在《存储极客:SPC-1负载分析与AFA寿命评估》一文中,
我们讨论了如何从SSD耐用性角度规划match存储系统的配置。
今天再谈谈闪存性能的规划,包括测试和配置选型两个方面。
存储极客设计了下面这个流程:
应用性能收集/评估 >>存储设备模拟测试 >>后续分析
怎样把前两个环节打通,是问题的关键。
某家存储厂商性能收集/分析工具的截图,算是同类中的一个代表吧。
测试准备
全闪存阵列配置实践
我先讲一些基础的东西,包括SAN存储网络建议怎么连、划Zone的规则和HBA卡参数等。针对的应用环境是数据库——Oracle OLTP。
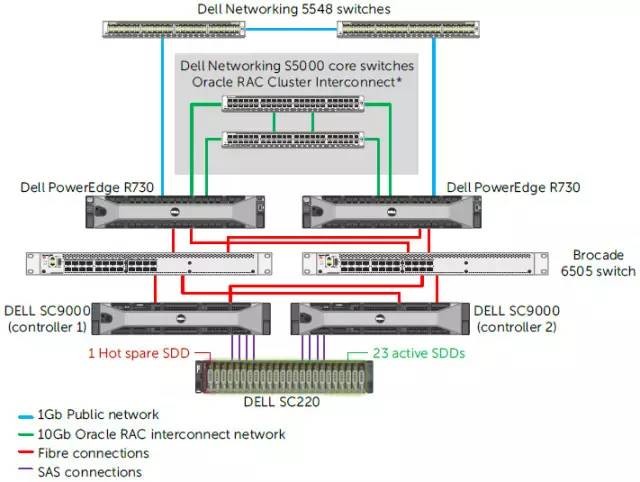
图片引用自《Accelerating Oracle OLTP with Dell SC Series All-Flash Arrays》,以下同。
上面是一个典型的传统Oracle RAC+集中式存储阵列+SAN网络的配置。其中以Dell SC9000为例,双控同时连接到后端的SC220 SAS驱动器机箱,里面满配24个SSD中有一块热备盘。
1. 存储网络最佳配置
存储和PowerEdge R730服务器之间有2个Brocade 6505 16Gb FC交换机。在服务器FC HBA驱动设置上,包括timeouts(超时)和QD(队列深度)的建议如下:
To adjust the values, the following lines were added to file /etc/modprobe.d/qla2xxx.conf.
options qla2xxx qlport_down_retry=5
options qla2xxx ql2xmaxqdepth=
由于是冗余的本地存储连接,每条路径的超时重试时间为5秒。
Once the system has restarted, verify that the configuration changes have taken effect:
# cat /sys/module/qla2xxx/parameters/qlport_down_retry
5
# cat /sys/module/qla2xxx/parameters/ql2xmaxqdepth
32
