有2个核心的版本,共享了4M二级缓存,也不支持超线程技术,从这方面来看,intel 把改省的都省下了,呵呵。从中端的XEON E5506,到XEON E5540都支持了Turbo Boost。不同的是高功耗版本的XEON X5550,功耗达到了95W,它可以在使用2个核心的情况下,实现3级超频功能,也就是133M×3。例如XEON X5570本来频率是2.93G,如果四个核心同时使用,那么每个核心可以自动超频到3.2G;如果只使用了2个核心,那么这2个核心可以自动超频到 3.33G运行。
Automated Energy Efficiency 自动化能源控制
在XEON5500以前,通常情况下,一个企业使用的服务器都 是全天24小时运行,功耗基本上都是满负荷状态运行,在我们提倡节约能源的今天,这是一个巨大的浪费。不过,从这一代开始,处理器更加智能,能够根据使用 时的状态,自动调节功耗。下面是一个企业一天中监测服务器的功耗情况图,可以看出在早上7点以前,晚上8点以后,功耗大大降低,为企业节省了不少的开支。
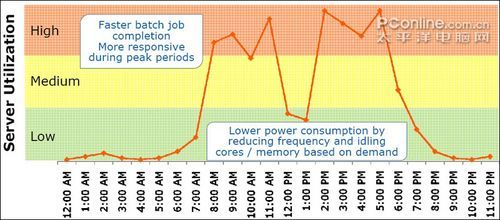
不同时段服务器的功耗并不相同
XEON 5400和XEON5500的对比情况:SPECpower_ssj2008是一个利用标准Java的JDK计算整体服务器性能,根据其中11个不同工作 负载区域段的功耗得出服务器的工作负载/能耗比的测试方式。是一个较为客观的服务器的能耗标准:简单说来,这一切只与服务器的节能设计有关,也就是 XEON5500的自动能源控制。
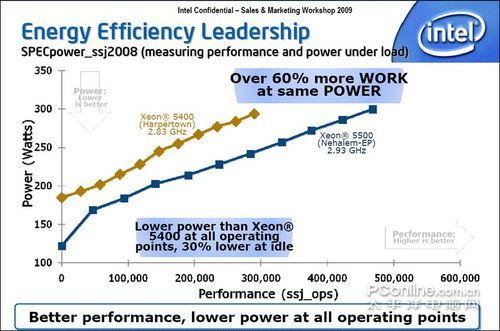
Nehalem架构的至强服务器明显在节能方面有更好的表现
Flexible Virtualization 灵活的虚拟化技术
除此之外,英特尔还在强化了Flex-Magretion虚拟化技术。这一技术虽然在在Penryn里就已经实现,但是英特尔在XEON5500里得到 了加强。相较于之前的英特尔VT技术,FlexMigration则更偏向传统对虚拟化技术的定义,这种技术可以让虚拟机上的应用在英特尔不同产品线的处 理器上进行动态迁移,提高处理器使用率。新一代的XEON5500 平台上,包括了chipset芯片,还有network,都对虚拟化有了良好的支持,这使得整个服务器性能有了巨大的提升。>>
Intel 32nm Westmere
Westmere-EP采了 32纳米第二代high-k金属栅技术,先进的制程工艺使得Westmere-EP具备更多的处理核心抑或在保持同样TDP封装前提下提高处理器的主频。 鉴于Thermal Police(热量排放政策)的缘故,处理器的主频都有所限制,英特尔计划为Westmere-EP增加更多的处理核心以及缓存。
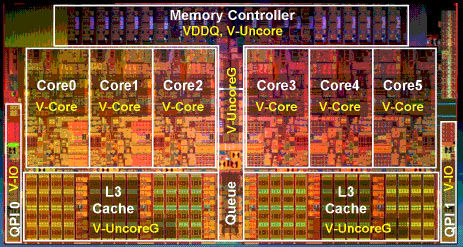
Westmere-EP芯片结构
具体而言,45纳米向32纳米的进步,使得Westmere-EP能增加两个处理核心并且每个核心的三级缓存也增长了50%达到12MB之多。英特尔架 构事业部资深高级工程师Nasser Kurd确认Westmere-EP将支持Turbo Boost特性(智能加速技术),即在芯片其他芯片元素静默状态下小幅提高处理器核心的主频。
总体而言,Westmere-EP的主频和热封装范围同现有的至强5500一样,此外在处理器插槽、主板芯片组和DDR3内存的支持方面也同至强5500一样,每个插槽都有着三个内存通道。
