5月11日-13日,国内备受关注的数据库技术盛会——2017第八届中国数据库技术大会(DTCC2017)隆重召开,本届大会吸引5000多名IT数据库和互联网人士参加。在数据库内核专场上,腾讯云数据库专家工程师李海翔作为内核专场主持人和专家组成员,代表腾讯云进行了题为《数据库的并发控制技术深度探索》主题演讲。

李海翔,从事数据库研发、数据库测试与技术管理等工作10余年,擅长于 PostgreSQL和MySQL等开源数据库的内核与架构,现为腾讯云数据库专家工程师。
并发控制技术是数据库的核心技术,在本次主题演讲中,李海翔主要对数据库并发控制技术进行深入浅出的解析,同时分享腾讯云数据库CDB在金融业务方面的一些心得。下面是李海翔演讲的摘录:
今天,我们来一起聊聊数据库的并发控制技术。可以说,没有事务处理,数据库就不能算是数据库;没有并发控制技术,事务处理也只是一个名词而已。毫不夸张地说,并发控制技术是数据库的核心技术。
数据库的四大特性就是ACID,A是原子性,C是一致性,I是隔离性,D是持久性。
我们今天所讲的并发控制技术,关联着这四个特性中的C和I特性。为什么这么说呢?因为没有并发控制,数据库的一致性就会被破坏。没有并发控制,也就无从谈起隔离性,就会出现数据异常。在并发控制技术下数据的正确得到首先保证,然后通过隔离和其他并发控制技术保证性能。
