
由腾讯云基础产品中心、腾讯架构平台部组成的腾讯云FPGA联合团队,在这里介绍国内首款FPGA云服务器的工程实现深度学习算法(AlexNet),讨论深度学习算法FPGA硬件加速平台的架构。
背景是这样的:在1 月 20 日,腾讯云推出国内首款高性能异构计算基础设施——FPGA 云服务器,将以云服务方式将大型公司才能长期支付使用的 FPGA 普及到更多企业,企业只需支付相当于通用CPU约40%的费用,性能可提升至通用CPU服务器的30倍以上。具体分享内容如下:
1.综述
2016年3月份AI围棋程序AlphaGo战胜人类棋手李世石,点燃了业界对人工智能发展的热情,人工智能成为未来的趋势越来越接近。
人工智能包括三个要素:算法,计算和数据。人工智能算法目前最主流的是深度学习。计算所对应的硬件平台有:CPU、GPU、FPGA、ASIC。由于移动互联网的到来,用户每天产生大量的数据被入口应用收集:搜索、通讯。我们的QQ、微信业务,用户每天产生的图片数量都是数亿级别,如果我们把这些用户产生的数据看成矿藏的话,计算所对应的硬件平台看成挖掘机,挖掘机的挖掘效率就是各个计算硬件平台对比的标准。
最初深度学习算法的主要计算平台是 CPU,因为 CPU 通用性好,硬件框架已经很成熟,对于程序员来说非常友好。然而,当深度学习算法对运算能力需求越来越大时,人们发现 CPU 执行深度学习的效率并不高。CPU 为了满足通用性,芯片面积有很大一部分都用于复杂的控制流和Cache缓存,留给运算单元的面积并不多。这时候,GPU 进入了深度学习研究者的视野。GPU原本的目的是图像渲染,图像渲染算法又因为像素与像素之间相对独立,GPU提供大量并行运算单元,可以同时对很多像素进行并行处理,而这个架构正好能用在深度学习算法上。
GPU 运行深度学习算法比 CPU 快很多,但是由于高昂的价格以及超大的功耗对于给其在IDC大规模部署带来了诸多问题。有人就要问,如果做一个完全为深度学习设计的专用芯片(ASIC),会不会比 GPU 更有效率?事实上,要真的做一块深度学习专用芯片面临极大不确定性,首先为了性能必须使用最好的半导体制造工艺,而现在用最新的工艺制造芯片一次性成本就要几百万美元。