早在几个月前,我就盼望着参加这次超算大会。一方面恰逢美国“黑五”与感恩节,能够剁手买买买;另一方面,每次大会上,都会带来许多新的惊喜。
我说的是新产品、新技术的展示。作为全球超算行业规模最大、档次最高、参与人数最多的盛会,全球超级计算大会上许多超算行业厂商都会拿出自己的“看家本领”,这也是了厂商产品的好机会。大嘴哥在会场转了几圈,就发现了不少“黑科技”。

比如这个全浸没的液冷散热装置,它出自3M之手,就是那个我们许多家都有的,生产拖把、百洁布、擦碗布的3M。

虽然是IT行业大会,但是不少厂商却展示了包括宝马、法拉利在内的高端汽车。这背后,是非常火爆的自动驾驶,是人工智能的兴起,更是机器学习的重要体现。
说到机器学习,就不能不提及一个厂商——戴尔。在并购了EMC之后,戴尔的产品线进一步扩展,也结合EMC的产品推出了整合型解决方案。甚至在展台颜色上,戴尔放弃传统的蓝色转而像黑色靠拢,展台上方的“DELLEMC”字样更是醒目。

让我们回到机器学习的话题。这次,戴尔携带了一款型号为C4130重量级的产品参展,之所以说是“重量级”的产品,一方面这款产品进行了加长,满配之后甚为沉重;但是更重要的是,戴尔赋予了这款产品多环境应用的可能性。
一般来说,当下使用机器学习的用户大多采用的是标准服务器,也有许多企业推出过针对机器学习的服务器,可无外乎也就是增加几个PCIE接口,供电方面进行加强。但是戴尔这款产品采用了完全不同的思路,因此更值得研究。
这款服务器的一个突出特点就是将GPU加速卡与CPU的位置进行了对调,这在以往的服务器中是很少见的。在此之前,业界更多关注如何增加GPU的供电与散热,保证更高性能下系统的可靠与稳定。

但是戴尔明显反其道而行之,将GPU前置的做法解决了传统的散热难题,而相比之下处理器的散热处理则要容易得多。就这样,戴尔C4130可以保证在1U空间内支持4块全尺寸GPU卡,大大提升了系统的计算密度比。
如果仅仅是这样,还算不上C4130的黑科技。中国有句话,叫做龙生九子,各有不同,这句话放在C4130身上特别的贴切。这款产品拥有九种形态,可以适应不同的应用需求。
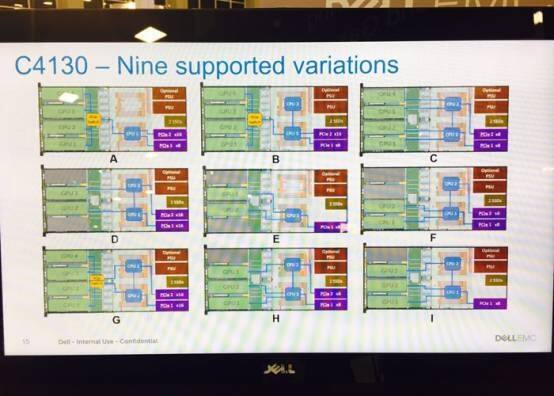
如果客户需要大量的视频处理与分析,可以选择GPU聚合模式,这样可以整合4块GPU加速卡的性能;如果用户的负载没这么高,甚至用户需要桌面计算那么单块GPU卡就足以满足需求,甚至可以使用单颗处理器……
这绝对是一个创新性的改变。更多的GPU,更灵活的处理器应用方式,恰恰迎合了当下资源池化的要求,通过不同的应用模式进行计算资源的再分配,实现业务的因地制宜。

另一款适合灵活扩展的是戴尔展出的“2 TIERS”云集群。这款产品融合了DELL和EMC两家的产品。在观察这款产品的时候,大嘴哥刚好碰到了戴尔高性能计算方案架构师凌巍才。

“他乡遇故知”的我热泪盈眶,终于不需要再使用我那蹩脚的英语了。据凌巍才介绍,这款型号为2 TIERS的产品整合了计算、存储的特性。在传统环境中,计算与存储资源的需求度很难平衡,但是这款产品则可以帮助客户实现动态的资源调整,帮助客户实现业务应用的最大化。

记得上次看到凌巍才的时候,他还饶有兴趣的为我介绍了戴尔面向高性能计算领域的5大方案——包括科研教育、制造业、生命科学、NFS存储和Lustre高性能存储等。而在这次展台上,我们还看到了包括机器学习、能源勘探之类更多的解决方案。“这些方案将会陆续在中国市场推广,帮助更多的用户用好高性能计算”。
“以客户为中心,推动HPC民众化”一直是戴尔所践行的目标。如今,戴尔高性能计算解决方案已经应用在科研、教育、能源、制造、交通、医疗等许多领域。戴尔也将联合领先的合作伙伴和积极采纳社区标准,通过创新的、高性价比的解决方案组合,帮助更多的人来创新和发现。