FC HBA的队列深度建议设为32。这部分都是以QLogic光纤卡为例,如果换Emulex也是同样的道理。
下面我们看看Zone的配置。
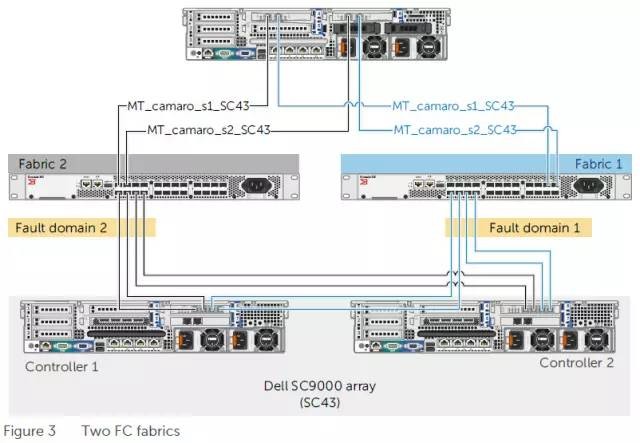
以左右两边FC交换机为中心拓扑出2个存储网络故障域,如果是iSCSI就换成以太网交换机。
上图以其中一台服务器为例。2块FC HBA卡上共有4个端口,camaro代表主机名,s1/s2分别对应左右两边的HBA卡。每块HBA都同时连接到2台FC交换机,然后可以看到两个存储控制器上的全部主机接口。
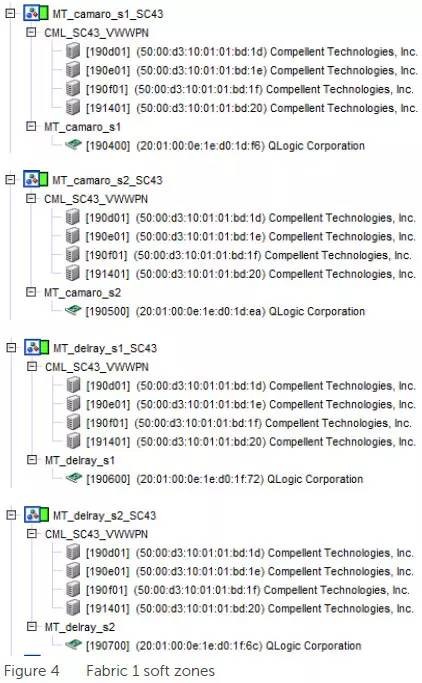
上图是故障域Fabric 1中的4个Zone。前面2个Zone包含服务器camaro上两块HBA卡靠左边的端口,它们都可以看到双存储控制器靠左的2个主机接口。如果感觉上面两张图的对应关系还不够清楚,不妨再看看下面这个表:
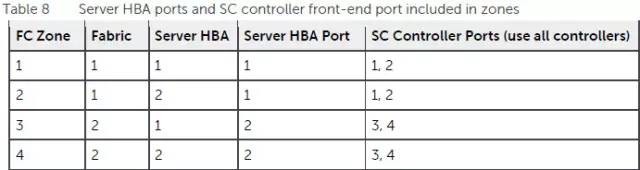
如上表,在一台服务器上,每块HBA卡的2个口分别可以看到同Zone中所有存储控制器上的1,2 / 3,4端口。目的大家也都清楚:为了实现SAN网络连接的高可用、有效利用带宽,隔离以降低管理上的复杂性。
2、宽条带化和Thin-Provisioning注意事项
本文测试的SC9000配置了24个1.92TB读密集型3D NAND TLC SSD,2MB的“数据页面”就是Dell SC(Compellent)的宽条带化RAID打散粒度。如果做自动分层存储的话,这个数据调度的粒度也是2MB,靠同一套元数据管理机制来实现的。

RAID 10-DM就是三重镜像,可以理解为存储控制器本地三副本,最大保障数据可靠性,同时没有分布式存储多副本的网络开销。
因为传统RAID 10的双盘故障风险在宽条带化存储池中被放大了,而RAID 6的随机写性能又不够理想,RAID 10-DM给了用户更多一种选择。
以Dell SC为例,当SSD/HDD容量、个数在一定范围内会推荐采用RAID 10-DM镜像,如果超出一定水平则强制要求镜像保护必须为RAID 10-DM,这是为数据安全性考虑的。
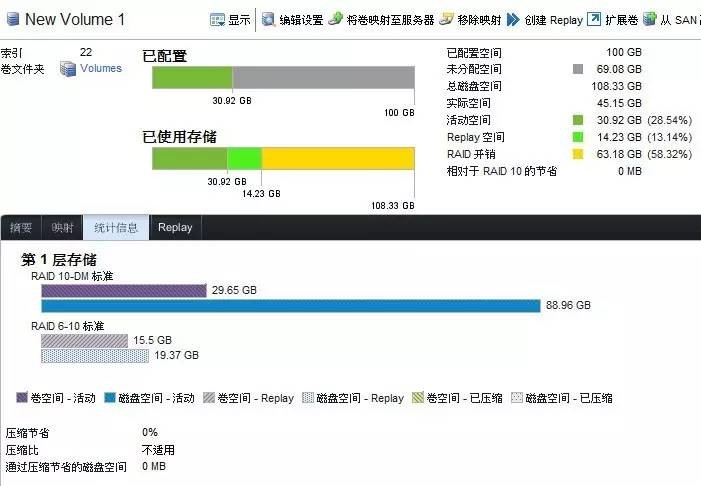
存储管理界面截图引用自《工程师笔记:SCv2000试用之RAID分层+快照》一文。
