
7月12日,浪潮发布了新一代M5服务器家族,其中最引人瞩目的莫过于号称全球首款2U8 NVLink? GPU密度最高、性能最强的AI服务器NF5288M5。这款产品是浪潮与NVDIA联合研发的创新计算平台,能满足AI云、深度学习模型训练和线上推理等各类AI应用场景对计算架构性能、功耗的不同需求。
每U搭载4颗GPU的密度、960TFlops的性能、ns级的延迟等性能参数都让人眼前一亮。但是或许你还有些疑问,为什么要设计如此强大的AI计算设备?会带来怎样的价值?如此大功率和高密度的设计还能保证稳定性吗?本文将为大家解答这些疑惑。

AI超级计算机NF5288M5
AI训练的“三座大山”–效率、弹性和密度
人工智能发端于上世纪五十年代,经历了几次繁荣与低谷,直到AlphaGo赢得世界围棋比赛,“人工智能”写进今年的政府工作报告中,人工智能热潮彻底爆发。就在昨天,国务院首次印发《新一代人工智能发展规划》,将人工智能提到了国家战略高度。AI训练的快速发展对计算力的需求呈井喷式发展,然而当前市场上的AI计算平台普遍面临着通讯效率低下、平台架构僵化、计算密度低等问题。
异构通讯开销严重影响计算效率:在AI训练中,采用CPU+GPU异构计算架构,通常需要以CPU为训练模型下发指令,给GPU“喂”数据,控制计算过程,提供逻辑判断,控制外部设备等。而GPU则需要接收来自CPU的数据,提供高性能的并行计算,将结果返回给CPU。这一来一回看似合理,但是实际上CPU和GPU分担着整个计算任务中不同的部分,他们之间需要频繁的通讯,而一旦通讯频次过高,CPU和GPU就需要花费大量的时间进行相互通讯,严重影响整个计算架构的效率。
多样化AI场景亟需弹性异构平台:目前市面上成熟的AI框架有十多种,像标准的图像、语音、语意理解等神经模型的数量则更为庞大。不同的AI框架包含了不同的模型和算法,比如SoftMax回归、聚类、决策树或梯度策略等,产生不同规模的训练数据。如针对大规模被标记的图片、语音信息,有文字信息的图片等,训练场景会变得十分多样化。多样化的AI训练场景对异构计算的服务器要求必然也各不相同,有的需要更多的GPU介入进行加速,有的则更依赖CPU和GPU进行相互迭代,有的需要大量的数据并行,有的需要进行模型并行,由此产生了对CPU和GPU计算架构的多样化需求。
计算密度没有最高只有更高:普通的AI图片聚类训练通常需要几十万个样本进行十几万次训练迭代,而面向自动驾驶或人员行为分析识别等应用时,训练量会呈几何数增加。为了保证模型能在有限的时间内做到足够收敛,某些模型甚至需要超过200片GPU卡以AI服务器集群的方式并行。为节省宝贵的数据中心空间,提高服务器的密度成为不二手段,更高密度的AI服务器不但节约了数据中心的基础设施,更大规模的机内互连也对网络等设备的依赖大大降低。
浪潮NF5288M5–AI计算加速器
为了提升计算效率、满足多样化AI场景需求,浪潮NF5288M5另辟蹊径,变异构为同构,消除了异构通信带来降低计算效率的烦恼。此外,为了更大幅度地提升服务器计算效率,满足AI应用对计算力的需求,NF5288M5在架构设计中将计算密度做到了极致。而为了满足客户对弹性架构平台的需求,NF5288M5创新地采用PCIe连接资源,实现更加灵活的拓扑。

