
天下武功,唯快不破。武侠世界的金科玉律,同样适用于当前日趋激烈的商业竞争,不败的秘诀,就在于洞悉并快速响应市场需求的变化,小米董事长雷军的互联网思维,就是“专注、极致、口碑、快”。
要快,又要做到极致,大数据的力量被寄予厚望。如何高效地从每分每秒产生海量的、多样的、纷繁复杂的数据中挖掘出蕴藏的巨大价值,转化为先进的信息服务成就敏捷企业,这是摆在企业管理者面前的一个重大难题,也是英特尔、SAP、IBM、Teradata等跨国IT巨头努力重构系统的一个目标。
构建一个实时的大数据分析平台,是巨头给出的破题关键。唯有实时,才能又快又好。巨头的实践告诉我们,这一个实时分析平台,需要多方面的融合,譬如业务与技术的融合,OLTP与OLAP的融合,存储与计算的融合,硬件与软件的融合,开源平台与商业套件的融合等。当然,这种融合不是说简单地把软硬件捆绑到一个盒子里,而是要处处体现了分工与协作相统一的经济学理论。
业务与技术的融合
业务与技术的融合其实没有什么可以争议的。IBM全球企业咨询服务部也曾在一份报告中指出:实现业务和IT融合成为一个统一的、互相交织的整体,能够创造更高的用户价值和盈利能力,并可使IT支出为企业带来成倍的回报。
大数据处理平台的构建,就是为了解决某些业务问题,带来更强的盈利能力,同时降低运营成本。务实的企业CIO们不会为了大数据而大数据,通常是希望通过数据处理平头来促进客户消费,越快越好。
为了实现实时分析,快速响应业务的需求,在内存能够低成本大规模部署的情况下,用更接近CPU的内存计算平台替代硬盘是一个不错的主意,能够打破磁盘的瓶颈。IBM、SAP、Oracle、微软、SAS、Teradata等都已经在干这样的事情。SAP HANA更是已经获得了3600多个HANA客户,包括超过1200个SAP Suite powered by SAP HANA客户。华为公司IT产品线总裁郑叶来表示,部署SAP HANA平台之后,华为全球供应链系统的平均查询时间从一个半小时,缩短到了5秒钟左右,这对华为的业务可视化和迅速决策带来很大帮助。

OLTP和OLAP平台的融合
OLTP(联机事务处理)的发展得益于传统的关系型数据库,基于能够查询一个记录的所有列的行式数据库,处理如插入、修改或查询一条销售订单这样的作业得心应手,但OLAP(联机分析处理)就非行式数据库所长,数据仓库领域的数据分析、海量存储和商业智能更适合采用列式数据库,这就需要用ETL工具把数据放到另一套系统来做。
数据量小、时效性要求不高的时候,这种模式也能够应对用户的需求,但在大数据时代,这个流程就无法满足实时分析的需求了。但SAP HANA加上了内存计算和列式存储的技术,既可以为 OLAP 应用提供列存储,又能为 OLTP 应用提供行存储,同时提供基于自然语言的文本分析、内置的预测性算法等,就能够避开这种尴尬。
目前,SAP已经着手把它的商业套件都迁移到HANA平台上,同时支持云和本地部署的模式,为客户的OLTP和OLAP平台的融合提供了基础。
SAP的老对手、关系型数据库的老大Oracle也已经支持这种融合,其最新推出的Oracle Database In-Memory,通过在同一张表在内存中同时支持行和列两种格式,同时激活并保持事务一致性,对分析和报表采用列格式,OLTP则采用久经考验的行格式运行,这就允许客户突破Oracle自己的传统数据库围墙,可以在OLTP数据库中直接做实时分析。
存储与计算的融合
我们知道,存储系统的功能主要集中在提供对数据存放空间的管理,它与计算并不是割裂的,只是在计算机发展的当前阶段,存储与计算采用了相互独立的方式发展,但它们的融合顺理成章。
当TB级数据出现之后,传统的架构,即RISC小型机加上集中式存储,外接光纤存储,局限性非常大,可扩展的存储方案呼之欲出。在英特尔(中国)有限公司数据中心及云计算业务产品市场总监贺晓东看来,支持数据处理的数据中心需要重构,需要更快、支持更大的数据量和更高的性价比的解决方案。