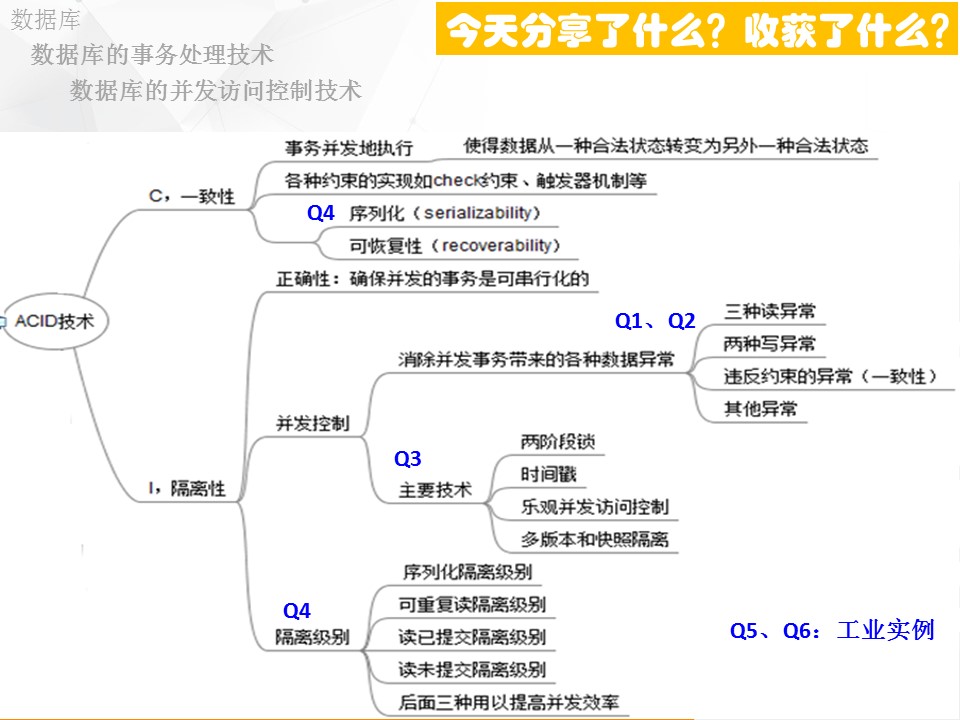
因此,我们今天把并发控制技术的前因后果,通过6个小节和大家聊一聊。

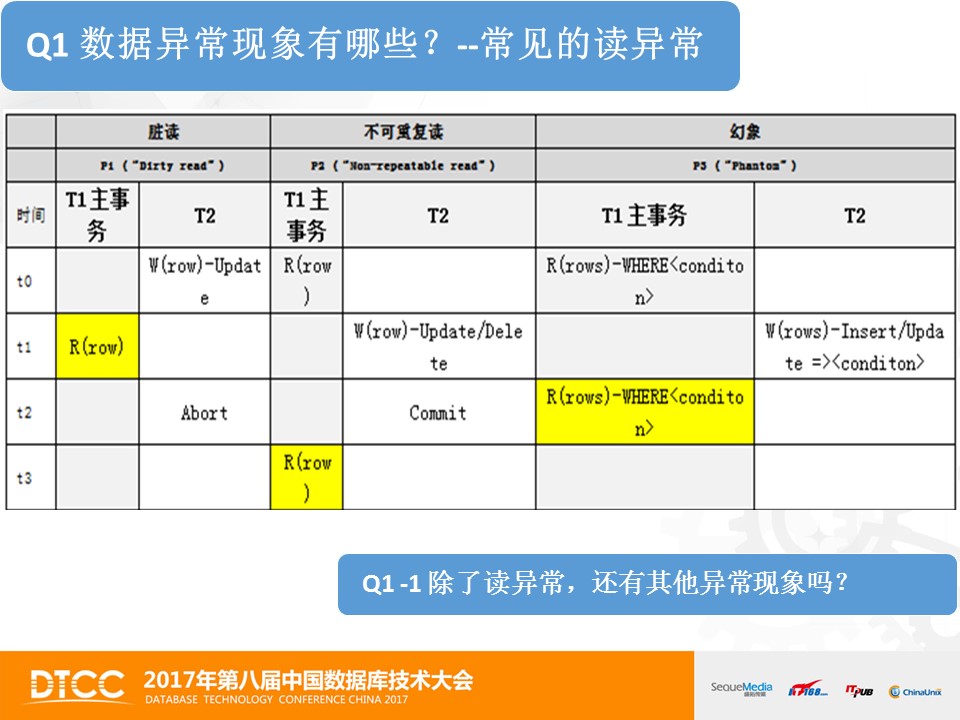
首先,我们来共同看第一个问题:数据异常现象有哪些?PPT中列出了大家都熟悉的三种读数据异常,分别是脏读、不可重复读、幻读。
以脏读举例,第一步,T2事务修改了数据行row;第二步,T1事务对同一个数据行row读取;第三步,T2事务回滚。这对于事务T1而言,读到的数据是将被回滚的数据,这就是脏读。
有朋友会问,脏读,也没有什么大不了的吧。试想一下,一个骗子T2转帐1000元给事务T1,事务T1检查自己的账户,入账了1000元,然后事务T1把一件衣服卖给了骗子T2,之后骗子T2拿到衣服后回滚了转账1000元的操作,然后逃之夭夭了。事务T1既没有拿到钱还丢失了衣服,损失很大。越是要求高的业务,越需要避免这样的异常发生。
这三个读异常现象,是大家熟知的,也是SQL标准所定义的数据异常现象。那么,除了读异常,还有其他的数据异常吗?
