
高带宽低延迟既是企业的一致性需求,也是网络设备领域的一致性追求。从千兆到万兆,以及到100Gb/s,应用与技术似乎总能互相促进。但是,后者是否在某一天会存在瓶颈呢?
5月19日,DOIT独家报道了《Mellanox将于2017年推出200Gb/s智能交换机》,这是高性能计算的一个最新动向。事实上,Mellanox已于2016年3月发布首个200Gb/s硅光子设备,这已对其200Gb/s交换机埋下了伏笔。
200Gb/s并不是终点。多年来,Mellanox以持续的创新在高性能计算领域奠定了自己的地位,随着深度学习,人工智能等这些涉及密集数据传输的应用越来越多,对网络及计算的要求越来越高,对此,Mellanox下一步有何计划?

近日,Mellanox市场副总裁Gilad Shainer向媒体首次公布了其产品路线图,不仅仅将于2017年推出200Gb/s的产品,还透露计划于2019年推出400Gb/s的下一代新品。Gilad Shainer业没有忘记吐槽老对手Intel Omni-Path,当然,这些吐槽建立在各种数据之上。
高性能计算的演变:Co-Design的产生
所谓Co-Design,在此处就是网络、存储、软件等系统及设备的协同设计,其目标,是通过一种Mellanox称之为Sharp的技术,卸载CPU的部分操作,实现数据传输过程中的计算,从而加速计算进程。
要讲清楚Sharp,就有必要从高性能计算开始。
20年来,高性能计算的发展已经经过了多次迭代。从最开始的SMP小型机,到集群式系统,以及CPU从单核到多核的转变,大幅提升了高性能计算的性能。
虽然多核可以满足同时计算,但是它并没有办法把一个应用程序运行的时间缩短。因为CPU的主频是固定的,这种方式发展应用程序并不能一直地向上扩展。
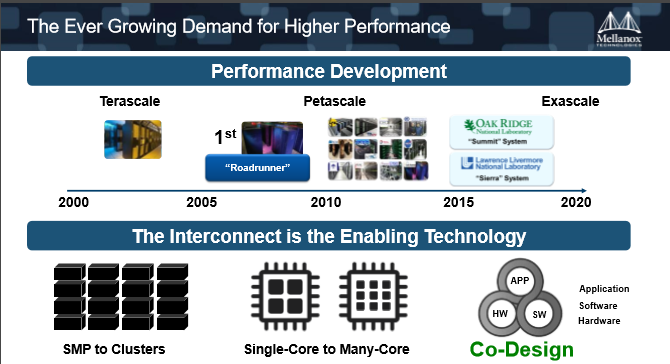
也就是说,之前的计算环境都是以CPU为核心的,但是CPU为核心的计算环境很容易达到性能的瓶颈。因为现在有越来越多的数据,而且数据的处理要求更快、更实时。但是传统的方式是CPU需要等待数据过来才能处理,这就是计算的瓶颈所在。
所以Co-Design的理念应运而生,就是硬件、软件与系统来合作开发面对未来的高性能计算需求,解决性能的瓶颈问题。在Co-Design环境下,CPU只是计算单元之一,存储、网络,在整个计算里面起到的角色越来越重要。
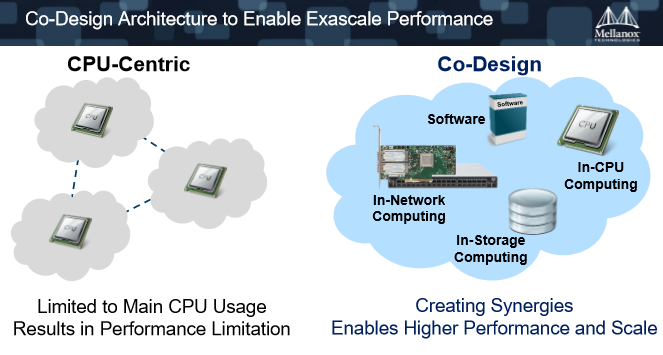
基于Co-Design,可以实现数据在网络中的计算,也就是数据在移动过程中就已经计算完毕了,所以CPU要做的事情已经大幅地下降,这就可以整体地缩减完成一个数据分析或者是计算的时间。
Gilad Shainer说:“通过在网络当中完成计算,每一个交换机都是协处理器,都能做计算。当数据在传输的过程中,我们已经完成了很多需要计算的工作。这是加速效率的一个最有效的途径。”
从网络延迟的发展看Co-Design的必要性
Gilad Shainer还用实际计算中网络延迟的发展来说明Co-Design的必要性。