去除资金问题,组织研发队伍从头开始设计,完整的设计周期时间往往要到一年以上,但当前深度学习算法又在不断的更新,设计的专用芯片架构是否适合最新的深度学习算法,风险很大。可能有人会问Google不是做了深度学习设计的专用芯片TPU?从Google目前公布的性能功耗比提升量级(十倍以上的提升)上看,还远未达到专用处理器的提升上限,因此很可能本质上采用是数据位宽更低的类GPU架构,可能还是具有较强的通用性。这几年,FPGA 就吸引了大家的注意力,亚马逊、facebook等互联网公司在数据中心批量部署了FPGA来对自身的深度学习以云服务提供硬件平台。
FPGA 全称「可编辑门阵列」(Field Programmable Gate Array),其基本原理是在 FPGA 芯片内集成大量的数字电路基本门电路以及存储器,而用户可以通过烧写 FPGA 配置文件来来定义这些门电路以及存储器之间的连线。这种烧入不是一次性的,即用户今天可以把 FPGA 配置成一个图像编解码器,明天可以编辑配置文件把同一个 FPGA 配置成一个音频编解码器,这个特性可以极大地提高数据中心弹性服务能力。所以说在 FPGA 可以快速实现为深度学习算法开发的芯片架构,而且成本比设计的专用芯片(ASIC)要便宜,当然性能也没有专用芯片(ASIC)强。ASIC是一锤子买卖,设计出来要是发现哪里不对基本就没机会改了,但是 FPGA 可以通过重新配置来不停地试错知道获得最佳方案,所以用 FPGA 开发的风险也远远小于 ASIC。
2.Alexnet 算法分析
2.1 Alexnet模型结构
Alexnet模型结构如下图2.1所示
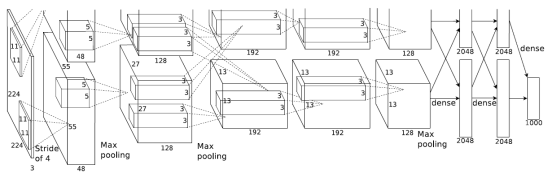 图2.1 Alexnet模型
图2.1 Alexnet模型
模型的输入是3x224x224大小图片,采用5(卷积层)+3(全连接层)层模型结构,部分层卷积后加入Relu,Pooling 和Normalization层,最后一层全连接层是输出1000分类的softmax层。如表1所示,全部8层需要进行1.45GFLOP次乘加计算,计算方法参考下文。
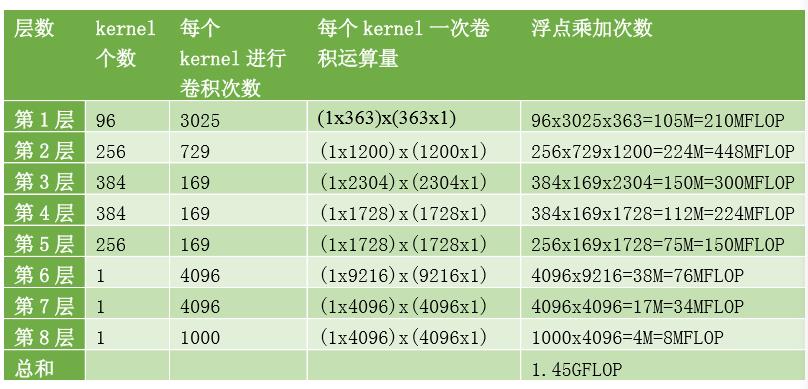 表2.1 Alexnet浮点计算量