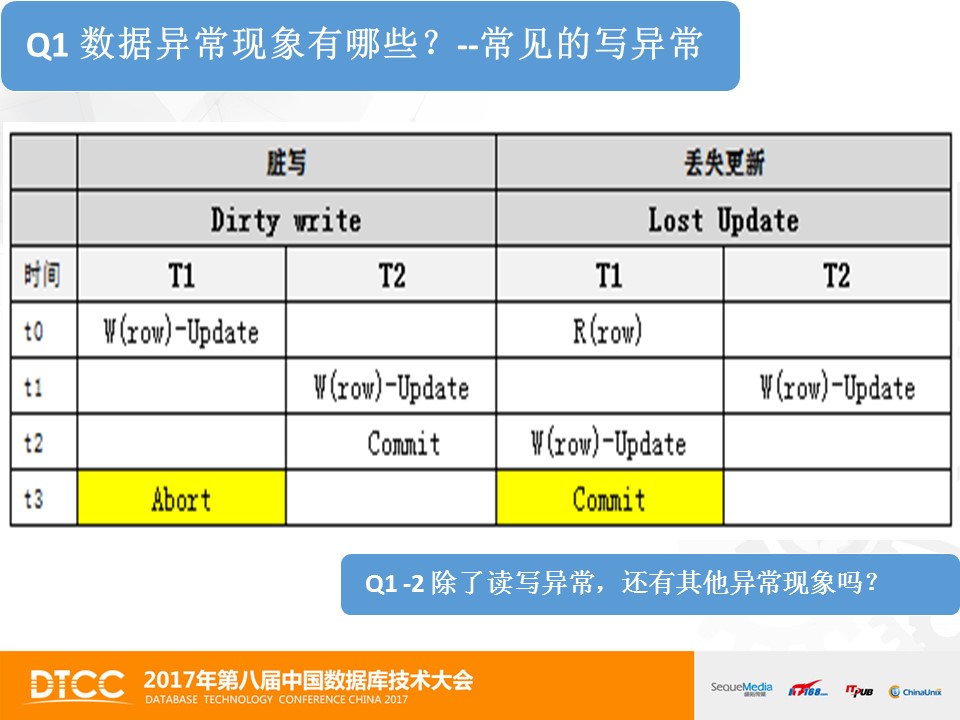
脏写和丢失更新,也是常见的写异常之一。以脏写举例。第一步,事务T1修改数据行row;第二步,事务T2也修改数据行row并提交,数据修改生效。事务T2认为自己的操作是成功的。但不幸的事情发生了,第三步,事务T1回滚了,用旧值替换了被事务T2写过的值。这意味着事务T2存入银行的钱,丢失了,因为帐本上只记着第一步事务T1读取的数据值。这就是写数据发生的数据不一致的现象。
那么,除了这些读和写异常,还有其他的数据异常吗?
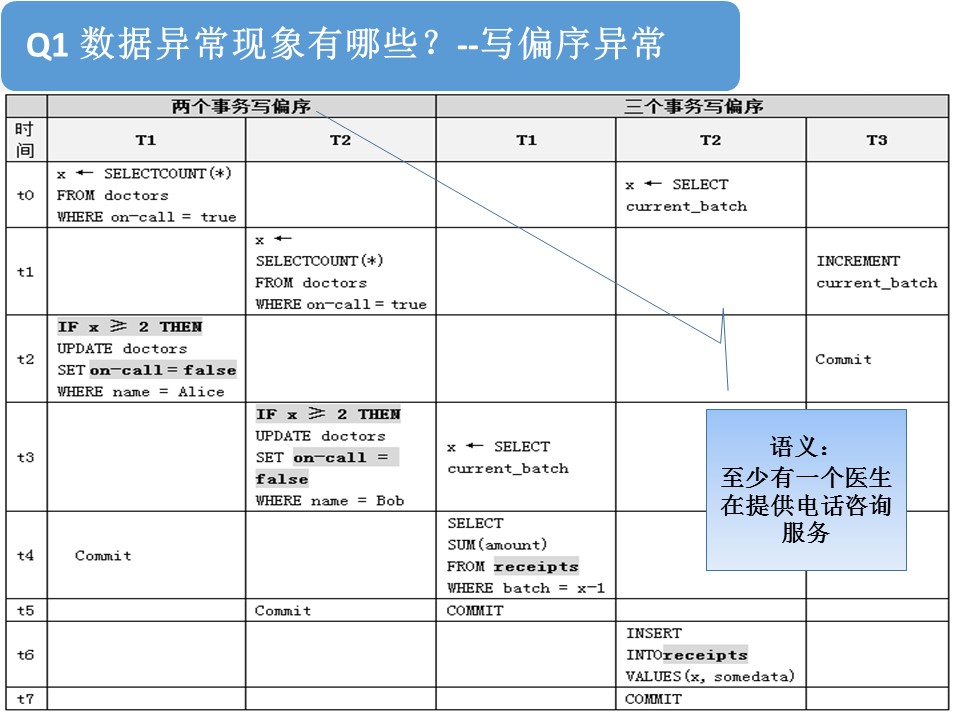
接下来,我们继续介绍两种写偏序异常:两个事务写偏序和三个事务写偏序。
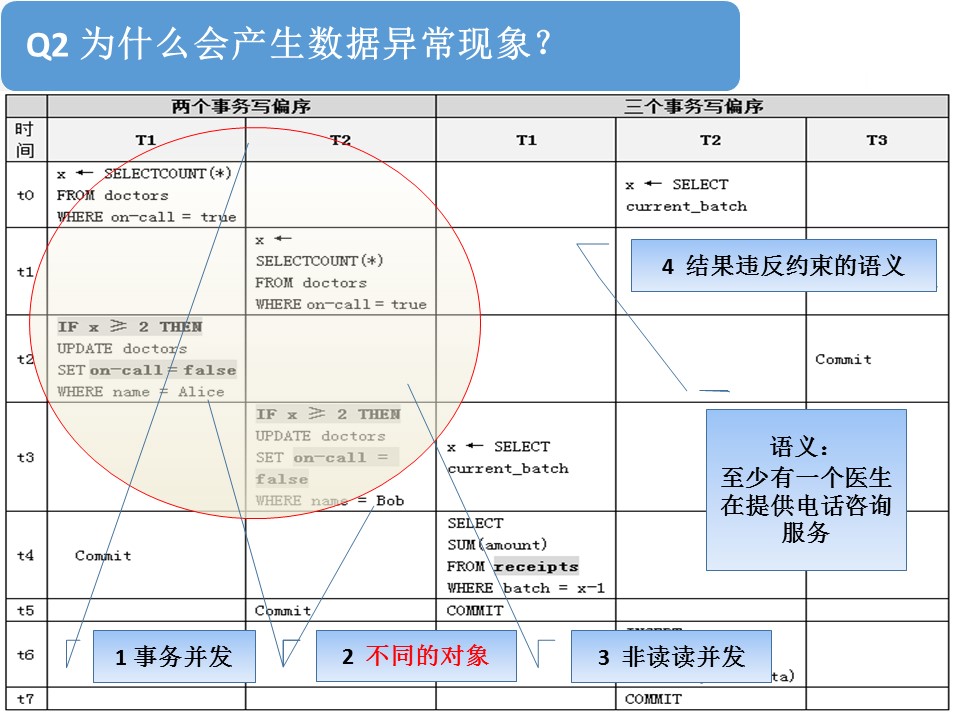
我们来看一下两个事务写偏序。首先,这里有个前提:医院向社会承诺,至少有一名医生对外提供电话咨询服务。但是,如果有多于两个医生在提供电话咨询,则需要某个正在进行电话咨询服务的医生停止服务。
可是,大家看这两个事务。事务T1发现,有两个以上的医生正在提供电话咨询,就请Alice停止电话服务;事务T2也发现有两个以上的医生正在提供电话咨询,就请Bob停止了电话服务。这样,如果执行前只有Alice和Bob正在提供电话服务,这两个事务执行完毕后,没有一个医生在对外提供电话咨询服务了。这就违背了“至少有一名医生对外提供电话咨询服务”的约束前提。这样也是一种数据异常现象。
因为时间关系,这里不一一为大家列举常见的11种数据异常。对于数据库系统而言,如果允许异常发生,那么我们这个依靠数据库做交易的世界就会发生巨大混乱——数据在,账乱了;人活着,钱没了。