六核Westmere-EP处理器有着11.7亿个晶体管,芯片面积为为240平方毫米。正如上图所示,六个处理核心被一分为二,每组三个核心。处理核 心区域有着专门的时钟频率和电源供给,三级缓存和内存控制器在优化设计之后归为“uncore”(非核心)区域,有着独立的功率门限(power gating)。在Nehalem家族芯片中,英特尔为每个核心的晶体管引入了功率门限,当核心处于闲置状态时就会被自动关闭。核心状态存储于芯片缓存 中,但是非核心区域依旧保持全功率运行。但是在Westmere家族中,非核心区域也引入了功率门限,由此可以看出Westmere更加绿色节能。
Westmere-EP芯片保持了英特尔HyperThreading同步多线程特性,每一个核心都有着两个虚拟线程,此外Westmere还具备新的 加密指令集在加密解密数据之时实现AES算法。另外一个新特性在于其嵌入式的内存控制器能够支持低压的DDR3内存,这样在无需损失性能的前提下能够减少 20%的热量。
Intel 32nm Sandy Bridge
随着钟摆的又一次摆动,时间跨入了2011年。这将是制程-架构的又一次转换,2011年英特尔的Tick-Tock发展战略迎来了Sandy Bridge架构年的到来。桌面以及移动版的Sandy Bridge已经面世,服务器领域的至强版本也将在稍后登场。
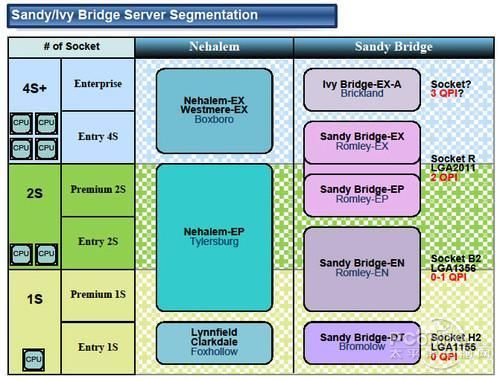
与上一代架构各产品线相对应的Sandy bridge家族产品
从产品定位看
与现有至强产品线3000、5000、7000系不同,新一代Sandy Bridge产品线将划分的更为明确。过去一路产品线由至强3000系独占,而现在将被细化为面向入门级一路产品的Sandy Bridge-DT和主流一路/入门级两路产品Sandy Bridge-EN构成,一部分原属于过去双路至强5500/5600系的市场将被划归这条产品线。而与此同时,主流级两路产品则被划归到Sandry Bridge-EP产品线。在高端四路服务器市场则被细分为入门级四路产品和主流性能级四路产品,入门级产品线将由Sandry Bridge-EX占据。
从产品接口看
从图中右侧我们可以看到,QPI总线一定程度上了决定了产品定位不同,既多路的扩展性。接口也被划分为一路产品LGA1156-Socket H2;两路产品LGA1356-Socket B2;四路产品LGA 2011-Socket R。这与AMD在2010年的G34/C32平台有异曲同工之处(皓龙6100支持2路与4路,皓龙4100支持1路与2路),在四路与两路产品上不在做 明确划分而是提供统一的芯片组,给用户以弹性的选择。按照如此定位的话,今年推出的Sandy Bridge-EX性能将不及我们已知的Westmere-EX。
到这里,笔者有了一定疑问,Socket R的市场将面向谁?生命周期依然是2年?相比起Westmere-EX提供更好的性价比?这个问题我们稍后再讨论。
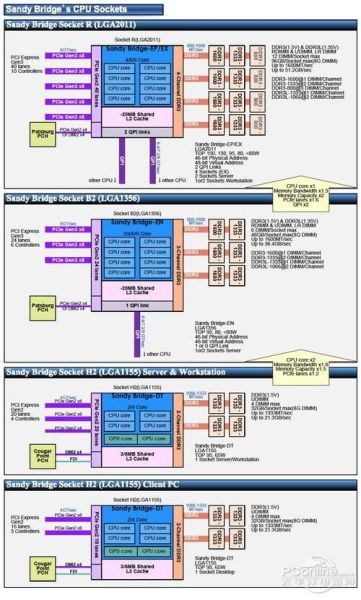
Sandy Bridge家族 从PC到Server1路、2路、4路产品
从图中我们可以看出,从PC平台到入门级服务器工作站平台,同样采用了LGA1155接口,双通道内存,内置GPU核心等,唯一的区别在于对PCI-E通道数量的支持。LGA1155不支持QPI互联架构。
而到了入门级两路平台LGA 1356 接口上Sandy Bridge-EN,提供了24条PCI-E通道,三通道内存(DDR3-1600,支持UDIMM和RDIMM,低电压内存,最大38.4GB/S的内 存带宽),更大的L3缓存等,与现有5500/5600至强相同,会根据占用内存通道数量不同,进行1600、1333、1066的降频。提供1个QPI 用来进行扩展。
在LGA 2011接口上Sandy Bridge-EP/EX上,提供了40条PCI-E通道,四通道内存等,提供2个QPI用来进行扩展。
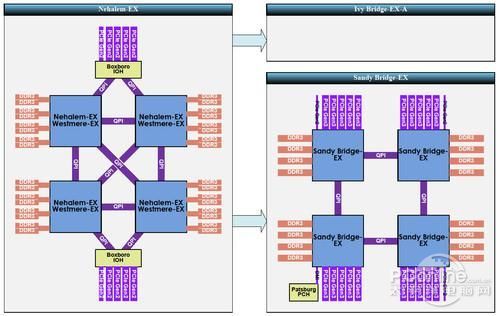