表2.1 Alexnet浮点计算量
2.2Alexnet 卷积运算特点
Alexnet的卷积运算是三维的,在神经网络计算公式: y=f(wx+b) 中,对于每个输出点都是三维矩阵w(kernel)和x乘加后加上bias(b)得到的。如下图2.2所示,kernel的大小M=Dxkxk,矩阵乘加运算展开后 y = x[0]*w[0]+ x[1]*w[1]+…+x[M-1]*w[M-1],所以三维矩阵运算可以看成是一个1x[M-1]矩阵乘以[M-1]x1矩阵。
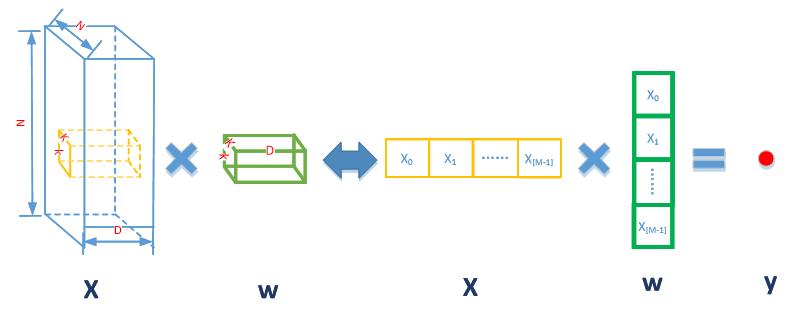
图2.2 Alexnet三维卷积运算
每个三维矩阵kernel和NxN的平面上滑动得到的所有矩阵X进行y=f(wx+b)运算后就会得到一个二维平面(feature map)如图2.3 所示。水平和垂直方向上滑动的次数可以由 (N+2xp-k)/s+1 得到(p为padding的大小),每次滑动运算后都会得到一个点。
a)N是NxN平面水平或者垂直方向上的大小;
b)K是kernel在NxN平面方向上的大小kernel_size;
c)S是滑块每次滑动的步长stride;
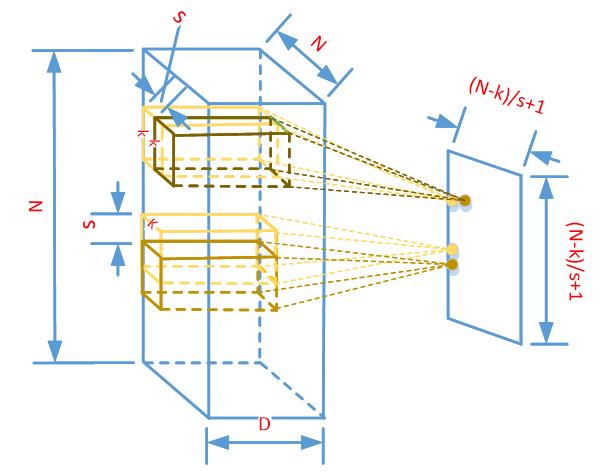
图2.3 kernel进行滑窗计算
Kernel_num 个 kernel 经过运算后就会得到一组特征图,重新组成一个立方体,参数H = Kernel_num,如图2.4所示。这个卷积立方体就是卷积所得到的的最终输出结果。
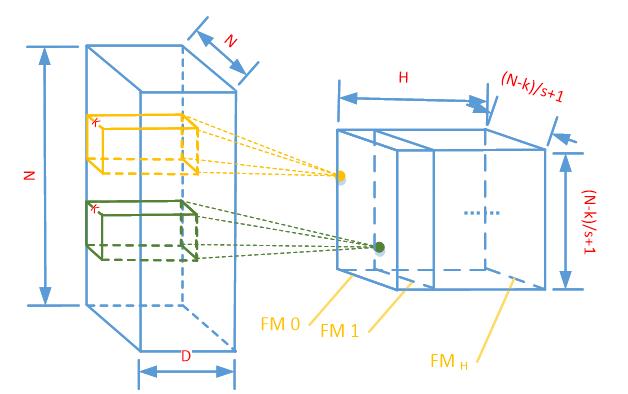
图2.4 多个kernel进行滑窗计算得到一组特征图
3.AlexNet模型的FPGA实现
3.1 FPGA异构平台
图3.1为异构计算平台的原理框图,CPU通过PCIe接口对FPGA传送数据和指令,FPGA根据CPU下达的数据和指令进行计算。在FPGA加速卡上还有DDR DRAM存储资源,用于缓冲数据。
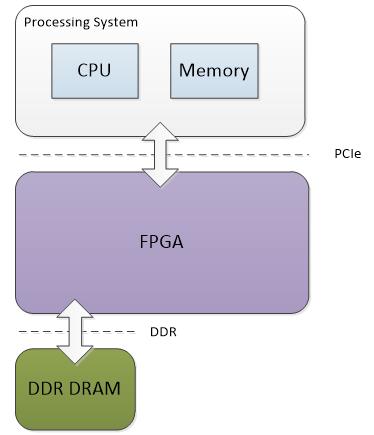
图3.1 FPGA异构系统框图
3.2 CNN在FPGA的实现
3.2.1 将哪些东西offload到FPGA计算?