而并发控制技术,就能很好的解决上面说的这些问题。

接下来,我们讨论第二个问题:为什么会产生刚才所说的那些数据异常现象?这个问题看似简单,如果能够精准地回答出来,说明对ACID这四个特性和相关的技术理解地非常深刻。我这里解释下,在数据库里,数据操作会被抽象为两种,就是读操作和写操作。读写操作组合在一起,有四种情况,就是这幅图里面的,读读、读写、写读和写写。在数据库里面,只有读读操作,不会引发数据异常,而其他三种,都会引发数据异常。

让我们以刚才所讲过的异常为例,一起来分析一下。大家看,刚才讲过的三种读异常,有个一个共同点,就是存在并发的事务;其次,并发的事务操作的是同一个数据对象。再次并发事务对该数据对象,有写操作。最后,还有一种特殊情况,对于幻读而言,受谓词条件的影响,这时不是操作物理上的同一个已经存在的对象,而是操作谓词限定的同一个范围内的逻辑意义上的对象。我们把第四种情况概括为“谓词的语义”。
这些合起来,造成了三种读数据异常。

写偏序是怎么产生的了?首先,存在并发的事务。其次,并发的事务,操作的不是同一个数据对象,这点和刚才的读异常不同。再次,并发的事务对不同的数据对象,有写操作,没有读读并发。最后,操作结果,违反了“语义前提”。“违反语义”是指操作数据时,需要遵守一个语义前提,例如“至少有一名医生对外提供电话咨询服务”,但是并发操作打破了这个语义前提,出现了没有医生提供咨询的异常现象。
以上概括了数据异常出现的原因。而解决这些数据异常办法就是并发控制技术。这是此次我们分享的第三点:并发控制技术有哪些?
