
8月8日,主题为“新技术下的IT管理和能力提升最佳实践”的“第三届国际最佳实践管理联盟中国年会”在北京召开,来自IT、通讯、金融、互联网等行业的CIO/CTO及IT管理者约200人参加了本次年会。
开放运维联盟联合主席,高效运维社区发起人萧田国在比较ITIL与DevOps的基础上,对DevOps的发展及部署特点进行了生动的演绎。
实际上,ITIL与DevOps的区别很大,最本质的区别,ITIL是对内的,是一个基于流程的导向,DevOps不是,它是一个技术性的导向;或者说ITIL是一个层次更高,DevOps会做很多的细化,侧重在实现层面,虽然这种实现到最后又会倒逼ITIL。
当前,业界对DevOps有两种理解,一种理解就是开发的能力延伸到了运维,第二种就是运维能力传递到开发,最后他们的结果就是一个高质量持续快速部署的价值。这就带来一个问题,是运维更适合做DevOps,还是开发更适合做DevOps?一般而言,运维侧更合适DevOps。
 开放运维联盟联合主席,高效运维社区发起人萧田国分享DevOps运维理论与实践
开放运维联盟联合主席,高效运维社区发起人萧田国分享DevOps运维理论与实践
萧田国表示,DevOps首先是一种文化,它推崇的是集成,如果说一个公司的系统实现了DevOps以后,它能做到一天十次部署或者更多次部署,而在大型的传统企业,能做到三个月一次部署就已经很不错了,并且主要的问题在于没有办法迭代,没办法到一个生产环节上做快速问题的验证。
随着移动化、社交化的发展,现在不管什么行业,他们进入到互联网的业务都会被迫带着做快速的迭代。所以一个好的运维自动化平台,首先需要能识别出来目前这个业务里面的痛点和瓶颈,把痛点和瓶颈先做完了,当然一般的痛点和瓶颈首先都是持续交付。其次,所谓自动化整个价值流,再把这个价值流的事情做一个数据分析,如果说有心有力的话,可以再做一个API及服务化,就是调用,而不是走直接的服务器访问,所有的都是基于API化和服务化,到最后再做一个评估和持续的优化。
以下为萧田国演讲实录:
各位老师,各位朋友,大家好!我做一个简单的自我介绍,这几年我跟一帮朋友做了些好玩的事情。我们做运维十几年时间了。
这一年多时间做到了五个第一,做了中国第一个运维的社区,高效运维;做了中国第一个运维行业协会——OOPSA开放运维联盟,中国第一个行业大会——GOPS全球运维大会,以及中国第一个运维的标准草案——互联网应用运维框架及能力模型。因为我们知道在国内基于互联网,因为运维没有任何的标准草案,这个事情我们在做了,以及我们做了中国第一个运维的节日“724”,这个节日意义很多,“724”就是“cheers”表示欢呼的意思。
今天我跟大家分享一共有三块,第一块对于运维下一站的趋势解读,第二个给大家介绍一下国内基于DevOps比较领先的运维平台,第三个,在这个运维平台里面持续交付平台的实现方法。
在很多年前ITIL当时提出来的时候,大家知道是有背景的,那个时候所谓的巨石架构,是基于客户端的设计。这时架构都是“巨石”型,很庞大,每个新版本的上线都需要半年、一年的时间。那个时候我们说,作为一个版本迭代,或者说部署,不是问题所在。整个运维也是一个初始的状态,所以说很多时候在最开始的ITIL做的事情,不管是横向的做IT技术数据管理,还是做竖型的流程管理,其实还是要解决内部的问题。