Hadoop、Spark等架构能够满足这样的需求。它们提供节点通信,实现计算任务的分配,以及容错扩展等等问题,最终实现对分布式系统中各个节点计算能力的聚合。尤其是Hadoop,在节点间传递计算过程,而不是传递数据,能够用更少的带宽更快地推进大数据的处理。这其实是保存算法的存储,是计算与存储的一种融合。
贺晓东表示,英特尔通过至强E5的平台、开源社区Hadoop与合作伙伴一起更好地支持Hadoop。而采用x86硬件,也会使得大数据处理的成本变得更加低廉。在此之前,英特尔已经和Cloudera达成战略合作关系,为用户提供更易于部署和使用、比开源版本更完善的Hadoop技术。
硬件与软件的融合
从英特尔与SAP的合作,很容易理解软件与硬件的融合。贺晓东指出,在业界有这样的趋势,就是做一体机,把硬件、软件(包括分析软件)全集成在一起来作为一揽子的方案交付给用户。当然,英特尔也会提供相应的计算、存储的解决方案,例如,英特尔已经和OEM厂商合作推出了面向医疗行业的英特尔大数据一体机。当然国内的浪潮、曙光等也推出了大数据一体机,而华为、惠普、戴尔、IBM等也和SAP合作打造HANA一体机以支持海量数据的处理。
软件应用和硬件毕竟是术业有专攻,这就需要软硬件厂商的合作才能实现这样的融合。对于内存分析的理念,英特尔在最新发布的E7 v2中也做出了回应,允许单台四路服务器最多支持6TB内存,能够直接把很多数据加载到内存中进行实时分析。
“英特尔和SAP在总部已经合作了20多年,HANA作为一个内存计算环境每次推出的时候,它的版本研发一定是跟英特尔的工程师在做一些底层的优化。芯片上的态势、具体的指令等,都作了很多拓展。”SAP公司数据库及技术平台部售前总监、数据管理技术首席架构师宋一平说。他认为,共同搭建一个大数据处理平台很重要。
开源平台与商业套件的融合
因为数据的复杂性、分析的复杂性和业务的复杂性,我们还无法打造一个万能的系统,譬如Hadoop能够轻易实现PB级数据存储,却短于实时分析,SAP HANA擅长于做实时分析,但内存还达不到PB级,而且这个对硬件要求相对苛刻的系统用于对实时性要求不高的历史数据的挖掘来说,有大炮打蚊子的感觉,太过浪费。
然而,开源平台与商业软件的融合能够为我们带来更简单、更高效、更智能、更敏捷的解决方案。事实上,SAP正在研究内存数据管理与Hadoop的结合。宋一平表示,HANA+Hadoop,也是一种平台和存储的模式,再借助具体的芯片和具体的服务器,就能够打造一个更强的大数据处理平台。

怎么从Hadoop中提炼一些属性数据,以同时实现海量存储和秒级甚至毫秒级分析性能,是SAP的目标。宋一平介绍,Hadoop和HANA的结合,和SAP的数据管理、数据库结合有很多种方式,有在线、离线方式、联邦方式,就是透过前端应用直接访问Hadoop和HANA里面的数据,或者先透过HANA后面再去访问Hadoop的方式,都可以去实现这样一个目标。
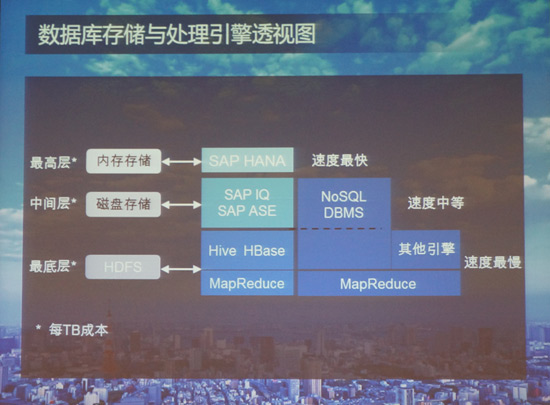
其实,除了SAP,IBM、微软、Teradata、Oracle等公司无不在研究如何打通Hadoop与自家解决方案,以形成大数据处理技术的闭环。
而从英特尔的角度来看,通过相同的x86架构,以全面的产品线满足传统的核心业务系统、实时分析系统、可扩展存储系统、甚至可视化展现系统的不同需求,提供了整个数据生命周期的支撑。这其实能够为这种融合扫清了硬件架构差异的障碍。
小结
总体来看,在大数据时代,我们需要一个融合架构的解决方案。融合是老生常谈,但这里更注重分工与协作的统一。具体而言,融合的核心是数据,融合的本质是让不同特征不同价值的数据得到最经济、最高效的方式存储、处理和分析,我们要尽可能地用一个系统完成这些数据任务,当采用同一平台的ROI不能接受的时候,需要灵活地考虑综合的解决方案,但应当兼具实时子系统和存储子系统,而且要保证数据或者计算力能够便捷地在不同的子系统中自由流动,以便灵活地满足业务需求的不断变化。只有这样,我们才能做到快+极致。英特尔和SAP的合作,为我们展示了一个新融合的很好的样板。