在实践中并不是把所有的计算都offload到FPGA,而是只在FPGA中实现前5层卷积层,将全连接层和Softmax层交由CPU来完成,主要考虑原因:
(1) 全连接层的参数比较多,计算不够密集,要是FPGA的计算单元发挥出最大的计算性能需要很大的DDR带宽;
(2) 实际运用中分类的数目是不一定的,需要对全连阶层和Softmax层进行修改,将这两部分用软件实现有利于修改。
3.2.2 实现模式
Alexnet的5个卷积层,如何分配资源去实现它们,主要layer并行模式和layer串行模式:
(1) Layer并行模式:如图3.2所示,按照每个layer的计算量分配不同的硬件资源,在FPGA内同时完成所有layer的计算,计算完成之后将计算结果返回CPU。优点是所有的计算在FPGA中一次完成,不需要再FPGA和DDR DRAM直接来回读写中间结果,节省了的DDR带宽。缺点就是不同layer使用的资源比较难平衡,且layer之间的数据在FPGA内部进行缓冲和格式调整也比较难。另外,这种模式当模型参数稍微调整一下(比如说层数增加)就能重新设计,灵活性较差。
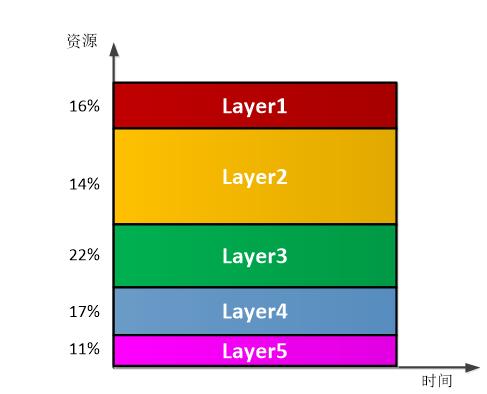 图3.2 layer并行模式下资源和时间分配示意图
图3.2 layer并行模式下资源和时间分配示意图
(2)Layer串行模式:如图3.3所示,在FPGA中只实现完成单个layer的实现,不同layer通过时间上的复用来完成。优点是在实现时只要考虑一层的实现,数据都是从DDR读出,计算结果都写回DDR,数据控制比较简单。缺点就是因为中间结果需要存储在DDR中,提高了对DDR带宽的要求。
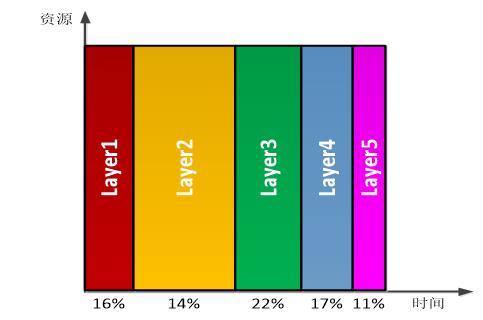
图3.3 layer并行模式下资源和时间分配示意图