但是在进入了互联网时代以后,这个情况发生了变化了。互联网基于海量用户,而且整个业务架构由CS端变成了BS端,还有就是APP形式,一个APP的前端可能非常简单,但是后端可能极度复杂。
例如“双11”的时候,很多用户会发现0点0分,看到那个图标就在那儿转,用户很着急也没有办法,他也不知道后面有几百万的并发在跑着。这个阶段就会需要快速迭代,需要DevOps,并实现持续交付。
我们会认为现在ITIL对运维的理解跟DevOps的理解还是不一样。作为DevOps而言它对于运维的理解是自动化的过程,我们回过头来看ITIL的时候发现,里面很多动作或者配置、管理都是基于流程、基于文档的,作为DevOps的任务就是要消除掉纸质的,让一切东西都是用系统来运行,这个时候更多的危及着基于ITIL厂商的生意,但是我们实际认为ITIL的本质或者ITIL的核心思想是在DevOps等等里面有一个生根发芽与成长的,我们改变了形式,当然最终结果也会出现很大的改变。
我们看到ITIL跟DevOps的区别很大,当然最本质的区别,ITIL应该是对内的,是一个基于这个流程的导向,DevOps不是,它是一个技术性的导向。DevOps会给ITIL带来冲击的地方就在于,原来我们说的ITIL所面对的就是右边的Ops,但是有些时候Ops是”双背“,一个是背服务器,一个是背黑锅,这个时候他怎么实现更高的价值交付?之前的时候我们知道Dev跟Ops是隔山相望,Dev想你先跳,Ops说你先跳,两个是相互扯的。我们目前的概念,有了DevOps以后,他们两个在一起了,或者一起跳,或者一起让别人跳,这可能是比较大的改变所在。当然作为DevOps很多人会有很多不同观点,待会儿我们会再去阐述。
还有一个图简单的表述一下,我们所认为的ITIL跟DevOps区别。一个是流程思维,一个是技术思维,或者说ITIL是一个更高层次的东西,DevOps会做很多的细化,他会做很多的实现,虽然这种实现到最后又会去倒逼ITIL。所以如果我们基于DevOps的一些理念做运维的话,我们有一个总结,叫一体双翼或者一只鸟,这里面的一体,当我们基于这个标准与规范,基于这个服务化,基于这个状态,这里面会有一个实现,两边我们再去实现基于它的双翼,在右边是自动化运维,左边是数据运维。基于我们首先是技术层的一些事情,以及这个理念层的一些拓展,最后能够带着我们运维一起飞。
我们对于DevOps还需要有更深的理解。实际上在不久之前开发跟运维是一个天生的仇敌,我们知道作为开发而言,他做的事情,就是把这个程序做完就不管了,他比较爽的地方,在他的背后还有测试,对测试说我没问题了,对运维说你去上线,这个时候会有很多问题,就在于说,很多时候是开发,他可能版本的提交是快上线之前了,最后结果运维就是背黑锅的。运维一上线有点慢,最后说看看你,本来这个问题分分钟能解决的,就是因为你老上线很慢,blablabla。
上线分为三种,一种是上线开发环境,一种测试环境,还有一种是生产环境,以前很多时候开发,任何地方的上线都是不做的,很多时候更多的是相互的推诿。我们说这叫做部门墙,开发指责运维,运维指责开发。
为什么会这样?原因非常简单,在于开发跟运维本质上他们的思维模式是不一样的。开发的思维模式是要求快,他要求功能快速上线;但是运维要求是稳,就是说你别给我出事,又快又稳这是不太可能实现的东西,所以说这里头就会出现很多的扯皮。