有没有兼顾性能和容量利用率的方式呢?除了在自动分层存储中将不同驱动器配置为不同RAID之外,在单一类型驱动器的存储池中,Dell SC仍然支持跨两种RAID级别进行分层存储,结合镜像和奇偶校验各自的优点。其原理是利用周期快照“冻结”只读数据块并改为RAID 5/6方式存放,这种读写分离的思想同样也能用于RI(读密集型)SSD和WI(写密集型)SSD之间的自动分层。
上图只是一个举例,由于本文是模拟OLTP应用环境的读写混合测试,实际都是在性能更好的RAID 10-DM配置进行。
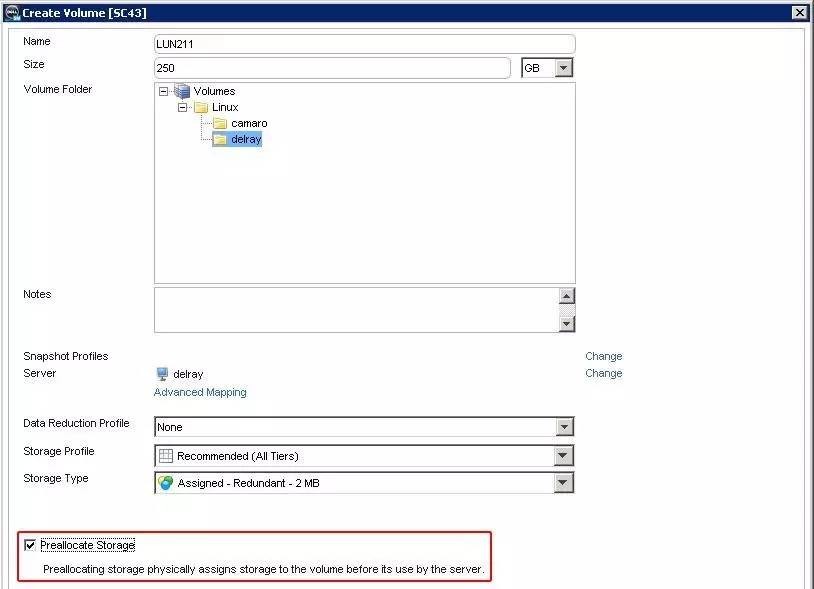
在有元数据分配数据条带的情况下,精简配置(Thin-Provisioning)就成为原生的特性。但我也看到有同行朋友反映由于用户没做好容量预警,存储池被写爆的状况。当然这也是有办法避免的,比如上图所示创建卷时“预分配存储”选项。
需要注意的是,这个选项在我们的性能测试中另有深意,简单说也可以解释为“POC防作弊”。由于我们使用的是Oracle ORION测试工具,其写入的数据为全零,如果是没有预分配的Thin卷,有个智能技术(零检测)——不会真正向SSD/HDD盘写入数据。如果这样的话,显然我们看不到真实的性能数据。
混合读写测试结果
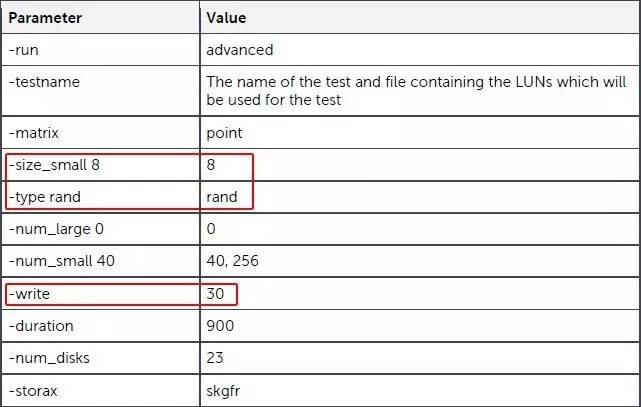
ORION是一个Oracle官方模拟数据库存储IO的测试工具。OTLP的典型负载为8KB随机读写,这里通过参数指定读/写比例为70:30。
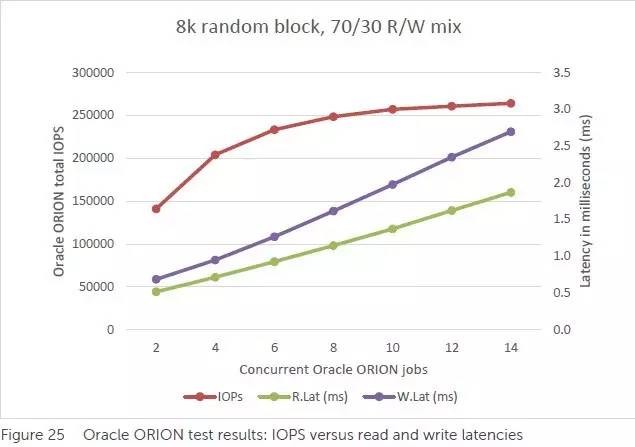
测试结果如上表。深红色折线代表IOPS,我们看到当并发ORION任务达到14时,8KB混合读写IOPS超过250,000。
根据这个结果可以大致估算出100%读IOPS能跑多高吗?大家先看看我下面的方法是否合理:
估算方法一:在257,313 IOPS中有30%的写IO,考虑到RAID 10落在SSD盘上会有写放大,那么把这些写的时间换成读操作应该能快不少,保守估计跑到40万IOPS以上问题不大。
问题1:
闪存盘读比写快,那么上面的估计是否保守了?
我的答案是yes,但具体低估了多少,除了实测之外另有一种推算方法可以考虑。
问题2:
前后端存储网络、连接会不会成为瓶颈?