我们的设计采用了是Layer串行的模式,数据在CPU、FPGA和DDR直接的交互过程如图3.4所示。
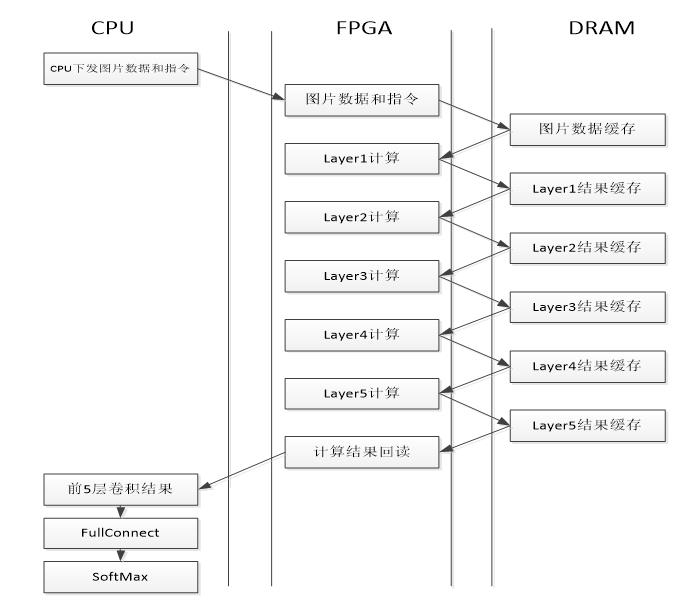
图3.4 计算流程图
3.2.3 计算单个Layer的PM(Processing Module)设计
如图3.5所示,数据处理过程如下,所有过程都流水线进行:
(1)Kernel和Data通过两个独立通道加载到CONV模块中;
(2)CONV完成计算,并将结果存在Reduce RAM中;
(3)(可选)如果当前layer需要做ReLU/Norm,将ReLU/Norm做完之后写回Reduce RAM中;
(4)(可选)如果当前layer需要做Max Pooling,将Max做完之后写回Reduce RAM中;
(5)将计算结果进行格式重排之后写回DDR中。
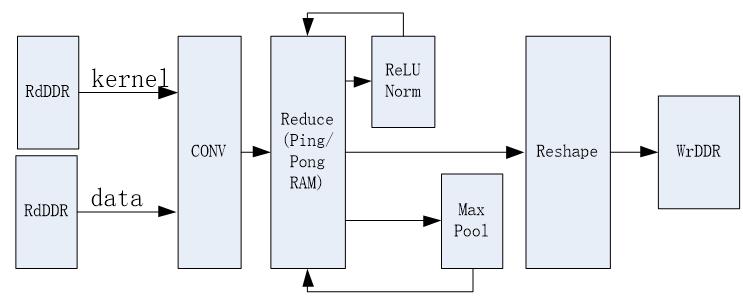 图3.5 Processing Module的结构框图
图3.5 Processing Module的结构框图
3.2.4 CONV模块的设计
在整个PM模块中,最主要的模块是CONV模块,CONV模块完成数据的卷积。
由图3.6所示,卷积计算可以分解成两个过程:kernel及Data的展开和矩阵乘法。
Kernel可以预先将展开好的数据存在DDR中,因此不需要在FPGA内再对Kernel进行展开。Data展开模块,主要是将输入的feature map按照kernel的大小展开成可以同kernel进行求内积计算的矩阵。数据展开模块的设计非常重要,不仅要减小从DDR读取数据的数据量以减小DDR带宽的要求,还要保证每次从DDR读取数据时读取的数据为地址连续的大段数据,以提高DDR带宽的读取效率。
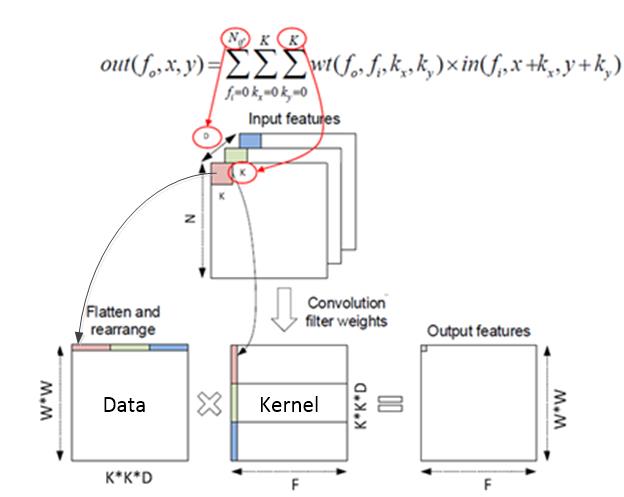 图3.6 卷积过程示意图