而且还有一点,开发如果出问题测试给他兜底,甚至有一些CTO说,所有的问题都是测试上的问题,为什么啊?因为那个人是CTO,他做开发出身的。运维很不容易的地方在于说,运维实际上很多时候自己既要做操作,还要做测试,还要做检查,这就是人为事故的根源所在了。
所以我们看一下,在以前的模式里头分为两种,这里头的第二个模式,那就是说开发,他把东西做完测试,测试完以后由运维部门进行发布,后来又改进了,后来改进我们起一个名字叫敏捷,那就是说开发跟测试他们很开心的在一起玩了,他们玩的很开心以后再把版本扔给我们运维,这个时候运维的地位还是没有改变,整个问题没有解决,而且最关键的是公司的成本、公司的绩效并没有提高,当我们抛弃掉左边的方式,当我们变成右边的这个DevOps方式以后,我们会发现这时候实际上要求一个人要同时具备有开发、测试、运维的思想,或者说现在的事情只能变成大家一起愉快的玩耍了。这个时候他们之间的关系就由敌对变成合作的关系了,他们只能共享这个目标和责任。
一般认为因为瀑布式传统的开发模式导致了开发测试和运维的割裂,现在的DevOps要把这个扯到一起去了,但是根据《三国演义》的观点,那就是分久必合、合久必分,我们不知道什么时候他们又会分开,都是根据当时的时势做的变化。
作为DevOps拥有两种理解,有一种理解就是开发的能力延伸到了运维,还有第二种就是运维能力传递到开发,最后他们的结果就是一个高质量持续快速部署的价值。这就带来一个问题,大家认为你是运维更适合做DevOps,还是说开发更适合做DevOps?认为开发更适合做DevOps的轻举手。我们还是认为,还是站在我们运维侧DevOps,强是运维做更合适。
DevOps我们来做一个解读,首先DevOps是一种文化,它所推崇的就是一个集成,如果说一个公司的系统实现了DevOps以后,它能做到一天十次部署或者更多次部署,那就很厉害。我们知道在大型的传统企业他们能做到三个月一次部署就已经很不错了,而且每次部署都是严阵以待,每次部署都是上百号人,在晚上零点或者零点以后进行,每个人都绷紧神经。这个方式的弊端在于哪里?或者说之前传统的,很多次的测试、很多次开发,最后却还是很紧张,问题在于哪里、在于他没有办法迭代,他没办法到一个生产环节上做问题的快速验证。
DevOps是一种思维,很明显,我们盗用一句话,互联网思维叫“极致、口碑、专注、快速”,DevOps就是“精益、价值、跨界、敏捷”。作为DevOps而言,其实是一个共享责任,就是说你没有办法去踢皮球了,从现在开始自己挖个坑含着泪也得往下跳。而且在我们要应用到DevOps的时候很明显,我们对于工具的依赖就要比以前重很多了,现在你要想实现一个自动化,我们知道商业软件也不可能说那么快的跟得上,这个时候你一定得要大量的去用到各种各样的开源软件,而且这个时候你需要系统去做更多的分层,为什么?因为现在你的这个迭代次数变得更快了,你今天部署的版本可能10次、20次,你后续的调度、后续的数据分析是不是也需要跟得上?如果说他们跟不上的话,你一个人在前面跑,那是瞎跑。
这里头当我们把Dev跟Ops合到一起的时候,他们之间的部门墙就被拆掉了,拆掉完以后它的价值实际上是能够去提升公司效率更加聚焦到商业和用户价值,一会儿我们会有一个例子,用那个例子仔细的跟大家讲一下,这个事情DevOps的持续交付最终的结果是什么,以及他最终所带来的好处是什么。