10年前,一个网络中硬件的延迟可能是10微秒,用在通讯中,加上软件之后,总的通讯延迟是100微秒,也就是说,加载了软件后,网络的负荷加重了。
今天,经过CPU不断地提速,网络的延迟已经从100微秒下降到10微秒。其中,硬件从10微秒下降到0.1微秒。
但是,硬件还能否像以前一样从10微秒下降成0.1微秒?“这是100倍的提升,是不可能的,因为硬件已经达到了一个极限。”Gilad Shainer说。
今天,全世界最快的硬件是90纳秒,也就是小于100个纳秒,将来Mellanox可能会做到50纳秒、80纳秒、70纳秒,但是70、80对90来说只是提高了10到20纳秒,很客观地来讲,这对应用程序是可以忽略不计的。
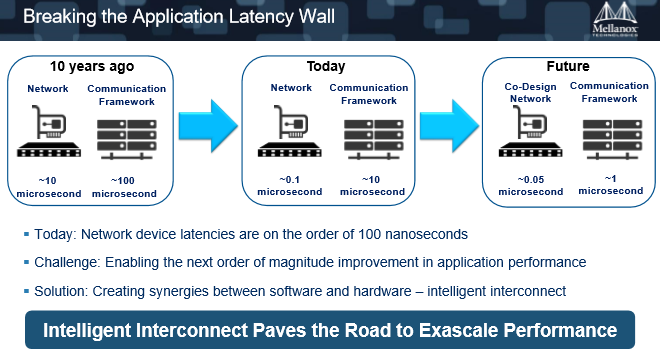
硬件通讯延迟的提升,应用程序却看不到效果。但是应用在软件层带来的通讯负荷相反却很大,它还有10微秒,如果下降成1微秒,还有10倍的差距,而且它跟纳秒级还有很大的一个量级的差距。
所以,除了再进一步地提升硬件的性能之外,在软件,在整个通讯层上要去考虑如何做协同的设计,让整个通讯层的时间能够大幅下降,不能仅仅关注于在网络的本身。
“我们必须要打开自己的思路,让整个通讯的架构有一个转变。这就是Co-design,在数据移动当中完成该完成的计算工作,来降低整个通讯的时间。”Gilad Shainer认为,“现在的情况是Mellanox正在朝这个方向走,很快就会达到这个程度。”
集成Sharp技术的Switch-IB 2交换机
卖了半天关子,Gilad Shainer表示,这种网络完成计算的工作,Mellanox暂且称之为“Sharp”,Sharp已经在2015年6月发布的全球首款智能交换机Switch-IB 2中得到应用。
Switch-IB 2具有全世界最快的延迟的速度,只有90纳秒,支持动态路由等等。除此之外,智能交换机的意义是将原来在高性能计算里用得最多的靠CPU来完成的MPI的操作,转移交换机里完成。从而大幅地提升MPI应用程序的性能。
“这是Co-design非常重要的一步,也是第一步,把集群的通讯移到交换机里去完成。这项技术我们起名叫Sharp。”
Sharp不仅仅能用于高性能计算,还可以应用于深度学习、大数据分析,所有涉及到密集数据传输的应用都可以借用到Sharp技术,当数据汇集在交换机的时候,交换机就会完成一些计算。
约一年后的5月17日,Mellanox与京东签署全面合作框架协议,双方共同建立“JD-Mellanox联合创新实验室”,将在技术创新、用户体验和企业级产品电商平台三个方面展开合作,共同布局人工智能领域,开展底层技术合作,并针对高速互连产品展开联合研发。
Gilad Shainer认为,通过联合实验室,能为更多的应用带来Sharp的体验与应用机会。而Mellanox亚太区市场开发总监刘通则透露,这也将是Switch-IB 2在国内进行推广的一种主要方法。
产品路线:从100G到200G到400G