图3.6 卷积过程示意图
图3.7为矩阵乘法的实现结构,通过串联乘加器来实现,一个周期可以完成一次两个向量的内积,通过更新端口上的数据,可以实现矩阵乘法。

图3.7 矩阵乘法实现结构
展开后的矩阵比较大,FPGA因为资源结构的限制,无法一次完成那么的向量内积,因此要将大矩阵的乘法划分成几个小矩阵的乘加运算。拆分过程如图3.8所示。
假设大矩阵乘法为O= X*W,其中,输入矩阵X为M*K个元素的矩阵;权重矩阵W为K*P个元素的矩阵;偏置矩阵O为M*P个元素的矩阵;
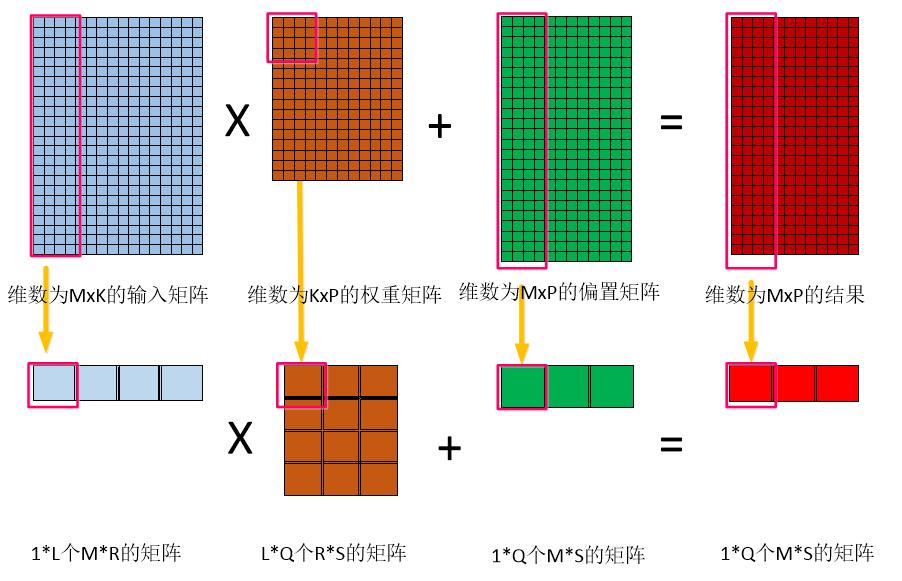 图3.8 大矩阵乘法的拆分过程
图3.8 大矩阵乘法的拆分过程
R = K/L,如果不能整除输入矩阵,权重矩阵和偏置通过补零的方式将矩阵处理成可以整除;
S = P/Q,如果不能整除将权重矩阵和偏置矩阵通过补零的方式将矩阵处理成可以整除;
3.2.5实现过程的关键点
(1) 决定系统性能的主要因素有:DSP计算能力,带宽和片内存储资源。好的设计是将这三者达到一个比较好的平衡。参考文献[2]开发了roofline性能模型来将系统性能同片外存储带宽、峰值计算性能相关联。
(2) 为了达到最好的计算性能就是要尽可能地让FPGA内的在每一个时钟周期都进行有效地工作。为了达到这个目标,CONV模块和后面的ReLU/Norm/Pooling必须能异步流水线进行。Kernel的存储也要有两个存储空间,能对系数进行乒乓加载。另外,由于计算是下一层的输入依赖于上一层的输出,而数据计算完成写回DDR时需要一定时间,依次应该通过交叠计算两张图片的方式(Batch=2)将这段时间通过流水迭掉。
(3) 要选择合适的架构,是计算过程中Data和Kernel只要从DDR读取一次,否则对DDR带宽的要求会提高。
3.3 性能及效益
