随着用户对存储,计算能力等综合需求日渐加强,国内企业基本都在谈论并根据自身情况应用超融合,且多围绕其定义,价值,与产品优势展开,今天来看一个相对技术的话题,裸金属架构的软件定义存储。近期闭幕的中国存储峰会下午场,超融合技术论坛中,FusionStack CTO,王劲凯发表了名为《裸金属架构的软件定义存储》的主题演讲,从高性能存储技术的演进,深入介绍了裸金属架构。

以下为王劲凯先生的演讲实录整理:
FusionStack公司介绍:2007年成立,公司做分布式存储。2010年上线首个超融合项目,是国内较早做超融合项目的企业。
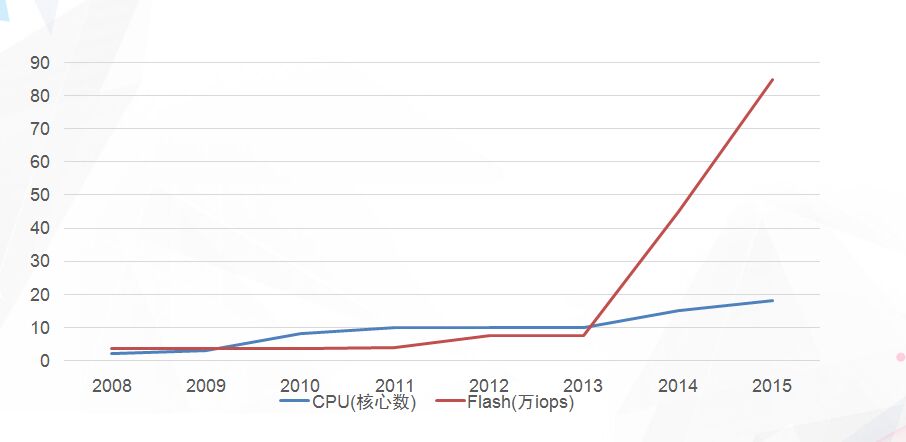
我们先通过英特尔官网数据画出的一张图来分析过去十年闪存的动态。红线是闪存的性能增长曲线,从2008年开始到2013年,闪存性能变化并不大。从4万IOPS达到10万IOPS,2013年之后突然爆发,目前可以看到将近百万级别的IOPS的闪存成为主流。另外就是CPU性能增长曲线,CPU性能过去在十年变化也不是很大。这里我们发现一个非常明显的问题,存储软件性能逐渐跟不上闪存的发展,闪存性能继续提升,存储成了整个软件定义存储和超融合的瓶颈。
高性能存储技术演进触发的裸金属架构
在过去的十年里,阵列时代的高性能是高速缓存技术。磁盘性能比较低,一个磁盘一秒钟处理100IO。数据量相对不是很大,热点比较集中。用内存来做缓存,实际IO落到内存里面,这种方式是过去十多年来一直用的方式。
分布式时代,谷歌领先分布式互联网架构时代,大家用的是并行IO。这时的时代特点是什么?磁盘性能低,数据量大,热点不明显。大量磁盘,用软件把IO聚合起来,一个分析业务我们把它拆散到数百块磁盘甚至上千块磁盘处理,这是分布式时代的一个做法。
现在已然进入了闪存时代,闪存性能高,延迟低不再需要你去优化。但几乎所有软件都落后于闪存的性能,用户可能在买超融合的时候,购买多块闪存,一块100万IOPS,3块就是300万IOPS,你的软件能跑300万吗?通常不能。用非常高配英特尔至强2699的CPU跑到30万IOPS,一个节点。
在2013年前后,我们注意这到个问题,然后进行了深入研究,最终提出了一个裸金属架构概念。
裸金属架构实现应当注意的问题
这个架构首先我们要注意几点,第一intterupt是什么?过去编程通常会使用中断,你第一件事情就是避免中断。原子操作,用来实现锁,无锁队列。我们有CPU原子指令可以实现。过去那个时代,这个东西比较高效。闪存实现这个东西变得比较低效,带来核之间的互斥。TLB miss(TLB是页表缓冲,就是负责将虚拟内存地址翻译成实际的物理内存地址,而CPU寻址时会优先在TLB中进行寻址。TLB miss则表示TLB中没有所需页表),而处理器的性能和寻址的命中率有很大的关系。还有NUMA的问题,你在一个CPU访问另外一个CPU内存会发现非常之慢。可能延迟增大一两倍,一般场景没有问题,闪存场景不可用。
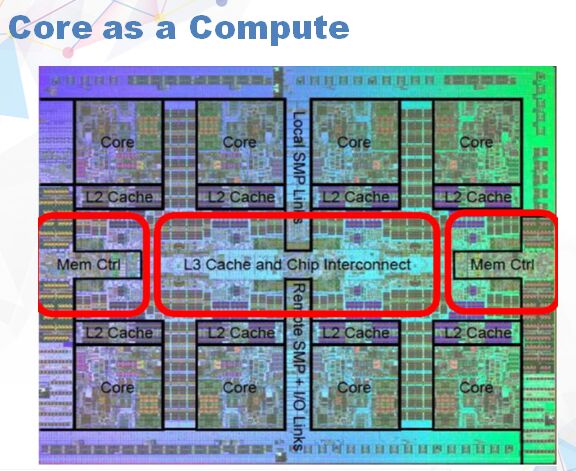
这个是CPU内部的照片,八个核,中间红色部分是CPU核之间的链接。有一个比较有意思的现象,每一个核会带一个L2 Cache,核与核之间通过内部高速联接连起来。你会发现一个问题,如果你一个核访问数据,它所带的L2会很快。但跨一个核,在另外一个核上访问数据就会出现性能下降问题。我们提出一个理念就是Core as a compute,你跨一个,哪怕另外一个节点也是远程访问,带来的代价可能会导致软件性能急剧下降。因此设计的时候尽可能的避免远程访问,做到每一个核处理自己的事情,核与核要尽量压缩。