主流的并发控制技术主要包括大家熟知的两阶段锁、基于时间戳的并发控制技术、基于有效性检查的并发控制技术,以及MVCC、CO等技术。

我们来分析并发控制技术。
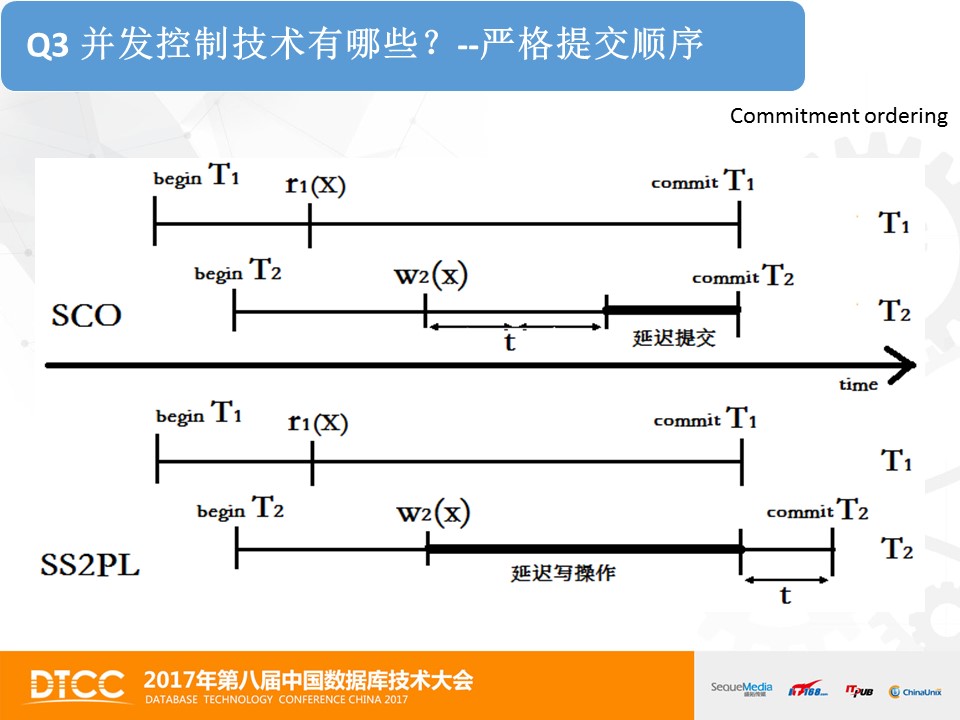
并发控制技术通常采用两阶段锁方案,即把事务划分为加锁阶段和解锁阶段,两个阶段中间的点,被称为封锁点。而光划分为两个阶段还是不够的,还需要确定事务的结束点位于哪里,这个结束点和封锁点的关系是什么。而并发控制协议SS2PL和S2PL的差别在于释放锁的时机不同,即事务的结束点和封锁点是否重合。SS2PL是在事务提交后,才释放读锁和写锁。

如果简单地说数据库使用两阶段锁技术解决了并发访问造成的数据不一致,这样的理解是不够深入的。准确的说,两阶段锁技术中的“SS2PL在读操作上加锁”才能真正解决数据异常。这句话的含义是:使用SS2PL实现了序列化隔离级别,才不会产生第一个问题中所说的各种数据异常现象。就是说通过序列化确保数据的一致性。而序列化隔离级别属于隔离性,我们通过“SS2PL在读阶段加锁”这样的并发控制技术,保证了一致性。
这样,并发控制技术确保了正确性,而其他的隔离级别则在牺牲一定的一致性的情况下,可以提高并发度,提高数据库的性能,所以SQL标准规定了多种隔离级别以在正确性和性能之间求取平衡。因此,并发控制技术就是一致性和隔离性之间的关联点。
而哪些数据库使用了两阶段锁技术了?