按照40万8KB IOPS来计算,折合3200MB/s的带宽。具体到我们测试环境是端到端16Gb FC SAN网络,4条交换机上行链路不应成为瓶颈;后端每条SAS线缆12Gb x4 lane也是如此。
问题3:
我用不了这么多个SSD,换个配置性能可以按比例缩放计算吗?
以我在《SSD寿命与闪存阵列选型(上)为什么关注DWPD?》中引用的Dell SC4020 SPC-1性能测试结果为例,6块SSD超过11万IOPS,平均每个接近2万了。
当然,SPC-1测试的混合工作负载数据块大小和读写比例(《存储极客:SPC-1负载分析与AFA寿命评估》中曾有详细分析)与本文的ORION有些不同,另外6块480GB SSD用的是RAID 10双盘镜像,所以只是个参考对比。考虑到SC9000比SC4020要高端,其性能上限应该也会较高。
估算方法二:这个我也是看到不只一家存储厂商使用。大家知道SSD驱动器有个制造厂商的IOPS性能指标,而在阵列中的发挥会有不小的折扣。于是人们就在存储系统中测试各种单盘RAID 0的性能,以此为基础来估算不同数量SSD配置能够达到的IOPS,当然如果是写性能还要考虑RAID惩罚的影响。
关于方法二我就不详细举例了,有兴趣了解的朋友可以找相关人士咨询。
性能分析收集工具
了解存储需求的助手

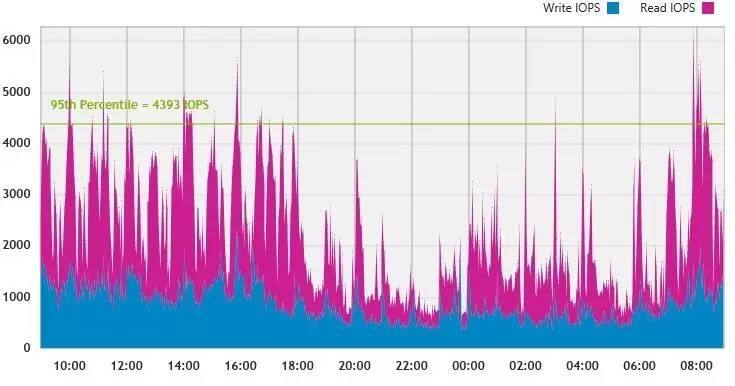
我在本文开头列出过一张IOPS截图,上面这个为主机上监测到访问存储的带宽,对应的具体存储配置未知。它们都是使用DPACK(Dell Performance Analysis Collection)软件收集的。
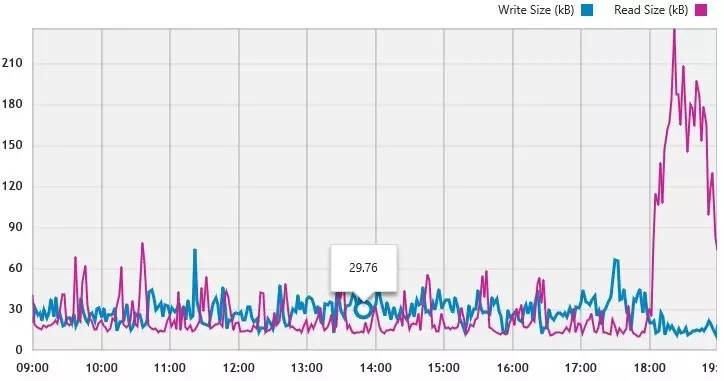
读写I/O尺寸与应用类型相关,比如Oracle OLTP典型的是8KB,上面这个比较像Exchange邮件服务器。另外我还看到过有的存储厂商宣称32KB优化对实际应用的意义较大。

延时是另一个关乎应用体验的重要指标,这个与I/O请求大小有很大关系。比如上面图表大部分时间写延迟很低,应该有存储Cache的效果在里面,绝大多数I/O都在20ms以内,属于Exchange正常接受的范围。至于蓝色的波峰,不排除是有个大数据块I/O,也可能是由于持续写入压力大,缓存数据满了落盘导致。
另外需要说明的是,如果按照Oracle OLTP的8KB访问习惯,平均延时通常比上面图中要低。而存储I/O与数据库事物交易延时并不是一回事,因为根据事物复杂度不同,每笔事物中包含的I/O数量也是不同的,而且还有计算的开销要考虑。因此,我们不能从应用端一看到几十ms的延时,就全都怪存储不给力。
在用户现有的应用系统中收集到上述性能数据之后,再加上我在本文中介绍的方法,存储售前顾问就可以更有针对性地推荐阵列配置。现在全闪存逐渐开始流行,而有些情况下用固态混合(SSD+HDD)分层存储也是不错的选择。如果用户看重容量和性价比,或者想保留更多的历史快照数据,能够兼容传统硬盘的阵列就显出优势了。