Westmere-EX与Sandy Bridge-EX连接上的区别
从图中可以看出,Sandy Bridge的只有两条QPI与相邻CPU进行连接,而Nehalem/Westmere-EX则有4条QPI与其他CPU全部进行直连。每两颗CPU共 享一个南桥与PCI通道进行通信。使得系统内的CPU通信效劳更高,而Sandy Bridge如果要访问非相邻的CPU数据则要多一个CPU通信环节,一定程度上会降低效率。
Intel 22nm IvyBridge
虽然IvyBridge是SandyBridge的22nm工艺升级版,但IvyBridge并非仅仅是将工艺制程升级为22nm,同时它还带来了诸多 新的特性,如原生支持USB3.0、支持ConfigurableTDP技术、同时还具有更强性能的显示单元。配套主板方面,IvyBridge处理器将 搭配新一代PantherPoint7系列主板,但使用6系列主板可以通过更新BIOS的方式提供对IvyBridge的支持,为用户升级提供了方便。

IvyBridge

IvyBridge除了将工艺制程升级为22nm为,其内部还采用了先进的Tri-Gate3D制造工艺,这也是自硅晶体管问世50多年来,3D结构晶体管史无前例的被投入批量生产。

与之前的32nm2D晶体管相比,22nm3D三栅极晶体管,可以在大量增加晶体管的同时有效得控制芯片的体积,同时在低电压下可将性能提高37%。受 限于物理结构,传统的2D型晶体管已经严重的制约了摩尔定律的进步与发展,而3D三栅极晶体管的出现无疑又为摩尔定律开启了一个新的时代。
新一代HDGraphics图形核心
IvyBridge采用了Intel新一代的HDGraphics图形核心,EU执行单元的数量较SandyBridge翻一番,达到最多24个,同时可支持DirectX11.0。
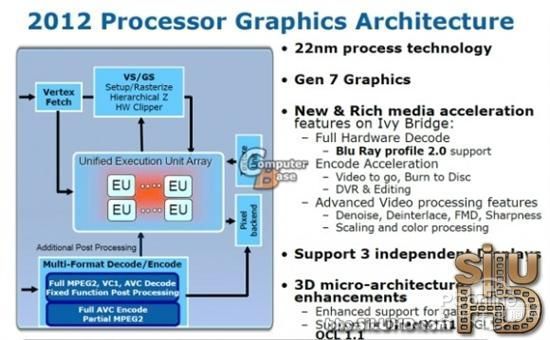
同时,IvyBridge还加入了FlexibleDisplayInterface技术,此技术可以支持用两屏或者三屏输出显示。
原生支持USB3.0
IvyBridge处理器将搭配新一代PantherPoint7系列芯片组主板,该芯片组将加入XHCIUSB3.0控制器,可提供最多4个USB3.0接口。至此主板厂商无需再用第三方芯片。
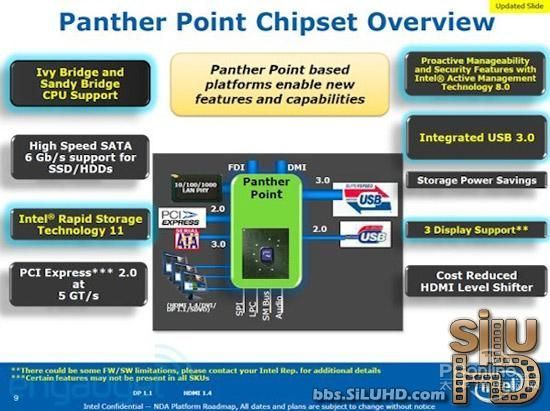
同时,7系列芯片组中还集成了两个EHCIUSB2.0控制器,可提供总共14个USB2.0接口的支持。
ConfigurableTDP技术
IvyBridge处理器还支持一项名为“ConfigurableTDP”的技术。我们知道,IntelTurboBoost技术可以根据系统负载情况,对处理器进行超频,然而超频的幅度始终不会超过TDP功耗的限制。

而ConfigurableTDP技术可在高负载时,更高幅度的超频处理器,不会去考虑TDP功耗限制,但是如果温度超过了界限,处理器又将降回安全的频率。
Intel 22nm Haswell及未来
然后呢,22nm工艺上的新架构叫做“Haswell”,2014年上半年进入服务器领域(桌面2013年);次年制造工艺进化为14nm,新产品家族代号“Rockwell”。
继续往后是又一个新的架构“Skylake”,还是14nm工艺,预计2016年下半年在服务器领域实现(桌面应该是2015年)。
等到了2017年底至2018年初,Intel将在服务器上为我们带来10nm工艺,对应产品代号“Skymont”,至于桌面上可能会在2017年上半年就迎来这个10nmSkymont。那时候PCI-E4.0总线、100Gb网络之类的技术应该也普及了。
如果继续按照这样的速度发展下去,Intel会在大约2019年把半导体工艺带入到单位数字时代。