MySQL的InnoDB和Informix就是这样依靠SS2PL实现了序列化隔离级别,然后保证了不产生数据异常。
对于数据库系统,数据的一致性,被对应为可串行化调度以实现序列化效果。所以不同的并发控制方法规定了不同的规则以保证序列化。

接下来我们再来简略地讨论一下MVCC 多版本并发控制技术。如PPT所示,MVCC通过元组,版本等来实现控制。
首先,每一个元组,都有一个元组头,上面有两个字段,begin表示元组诞生的时间,end表示元组消亡的时间。
其次,每个元组,可以有多个版本,用pointer这个指针指向不同的版本。大家看,对于名字为John的这个元组,就存在3个版本。第一个版本,生命周期在事务号为10到20之间存活;第二个版本,生命周期在事务号为20到75之间存活;第三个版本,生命周期在事务号为75到现在这个时间短内存活。事务号处于不同的阶段可以看到的版本是不同的。如一个事务的事务号为60,则只能看到第二个版本,不能看到其他版本。

而MVCC技术和其他的并发控制技术,经常结合起来使用,比如,这张表里列的两种MVCC变种,分别是和基于时间戳的、基于封锁技术的相结合的。同样的,这些技术当中,需要解决读写、写写等冲突以确保实现了序列化。数据库经典教材中对这样的算法有详细描述,讲述算法如何避免数据异常如何保证序列化,我们就不再展开讨论。

接下来,需要我们思考和注意的,是这样一个问题:MVCC + 快照算作上述哪一种技术?
这样的问题通常很少被讨论,但是却很容易让人产生困惑。其实,MVCC和快照结合,是另外一种技术变种。MVCC只能表明元组有多个版本,不能保证一个事务对活动的、并发的其他事务的执行情况进行了解。而快照正好在事务启动时,为事务留存了一张当前活动事务的照片,从而能够帮助事务知道哪些事务已经是完成的事务、哪些是正在进行的,哪些应该是将来发生的,一张照片把事务历史长河划分为三个阶段:过去、现在、未来。然后,遵守先提交者获胜或者先更新者获胜等的规则,可实现读已提交和可重复读隔离级别,但不能实现序列化,不能完全避免数据的不一致。PostgreSQL 9.2版本使用SSI技术才实现了真正的序列化,即完全保证了数据的一致性。

另外,还有其他的并发控制技术,比如说,严格提交排序协议,简称为SCO。对于SS2PL,写操作会被读操作互斥, 所以写只能被阻塞,处于等待状态。而SCO则不一样,写操作可以继续进行,只是在提交阶段才进行检查数据修改是否会破坏一致性。对于SCO更为详细的内容,大家可以查阅相关资料。
我们介绍了多种主流的并发控制技术。接下来看第四个问题:为什么并发控制技术能解决数据异常现象?