我们刚才说到了DevOps这种思维,像以前的时候,大家习惯于本位的去做一些仗对,绿色、黄色、红色就是开发运维,相互指责去骂街。现在每个人都要互通有无一下了,所以说这时候就没办法说你说你有理、我说我有理了。
这个时候作为DevOps而言,底层的持续交付平台不管说他是由Dev所实现的、还是Ops所实现的,不管怎么样,最后他们对外都是要提供一个稳定、高可用的系统出来。这个时候就是Dev运维跟系统运维测试被迫走在一起。而且我们知道DevOps为什么起来?他也跟现在很流行的云、微服务,包括很多别的技术在一起有些绑定。
看一下,如果说基于DevOps去做一个运维平台的话是什么样子的,那就是我们的一种具体实践了。首先,我们需要看一下运维的价值是什么。实际上运维的价值不应该是一个搬砖的,而且运维的价值不应该是搬服务器的,为什么?一则运维目前为止没有服务器可搬了。
那么,运维下一站价值在哪里?考虑到运维能力范围分四块:质量、效率、成本、高可用性架构。基于这个价值体系我们推出来基于什么服务,包括性能优化、体验优化、安全、成本,包括具体的,为了实现这些提升我们要做些事情,要做标准化、规范、方法化。最后的落地会有平台,一个是持续交付平台,还有数据平台,还有安全平台。刚刚这里头提到了那个“一体两翼”,其实这里头的一个持续交付平台就是是现在右边的自动化,数据平台是实现了左边数据运维,安全平台看情况,因为一个公司如果太大的话,运维还是最好把安全分开比较好,不然死的很惨。
这里我们跟大家简单看一下,一个基于DevOps的运维平台它的能力设计环,我们知道,运维平台制作的时候不要一开始讲究大而全,这会死的很惨,因为跟老板说我需要三年做运维平台的时候,老板可能三个月就把你开掉了,老板耗不起。
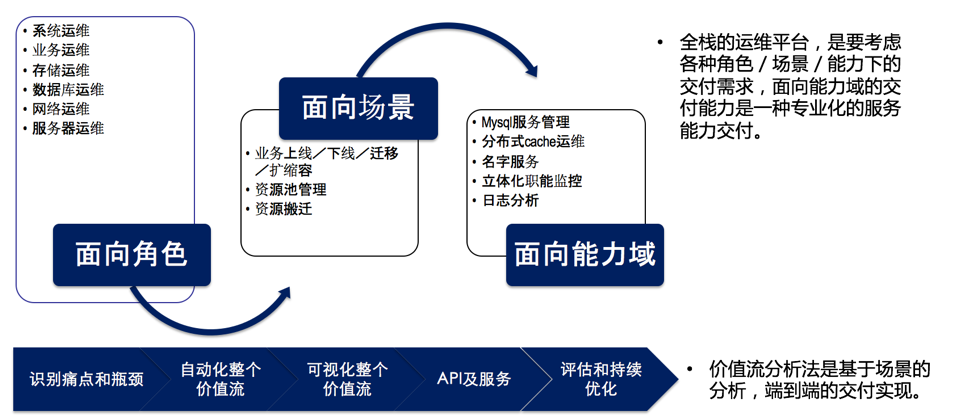
现在不管各行各业传统行业也好,他们进入到互联网的业务都会被迫带着做一个快速的迭代。所以说一个好的运维自动化平台,首先是最左下角,需要去识别出来目前这个业务里面的痛点和瓶颈,把痛点和瓶颈先做完了,当然一般的痛点和瓶颈首先都是持续交付。第二步所谓自动化整个价值流,再把这个价值的事情做一个数据分析,如果说心有力的话,可以再做一个API及服务化,就是说调用,不是走直接的服务器访问,所有的都是基于API化和服务化,到最后再做一个评估和持续的优化。
这里头需要有面向角色做提升,需要面向场景以及面向能力域,我们说实际上在以前的时候,在运维内部也是割裂的,那就是说系统运维、业务运维存储、数据库、网络、服务器运维他们是分开的。这个分开是错误的,我们实际上要是改为面向场景,运维的内部部门怎么去配合,以及我想实现这样的池化怎么办。第二个场景做完以后,对于老板而言就会很爽了,因为这个时候他已经有产出绩效了,如果我们心有余力可以再做各种各样的服务化的事情。
这是我们所推出来的一个现在通用的运维平台的概念模型,整个运维模型分三层,第一个IaaS层,第二个PaaS层,PaaS层基于IaaS层的,正是因为我们把运维很多的事情抽象化了,变成了一个API的形式,把它不用再去依赖于具体的人力了,所以说基于此在上头才有可能去做一个持续交付平台、一个监控平台、一个ITOA平台,还有一个安全平台,这两块加起来叫PaaS层。往上走才是我们真正的价值所在,就是OaaS。这里头运维即服务就是说我们对外能够提供什么服务。实际上我们现在很多朋友告诉大家运维不是那么Low,部署只是我们第一步而已,只要我们底下做好了可以对外提供例如说产品的用户体验优化服务,我们可以提供一个连续支持服务,可以提供质量优化服务,还可以提供故障知率服务,还可以提供成本的优化服务。