总体架构要进行哪些改进?首先传统编程模型里用到生产的模型在闪存时代是不可用的。我们用的是Producer-consumer模型,现在用的分时操作系统,出现之前采用的就是批处理的Producer-consumer玩法。任务调度,调度器导致你性能下降,会反复去影响你的寄存器。我们在这上面设立了协作式调度器。事件处理,传统模型采用event,event延迟很高,会达到10微妙,对闪存来说非常长了。我们用的是Polling模型。过去采用多核共同处理一件事情,我们用lock/lock-free。其它就是关于硬件访问,你采用访问网卡或者硬盘都会把它交给操作系统。这些我们都避开了。
Run-to-completion,采用polling和recv,exec,send四步。采用这个模型基本上就避免了我们刚才所说得几乎所有问题。我们要把VM的访问,根据不同数据的位置放到不同的核上。避免核和核之间的交互。那么,coroutine(协程)能不能提升性能?答案是不能。调试困难,gdb不可用。Swapcontext开销大(150万次每秒),需要改进。我们目前的测算是每秒能测算150万次的切换,这个对我们来说太慢了,我们自己来写,但如果计算器的拷贝遗漏了不该遗漏的东西,后果很严重。
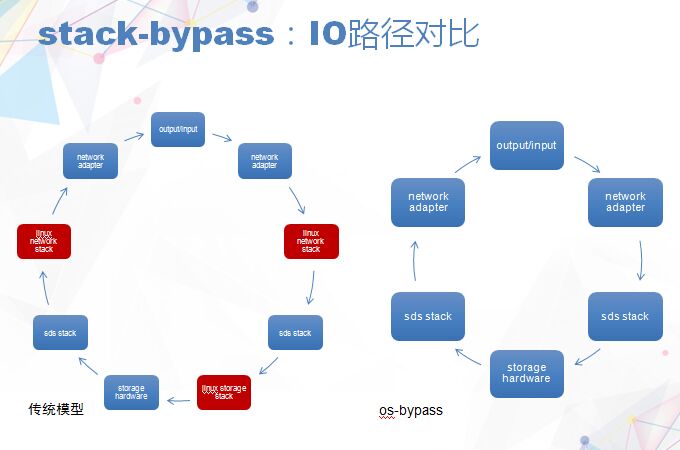
Stack-bypass是绕过操作系统访问硬件的部分。首先红色部分是操作系统的对站,通常无法绕开红色部分对站,已经有很成熟的方法已经列出来了,可以让你绕过这些东西,我们把这些东西彻底解决掉了。
另外,我们知道ceph,ceph我们目前看到的数据比较快,能够跑出15万IOPS。到了今天我们延迟已经压缩到300微秒以下。我们单个IO延迟是软件对站里面延迟,目前是3微秒, NVME设备是90微秒。英特尔下一代的处理器延迟是10微秒,我们只需要3微秒完成它软件层的处理。未来把这个压缩到更低,有可能压缩到2微秒。
虽然FusionStack是初创公司,但产品却不是基于某个开源软件改的。因为在2007年的时候没有任何东西可以用。其产品是一个分布式元数据的加工,是有元数据的。比较有意思是社区的开源版本软件定义存储绝大部分都是采用某种改进的模型,没有元数据。我们看到比较多的商业软件带元数据比较多一些。为什么有这个分歧,我们认为在2007年前后Hadoop主导分布式的时候,大家对一些数据不满意,纷纷设计新的模型。就FusionStack的角度来看,对于一个分布式块存储来说,分布式元数据足以应对生产需求,分布式元数据带来一些好处,比如说本地化。
之前是逻辑布局,这是物理布局,物理布局与很多存储厂商交流的时候,都说与传统架构有一致性,其实就是这样。FusionStack的设计是介于分布式存储和传统存储之间的模型。首先我们考虑的是保证你能够满足传统存储模型的一致性的性能,然后才是分布式问题。我们有一个微控制器,每一个卷会有一个控制器,因为它有控制器管理的元数据。这个控制器记录了它的副本位置,我们的副本是分成1兆大小的块,打散存放在集群中。每卷一个控制器,这个控制器的位置随着你的虚拟机的迁移进行迁移。