
谷歌将感到无比兴奋,原因是其云计算数据流服务在最近的一次基准研究中跑赢极为流行的ApacheSpark数据处理引擎,该研究由Mammoth数据公司发起。

当然需要警告的情况也有,因为谷歌聘请了Mammoth数据来开展基准化谷歌云计算数据流研究,主要对象是其数据处理服务和编程模型。数据流是一种有偿服务,但该平台的API最近被作为与Apache软件基金会的联合孵化项目而采纳,并以Apache Beam命名,于今年年初已经提交。
似乎是为了强调项目的中立性,Mammoth数据指出,实际上该项目使用Apache Spark帮助其顾问业务。因此,该项目进行了一次全面的“对象研究”,顾问说。 “鉴于我们在现实世界中使用Hadoop和星火的经验,谷歌要求我们“浅尝辄止”,并分享我们的见解与发现 – 好的坏的都要分享,” Mammoth数据在一份声明中说。
然而结果对于谷歌而言是非常有利的,数据流和几个主要指标Spark的性能相比,已经翻了一番,甚至更多。例如,数据流以更小的集群共五次击败了Spark,并以更大的集群两次获胜,Mammoth数据说道。
“由于我们部署了更大的集群,Spark的确展示了其近乎线性的时钟时间性能的提升,然而数据流曲线更多地呈现出渐进式。” “我们也注意到,大约需要8倍的Spark资源才能达到最慢的数据流任务运行时间(128核),考虑到成本的影响和资源容量的规划时,这是一个关键点。”
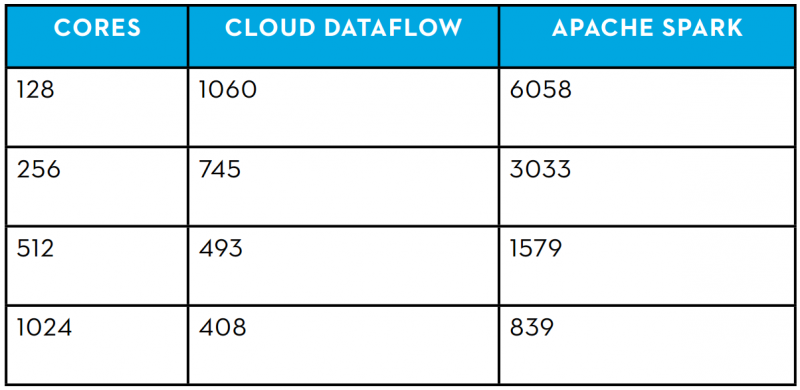
时钟时间性能对比(以秒为单位)来自Mammoth数据
Mammoth数据也观察到自动缩放功能,方便使用和编程模型(对开发商实用)的平台,数据流再次技高一筹,特别是在使用历史数据的时候。
“依托Spark的云数据流有一个明显的优势,那就是Spark的内置窗口功能不可以与“合成”的时间戳共同工作,时间戳; “的报告中说,你只能使用基于时间的Spark窗口来接收数据,而不是存储与数据的时间戳。“这样就很难使用Spark来批量处理历史数据了”。
相比之下,Mammoth数据表示,数据流的原生窗口功能是直接使用的,并采用更简易的模式。使用Spark也有必要“揉”进一些缓存和存储选项,从而避免在基准程序运行期间耗尽内存。数据流,从另一方面看,即使使用较小的节点集群也可以自动管理资源优化。
【更多行业资讯,请关注DOIT官方微信(微信号:doitmedia),关注科技与数据经济,洞察IT走向DT。】