当然,集成Sharp的,不仅仅只有Switch-IB 2,还有Mellanox的另外三款100G产品。
一是ConnectX-4网卡,可以实现100G每秒,同时它的延迟是全世界最低的,0.7微秒,消息传输1.5亿每秒。这款网卡支持速度也是最多的,从万兆一直到100G,25、40、50全部都支持。
二是以太网设备Spectrum系列交换机,是以太网交换机领域里边最快的一款设备,从万兆一直到100G以太网。
第三是LinkX,是Mellanox的网线家族,其中包括了很多光模块、铜线、光缆,里面有硅光技术。这些是成就高性能网络的一个重要组成部分。

Gilad Shainer终于谈到了其未来产品,他郑重地说:“这是首次公布产品计划。”
Mellanox端到端的200G的产品将会在2017年上半年问世,包括完整的网卡、交换机、网线。这些产品不仅仅是提供200G,还会有更大的交换容量,也就意味着更多的端口数;还会支持更多的通讯卸载。
再两年之后,2019年,Mellanox会有下一代的产品,带宽会翻倍也就是400G。“今天的Sharp只是卸载了一些集群式的通讯,将来的交换机会有更多的卸载功能,做更多的CPU现在完成的事情。”


吐槽Omni-Path:换汤不换药
讲完了Mellanox的技术与产品路线,作为市场副总裁,Gilad Shainer开始对Intel的100G产品Omni-Path大吐口水。当然,作为媒体,乐意看到这种友商之间的比较,因为这对用户市场是有益的。
Omni-Path于2015年11月由Intel推出,已成为强化型SSF的核心组件,有媒体称,Omni-Path是“InfiniBand杀手”。从市场角度,InfiniBand也好,以太网也罢,再加上Omni-Path,应该是各有各的精彩罢了。
2012年,Intel收购QLogic公司的InfiniBand部门,而InfiniBand部门的前身是PathScale公司,其产品名称叫InfiniPath,是20G的InfiniBand网络,基于Onload技术,完全用CPU处理;PathScale被QLogic收购后,网络产品的名字从InfiniPath更新成TrueScale。
Mellanox的优势建立在InfiniBand之上,当Omni-Path杀上门来,无疑,Mellanox不可能按兵不动。
Gilad Shainer吐槽说,Omni-Path采用的是TrueScale,一项没有做改进的技术,只是把物理层的速度从40G提到了100G,核心没有任何变化,当然,再一次修改了名称。
而Mellanox实现网络是用的Offload的技术,也就是协议的卸载技术;英特尔是用CPU在处理网络通讯,也就是Onload,“所以两个的理念是不一样的。”
Mellanox会继续走协处理器这个概念,把网络做成一个协处理器,做成一个智能的处理单元去来加速网络速度。相反英特尔做Omni-Path会让自己的网络完全依赖于CPU,这是一个不同的路线。

Gilad Shainer展示了Offload与Onload的区别。