如图3.9所示采用FPGA异构计算之后,FPGA异构平台处理性能是纯CPU计算的性能4倍,而TCO成本只是纯CPU计算的三分之一。本方案对比中CPU为2颗E5-2620,FPGA为Virtex-7 VX690T,这是一个28nm器件,如果采用20nm或16nm的器件会得到更好的性能。
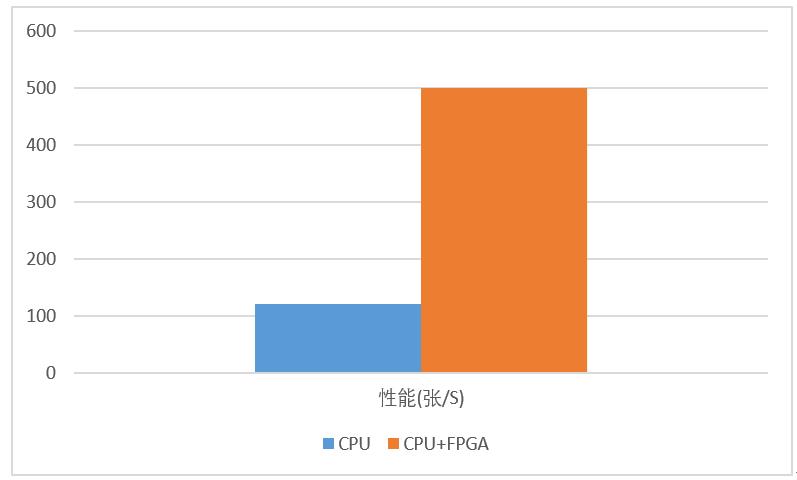 图 3.9 计算性能对比
图 3.9 计算性能对比
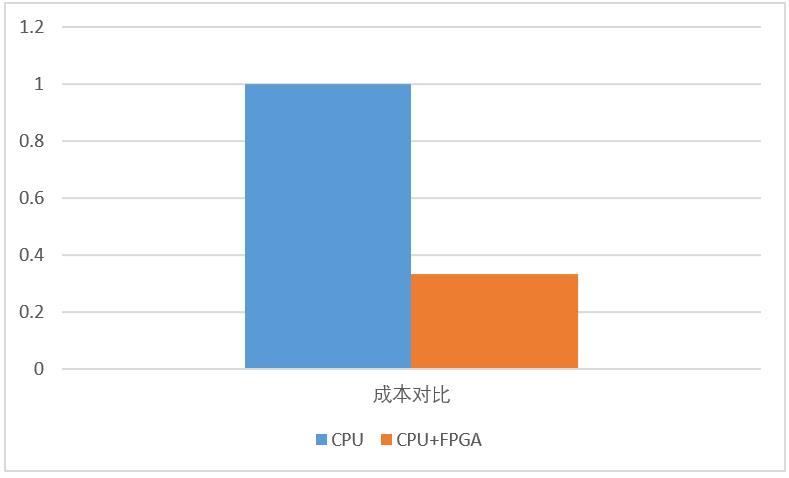
图 3.10 归一化单位成本对比
图3.11为实际业务中利用FPGA进行加速的情况,由图中数据可知FPGA加速可以有效降低成本。
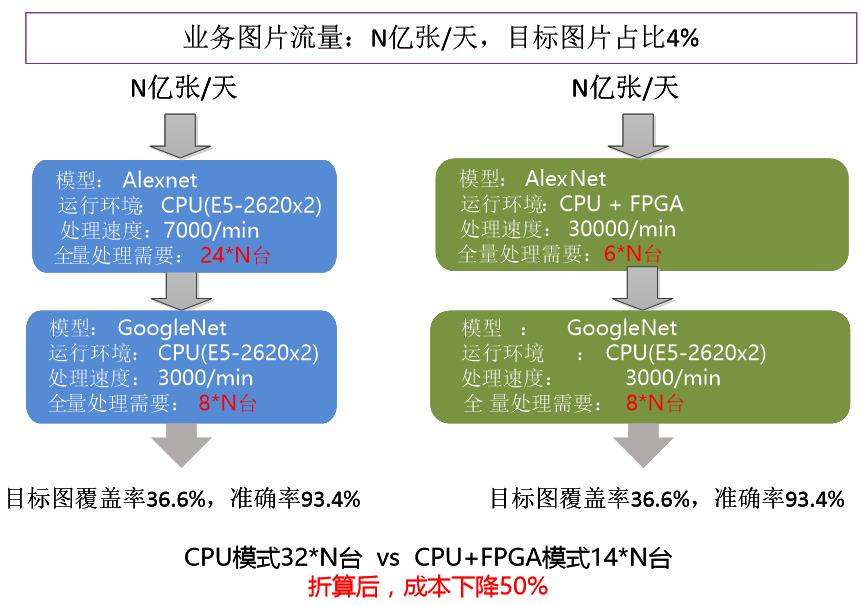
图3.11 某实际业务中的性能和成本对比
参考文献
[1] Alex Krizhevsky. ImageNet Classification with Deep Convolutional Neural Networks
[2] C. Zhang, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks. In ACM ISFPGA 2015.
[3] P Gysel, M Motamedi, S Ghiasi. Hardware-oriented Approximation of Convolutional Neural Networks. 2016.
[4] Song Han,Huizi Mao,William J. Dally.DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING. Conference paper at ICLR,2016