我们看一下第二级,这个看不清楚,之后再提供给大家。这是IaaS第一层,第二次是CMDB,大家都知道很重要,但是作为互联网而言,做的是把手动配置变成了自动发现,虽然有的时候自动发现失败,但是不管怎么样,这是一个很重要的步骤。但是互联网去聊到CMDB的时候,不会只是说对服务器、对基础资源,还有第二大块,对于应用、配置文件、配置参数,也属于CMDB的一部分,这是一个应用层,还有一个逻辑层,包括人员、角色、代理商、组织机构、服务商,都放到CMDB里面去了,所以说不是以前的CMDB,这里头所有的调用基于API化。
中间这个一个是ITIL的服务管理,包括事件管理,还有配置管理。就像我们刚刚所强调的一样,我们这里头所有事情都会做到尽量的自动化。我们说自动化不是因为中国缺人,而是因为中国人太多了。什么意思呢?国内海量用户,导致说变更很频繁,只能用机器代替人做事情。
第三级,我们这里面强调的,会做一个自动化服务的管理,特意把一些公共服务拿出来,例如说负载均衡,自己内部的内容,还有存储服务,还有大文件的存储服务,还有消息队列。
刚刚我们向大家呈现了一个基于DevOps运维平台的全景,这个全景里面的点还是挺多的。
这里头最关键的也是对于公司带来最直接的效益部分,就是持续交付,很多人都很容易的会把持续交付、持续部署和持续集成混淆到一起去了,很明显这个时候我们应该做一个原始的定义,就是说持续交付是一种全面的工程实践,是能用最小的成本、最快的速度实现价值的端对端面对用户的交付。自动化的持续交付就是持续部署,或者说持续部署是持续交付的一个高阶段。这是持续交付整体的架构,包括平台、能力、管理。
这是一个持续交付的最佳实践,这个章节是来自于《持续交付》那本书,时间有限,今天就不说太多了。
我们看看在实现了这样交付流水线以后,开发者自己触发一个源代码的更新,再去实现持续集成,获取了代码上线打包,这里面可以上传到开发环境、测试环境、生产环境,意味着开发者要为自己付的债自己去买单,就是说你可以自己去上线代码了,要出问题跟我运维是没关系的,你可以第一时间去发现问题。所以说最大的价值就是减少扯皮。
这里我们的价值链实际上就是整个交付链了,包括持续部署、持续测试、交付、持续运营、需求队列,然后就是PDCA的过程。
当我们去实现持续交付,如果说要把它做到自动化的端对端,首先应该是打造一个作业的交付层,然后是应用的交付层,然后才是业务的交付层,归根到底也是分层结构。我们需要做的事情包括,资源及服务IaaS层,系统服务层、架构服务层、应用服务层、业务调度层,其实我们这个图跟刚刚的平台是相一致的。


作为持续交付的一个构建阶段,持续部署它的业务目标包括什么?它的业务目标首先最直接是一键化的业务变更能力,包括左边的包/配置、服务、环境等资源生命周期管理,还有其他部分。
我向大家推荐这本书,Google SRE最佳实践,这本书的中文版就要出版了,会在今年9月23日-24日的GOPS上海站上全球首发,到时候Google SRE的原作者,译者及Google SRE主管工程师都会去现场。这也是一个盛举,大家如果想要买门票找我。
我本次演讲就到这里,谢谢大家!