1.Offload所有网络方面的运算处理都是用网络芯片来完成,数据在移动当中就可以做计算,所以对芯片的要求很复杂。可能不会很快地设计出来一款智能的网络,能够做卸载的网络,它需要很多很多年的技术积累,而且芯片要做得非常复杂。而且一旦芯片设计出了一点点问题,就要重新做流片,而重新做流片的代价非常非常大,所以Mellanox的芯片设计得复杂、成本高,但是处理能力强大,因为Mellanox的芯片本身做的是计算,这也使得数据通讯更加高效。
2.Onload技术也就是英特尔的Omni-Path的技术体系里面,是崇尚CPU为核心的理念。这种理念如果从网络设计来讲它比较简单,因为它实现的功能都是用CPU实现的,只是编软件,所以相对来说,芯片的成本很低,因为它不用设计非常复杂的硬件逻辑在它的芯片里面,这是它的一个优势。
3.Onload的缺陷是网络会吃掉它的CPU资源,因为它的所有操作都需要CPU去完成。不管是早先的InfiniPath,还是后来的TrueScale,到现在的Omni-Path——它这三代的名称,但是用的技术是一模一样的——用CPU去处理网络。这是无法满足现在大数据、高性能计算中通讯密集型的需求的,也是应用没有办法在Onload的架构下面去扩展的一个原因。
4.举个例子,LS-DYNA的应用,该软件是在汽车制造领域里边做碰撞分析的主流软件。一个是比较小的实测案例,一个是比较大的测试数据的案例。在这两个测试的环境下,InfiniBand领先Omni-Path从48%到63%。
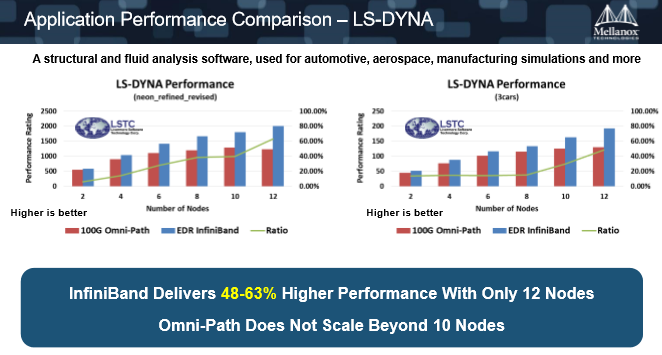
如上图,左边数据级比较小的时候InfiniBand的优势会更大,因为当数据集小的时候,计算需要的部分就会小于传输的密集性。越小的数据集它的数据传输的消息越小,它传输的密集度越高,所以在这种数据集的情况下,当进行密集数据传输的时候,会有更大的CPU资源耗费在网络传输上边,使得它的可扩展性很快就会下降下来。用英特尔的网络,12个节点比10个节点还要慢。但是Mellanox还在持续地增长。
5.当你买了便宜货以后最终你会付出得更多。我们的设备是必须要付钱的,因为我们的芯片开发成本更高。比如你买了100万的设备再加上15万美金Mellanox的网络,总的成本是115万美金,但是因为我们不耗费任何的CPU,所以100万购买了计算资源,最后还能得到100万的计算能力,只是你花了115万,因为15万是我们的网络设备。
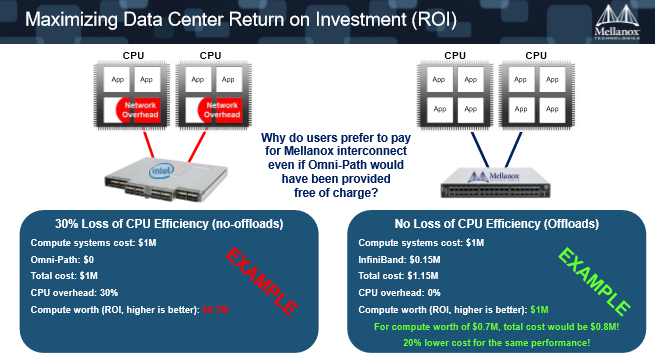
花了100万只能用到70万,跟花80万就能用到70万,差别是很大的。“我们不能去单独考虑每一个计算单元的价格,我们要把它放成一个整体系统的投资回报率去考虑。”Gilad Shainer说。
吐槽完了,Gilad Shainer最后总结说,InfiniBand网络还是现在能够提供给应用最好性能的一种网络,使用户的投资回报率,或者说使CPU能够成为真正有效的一个计算资源。而且InfiniBand不仅仅是简单的网络转发功能,已经变成了协处理器的角色,成为了更加智能的一个单元。