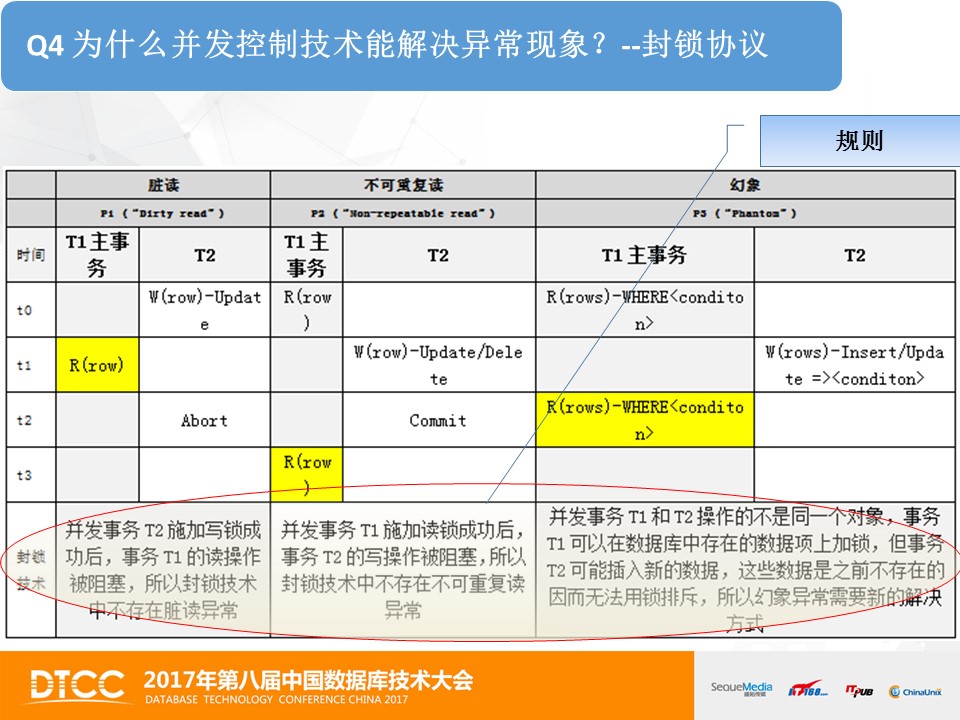
首先我们来分析一下 “基于封锁的并发控制技术”。以脏读为例,并发事务T2施加写锁成功,事务T1的读锁则不能施加成功,事务T1和T2不能并发执行,这样就避免了脏读。
再以不可重复读为例,事务T1施加的读锁,事务T2的写锁则被排斥,只能等待。所以数据不会被修改,事务T1第二次读到的还是没有被修改的数据,所以能够避免不可重复读异常,进而保证数据一致性。
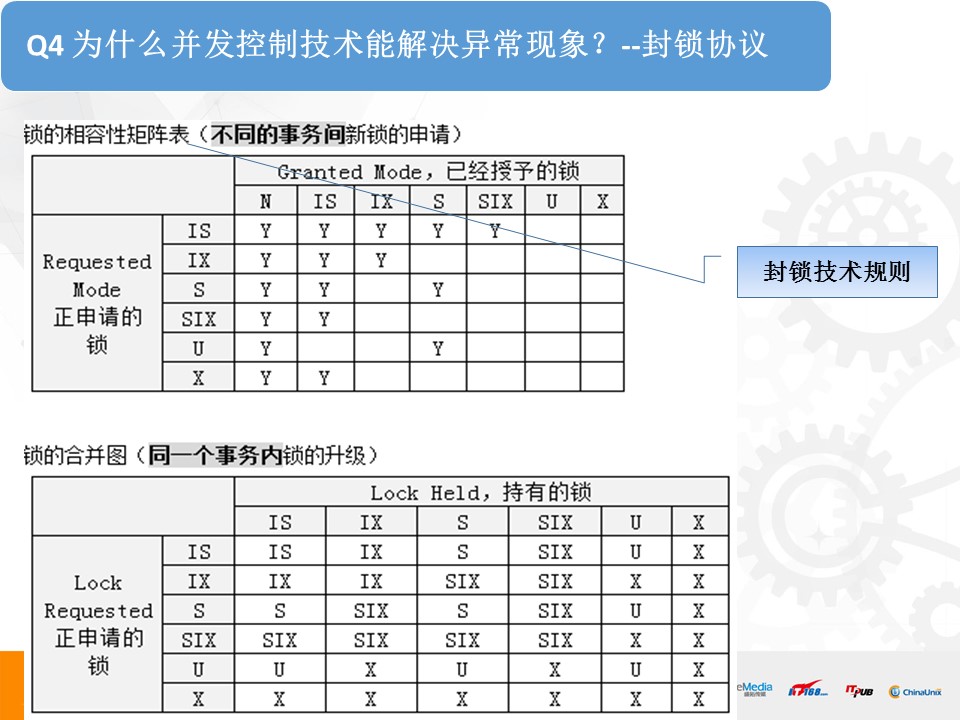
封锁并发控制技术,可以用这两张表来概括,第一张表,是并发的事务之间,锁冲突表,表明了并发事务之间什么样的锁可以申请成功,即被允许并发执行。第二张表,是同一个事务内部,新申请的锁是否可以升级为其他粒度的锁。这两张表,就是封锁技术的核心,尤其是第一张表,把读写、写读、写写三种冲突情况用锁规则固化,确保了 数据的一致性。
对于其他的并发控制技术,本质上都是定义了一些规则,用来约束并发的读写操作、提交顺序、并决定回滚哪些事务作为牺牲者,许多书籍都有详细讨论,我们就不再进行详细地探讨。概括地说,根据数据异常现象,制定出一定的规则,可以确保数据的一致性,这就是并发控制技术的核心。而增加新的规则,允许部分数据异常发生,从而产生了多种隔离级别。
这就是第四个问题。第三和第四个问题,我们讨论了并发控制技术和这些技术能够解决数据异常现象的原因。

接下来,我们从理论回归到工程实现当中,看看主流的数据库的并发控制技术,这就是今天的第五个问题。
大家可以看这张对比表格,概括了Informix、Oracle、PostgreSQL和MySQL这四个数据库的并发控制技术。主流的数据库,几乎都使用了封锁技术和MVCC技术。只有Infomix单纯地使用了封锁技术。Oracle尽管语法上提供了序列化隔离级别的设置,但没有提供真正的序列化隔离级别。
反倒是开源的两个数据库系统,PostgreSQL和MySQL实现了序列化。只是MySQL是在读数据时加锁结合SS2PL技术实现了序列化,这种方式的并发度很低,性能不好。而PostgreSQL则使用SSI技术实现了序列化,性能相对较好。在第一个问题中我们提出了两种写偏序的数据异常,PostgreSQL使用SSI技术,解决了写偏序异常。如果从正确性和性能这两个角度来衡量数据库的并发控制技术,显然,PostgreSQL在理论上优于MySQL,PostgreSQL采用的SSI技术复杂但高效。

