
DoSTOR专家观点:随着信息化技术的发展和深入,企业对数据的依赖不断增强。与此同时,急速增长的数据量也给管理和使用都带来了全新的挑战。IDC最新报告显示,2007年新增数据量(281 ExaByte)已经超过所有可用存储介质总容量(264 ExaByte)约6%,并预计2011年数据总量将达到2006年的10倍。面对数据的爆炸性增长,仅仅提高系统运算能力和增加存储介质容量已经不能满足高速发展的各种数据应用,对高效数据缩减技术的需求已经逐步显现出来,并且越来越迫切。
目前能够实现数据缩减的技术主要有两种:数据压缩(Data Compression)和重复数据删除(Data De-duplication)。简单来说,数据压缩技术通过对数据重新编码来降低其冗余度(redundancy);而重复数据删除技术则着眼于删除重复出现的数据块。
数据压缩
数据压缩的起源可以追溯到信息论之父香农(Shannon)在1947年提出的香农编码。1952年霍夫曼(Huffman)提出了第一种实用性的编码算法实现了数据压缩,该算法至今仍在广泛使用。1977年以色列数学家Jacob Ziv 和Abraham Lempel提出了一种全新的数据压缩编码方式,Lempel-Ziv系列算法(LZ77和LZ78,以及若干变种)凭借其简单高效等优越特性,最终成为目前主要数据压缩算法的基础。
Lempel-Ziv系列算法的基本思路是用位置信息替代原始数据从而实现压缩,解压缩时则根据位置信息实现数据的还原,因此又被称作"字典式"编码。目前存储应用中压缩算法的工业标准(ANSI、QIC、IETF、FRF、TIA/EIA)是LZS(Lempel-Ziv-Stac),由Stac公司提出并获得专利,当前该专利权的所有者是Hifn, Inc.
LZS算法基于LZ77(如图一)实现,主要由两部分构成,滑窗(Sliding Window)和自适应编码(Adaptive Coding)。压缩处理时,在滑窗中查找与待处理数据相同的块,并用该块在滑窗中的偏移值及块长度替代待处理数据,从而实现压缩编码。如果滑窗中没有与待处理数据块相同的字段,或偏移值及长度数据超过被替代数据块的长度,则不进行替代处理。LZS算法的实现非常简洁,处理比较简单,能够适应各种高速应用。
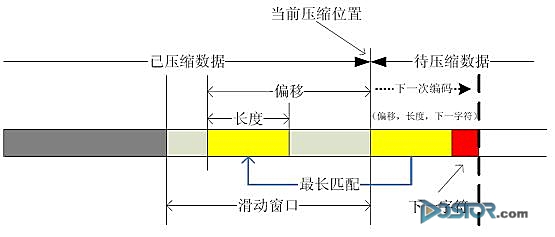
图一 LZ77算法示意图
数据压缩的应用可以显著降低待处理和存储的数据量,一般情况下可实现2:1 ~ 3:1的压缩比。
重复数据删除
在备份、归档等实际的存储实践中,人们发现有大量的重复数据块存在,既占用了传输带宽又消耗了相当多的存储资源:有些新文件只是在原有文件上作了部分改动,还有某些文件存在着多份拷贝,如果对所有相同的数据块都只保留一份实例,实际存储的数据量将大大减少–这就是重复数据删除技术的基础。
这一做法最早由普林斯顿大学李凯教授(DataDomain的三位创始人之一)提出,称之为全局压缩(Global Compression),并作为容量优化存储(Capacity Optimized Storage, COS)推广到商业应用。目前,除了DataDomain等专门厂商外,各主要存储厂商如EMC、IBM、Symantec、FalconStor等等也都通过收购或研发等途径拥有了各自的重复数据删除技术,有的还并冠以别名,如单示例存储(Single Instance Repository,SIR)等。
重复数据删除的实现由三个基本操作组成,如图二。首先,待处理数据(文件)被分割成固定或可变大小的数据块,同时生成一张"结构图"显示这些数据块怎样组成完整的原数据(文件);然后计算各数据块的"指纹"(标识),并根据"指纹"确认该数据块是否与其它数据块相同;最后,丢弃重复出现的数据块,并将"结构图"作为原始数据(文件)存储。
图二 重复数据删除原理
重复数据删除技术的关键在于数据块"指纹"的生成和鉴别。数据块"指纹"是鉴别数据块是否重复的依据,如果不同数据块的"指纹"相同,就会造成内容丢失,产生不可恢复的严重后果。在目前的实际应用中,一般都选择MD5或SHA-1等标准杂凑(hash)算法生成的数据块的摘要(digest)作为"指纹",以区分不同数据块间存在的差异,从而保证不同数据块之间不会发生冲突。但是,MD5,SHA-1等算法的计算过程非常复杂,纯软件计算很难满足存储应用的性能需求,"指纹"的计算往往成为重复数据删除应用的性能瓶颈。
目前,各厂商对各自重复数据删除技术的效用都有不同描述,一般都声称能将数据量减少到原数据的3% ~ 5%,即具有20:1 ~ 30:1的压缩比。
数据压缩和重复数据删除技术都着眼于减少数据量,其差别在于数据压缩技术的前提是信息的数据表达存在冗余,以信息论研究作为基础;而重复数据删除的实现依赖数据块的重复出现,是一种实践性技术。这两种技术具有不同层面的针对性,并能够结合起来使用,从而实现更高的数据缩减比例(40:1 ~ 90:1)。需要注意的是,如果同时应用数据压缩和重复数据删除技术,为了降低对系统的处理需求,通常需要先应用数据删除技术,然后再使用数据压缩技术进一步降低"结构图"和基本数据块的体积。
在归档应用中,存储的数据主要是文件在不同时间的各个历史版本,版本间的差异通常并不是很大,文件中往往有相当一部分内容并未发生改变,重复数据删除技术因而具有较大的应用空间和效能;同时,作为有特定意义的文件内容,使用数据压缩技术通常也可以获得2:1以上的压缩比。因此,针对归档应用,集成重复数据删除和数据压缩技术将可带来显著且可以预期的好处,实现90%以上的整体数据量缩减。
需要注意的是,由于数据压缩和重复数据删除技术都系统处理能力有较高要求,为了保证整体性能,在预算允许的范围内,应该注意选择具有相关硬件加速的方案。目前,市场上能够同时具有压缩和杂凑算法的解决方案并不多,主要由LZS算法的专利拥有者Hifn, Inc提供。除了常见的标准加密和摘要算法,Hifn的安全处理器和相应加速卡基本都集成有压缩处理能力,提供20MB/s ~ 250MB/s的处理能力。最近还专门推出了DR 250/255数据缩减加速卡,通过PCI-X和PCI-Express接口为存储系统提供250MB/s的数据压缩和摘要计算加速,并能够同时进行加密或解密处理,使系统能够在实现数据缩减的同时,提高对数据的保护级别。据称,Hifn下一代数据缩减产品处理能力将达到1.6GB/s,并支持IEEE P1619/1619.1标准的磁盘/磁带加密,计划将于今年下半年正式推向市场。