浪潮NF5288M5
极致效率、异构变同构:NF5288M5抛弃传统异构计算架构模式,在2U空间内支持部署8块NVLink或PCI-E 接口的NVIDIA? Tesla? P100 GPU,可以在不依赖CPU的前提下,实现机内点到点通讯,减少了异构通讯的次数;并在业界率先支持NVLink 2.0和最新发布的NVIDIA? Tesla?系列GPU,可以实现GPU间高达300GB/s的互连带宽,并提供极低的延迟,让多块GPU并行的效率大幅提升超过60%。将GPU同构,把NF5288M5的并行计算效率尽可能推到极限。
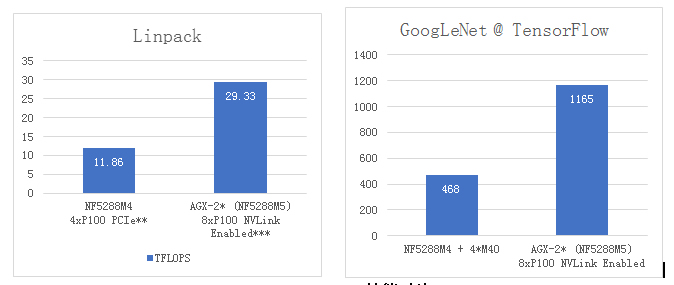
NF5288M5性能对比
极致密度、更高计算力:与浪潮支持2U4卡的NF5288M4对比测试,NF5288M5采用P100的Linpack浮点运算性能达29.33TFLOPS,是同样采用P100 NF5288M4的2.47倍;在AI深度学习模型训练上,当采用TensorFlow框架和GoogLeNet模型,NF5288M5处理速度为每秒1165幅图片,是搭配4片Tesla? M40的NF5288M4性能的2.49倍。在实现了性能和效率双提升的同时,机箱仍然保持了和上一代一样的2U高度,实现了最高的GPU卡部署密度。在超大规模AI训练集群或HPC集群引用时,可以帮助客户节省数据中心的基础设施资源,更有利于数据中心的空间分配。
极致灵活、弹性计算拓扑:NF5288M5采用PCIe线缆的方式连接CPU和GPU资源,可以灵活调整CPU的连接带宽和连接数量,在应对不同的AI应用时,更好的做到PCIe资源按需分配。灵活的计算架构可以让一颗或两颗CPU管理8颗GPU,也可以通过GPU扩展box的方式,实现最大16GPU的纵向扩展。而服务器提供的PCIe I/O,8个U.2插槽, 或多达4块100Gbps InfiniBand网卡,都可以根据计算灵活调整拓扑。NF5288M5弹性的异构平台,足以支撑多样化的AI场景。
极致设计背后带来的极限挑战
NF5288M5通过优秀的设计,实现了性能、灵活性和密度的多维度增强,然而这背后带来的却是对互连、供电和散热设计的三大极限挑战。如何在一个系统中实现GPU卡的灵活配置,满足高达3000W的供电需求,并在有限的空间内解决散热,成为了开发这款产品的三大难题 。在此就给大家一一揭秘NF5288M5是如何做到的。
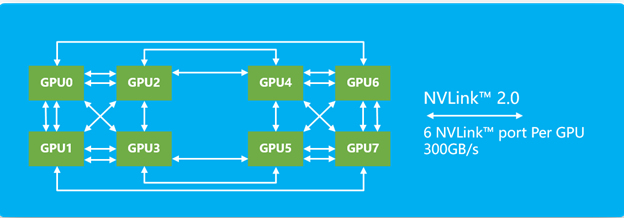
300GB/s聚合带宽的Cube Mesh拓扑
互连挑战:有别于业界异构服务器CPU和GPU紧耦合的互连方式,NF5288M5采用解耦式设计,不但提供灵活性,同时还支持高达300GB/s的NVIDIA? NVLink?GPU互连带宽。浪潮结合刀片服务器的设计思路,把这些组件紧凑的布局到2U空间中,并基于8路服务器的设计经验,确保NVLink?的走线长度、信号都处在最佳状态,以保证GPU的性能发挥。
供电挑战:8块功耗高达300W的GPU,以及服务器内其他的计算、存储和I/O资源,整机的功耗需求达到3000W,供电如何走线成为最大的挑战。NF5288M5借鉴了浪潮在整机柜服务器的供电设计方式,对单服务器内部采用无线缆供电设计,减少了供电线缆对空间的占用以及对散热气流的影响。在保证供电能力的同时,对空间、散热的影响降到最低。

NF5288M5散热风道设计
散热挑战:3000W的供电,意味着3000W的峰值发热量,6倍于传统的2U服务器,散热成为一个绕不过的难题。NF5288M5在设计之初,从布局、风道和气流多个方面统筹进行考虑。低发热量组件前置,高发热量组件后置,避免局部热点,让空气在服务器的内部均衡的升温,再通过高速风扇将热量快速带出服务器,最终NF5288M5可以和传统服务器一样工作在35℃的环温下。并且为了支持低PUE数据中心,还可以配置气液混合散热,甚至可以支持45℃的高环温运行。
100%的计算密度提升、960TFlops的计算力、200倍的单机AI训练性能,NF5288M5无愧是一款最高密度、最高性能的AI服务器,无论是在面向人工智能训练还是HPC应用时,都将为用户提供极致性能体验。和传统概念的高性能集群相比,GPU同构、灵活拓扑和超高密度的整体架构,让应用和硬件的结合,变得更为高效和紧密。