接着,我们从系统锁、事务锁、事务锁的元数据锁和记录元组锁的角度详细对比PostgreSQL和MySQL的区别,然后再从隔离级别的角度来看这两个数据库的并发控制技术。
首先,PostgreSQL和MySQL都提供了系统锁,也都尽量利用了底层的硬件指令如TAS指令实现最基本的spinlock。使用操作系统提供的mutex来控制共享资源的并发操作。
其次,在事务锁方面,PostgreSQL统一管理元数据和用户数据,而MySQL则明显把元数据和用户数据分开用元数据锁和记录锁进行管理,并各自进行了死锁检测。
PostgreSQL对于元组上的并发操作,加元组锁到元组上,把事务ID记录在元组头上,用快照技术判断元组的可见性,操作结束则释放锁。而MySQL则是用内存锁表记录元组锁,等到事务结束后才释放。从这点上看,SS2PL技术的实现,在PostgreSQL和MySQL中是不同的。
从隔离级别的角度看,PostgreSQL和MySQL都采用了MVCC技术来实现可重复读和读已提交。
PostgreSQL和MySQL在并发控制技术方面最大的差别,在于对确保数据一致性的序列化的实现上,采取的技术不同,理论上性能不同。这就是两者在并发控制技术方面的最大不同之处。

最后,让我们一起来总结一下今天的分享:
首先,我们在第一个问题里讲述了11种数据异常现象。
然后,在第二个问题里,分析了产生异常现象的原因。最大的原因是并发。
所以,紧下来,我们分享了消除数据异常的技术,即抑制并发,所以提出序列化这种可串行化技术,从而带出了隔离性以及隔离级别,这就是第三个和第四个问题所讨论的各种并发控制技术,本质上就是通过定义好的规则消除并发带来的影响。
最后的两个问题,我们用实例研究了主流数据的并发控制实现技术,重点讲述了PostgreSQL和MySQL的并发控制技术。这就是今天所分享的六个问题的脉络。
当然,数据库的并发访问控制可以讨论的话题还有很多,比如:为什么SQL标准只规定了三种读异常?为什么主流数据库都采用了封锁的SS2PL协议等等。
而为了提升数据库的性能,并发控制技术也是一个重要的点。腾讯云数据库CDB、DCDB等后续也会在并发控制等技术上持续优化,力争为用户提供高性能,高一致性数据库服务。由于时间的关系,今天的分享就到这里,谢谢大家。也欢迎大家使用腾讯云。