数据库诞生于上世纪50/60年代。1961年美国通用公司研发第一个数据库系统DBMS诞生。1976年霍尼韦尔公司(Honeywell)开发第一个商用关系数据库系统—Multics Relational Data Store。至此,数据库就开始融入各行各业,改变人类对数据的管理和认知,发展到如今诸如登录淘宝购物、社交软件聊天,都离不开数据库。
数据库,无处不在。
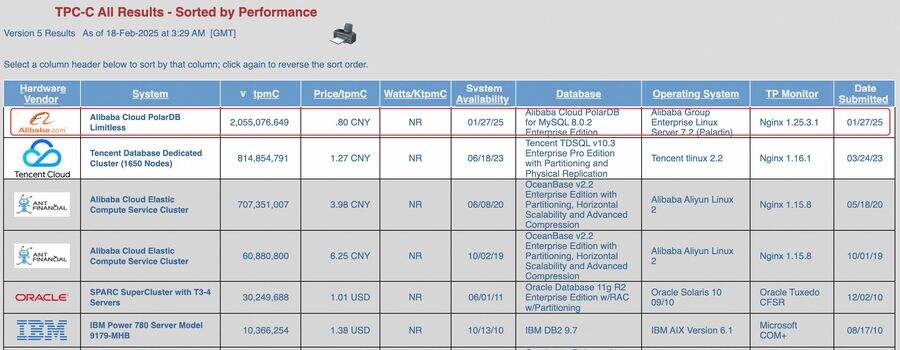
在2017杭州云栖大会前夕的9月21日,阿里云发布全新一代云数据库产品POLARDB,采用第三代分布式共享存储架构,实现计算节点和存储节点分离,使计算引擎和存储引擎均拥有快速扩展能力。它是首个国产的通用高性能自研数据库。在高性能通用数据库这块高地上,第一次有了中国面孔。
 阿里云POLARDB第三代分布式共享存储架构
阿里云POLARDB第三代分布式共享存储架构
6倍于MySQL性能差,云数据库释放性能潜力
与诞生于不同时代的Oracle、MySQL不同,云数据库诞生于云计算蓬勃发展的年代。阿里云POLARDB与AWS Aurora均采用了相同的产品设计理念,以提供更好的数据库能力以满足企业用户的云上需求,使基于第三代云计算框架下的云数据库解决了传统数据库性能、可扩展性等瓶颈。
产品架构上,POLARDB采用了节点间共享存储架构,让数据库实现了真正的秒级水平扩展,通过重新设计的文件系统POLARSTORE,实现相同数据更新操作减少了50%的磁盘写入量。并缩短了写数据的路径,使写性能显著提高,对读事务实现了优化。
基于新的3DXpoint存储介质、NVMe SSD和RDMA网卡等最新的软硬件优化技术,实现了低成本与高性能的突破。在标准场景下,POLARDB性能是MySQL的6倍,单实例实现100T级存储容量。而在云数据库厂商中,阿里云POLARDB则实现了AWS Aurora性能的1.2倍,成为世界级的云数据库引导者。
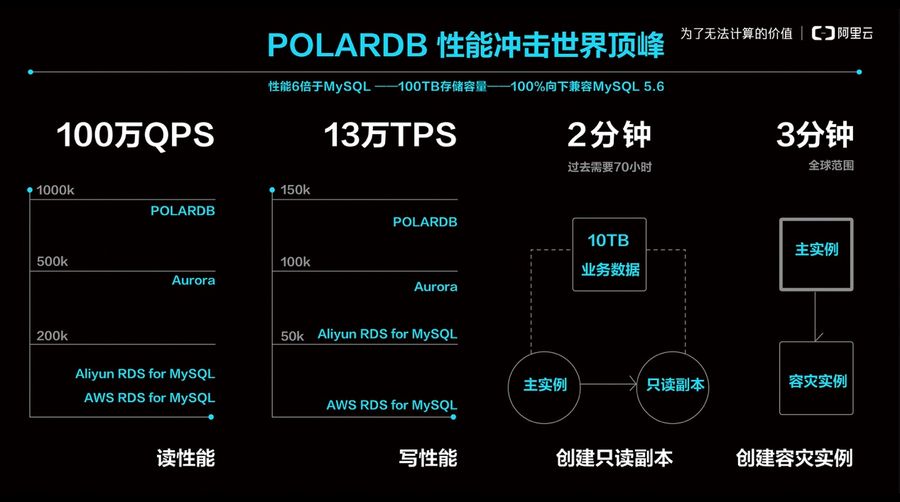 阿里云POLARDB性能全景
阿里云POLARDB性能全景
企业传统IT计算力急需重建和进化
在互联网时代,大促及活动,每一个互联网大型平台的波动,都会让交易量变得无法预测,以云计算为代表的互联网技术架构成为支持这种业务形态的最佳平台。
根据调查,进入互联网时代的人类社会,社会数据总量实现翻倍仅需9个月,而一个从十万量级到千万级用户的互联网独角兽企业的成长,也仅需3个月,面对互联网海量数据暴涨,再次挑战了传统的数据库架构。
回到传统数据库的最大应用场景:金融领域,最近余额宝的交易金额突破了万亿规模,成为了全球最大的货币基金,从2013年上线,业务在短短半个月增长了14倍,对底层技术架构带来了巨大的挑战,一方面每天晚上清算的时间从最初的半小时、变成后面的1小时、2小时、4小时……最后需要通宵达旦才能解决问题。
如果以传统IT的视角来看这样的扩容价格也是千万级别的,费用超过了天弘基金历年IT费用的总和。
传统商业理论认为,市场在哪里,先进的技术就将向哪里转移,在此背景下,以阿里云POLARDB与AWS Aurora为代表的云数据库应运而生。在性能和成本的双重压力之下,企业的传统IT计算力将通过云数据库寻找突破之路。
 人类社会数据暴涨,总量翻倍仅需9个月
人类社会数据暴涨,总量翻倍仅需9个月
自研关系型云数据库占领云计算技术高地
从使用数据库到自研数据库,相当于从开别人的车到造出一辆新车,是科技能力的集中体现。从行业上来看,大部分云计算厂商具备支持客户在云上使用开源类以及部分商业数据库的能力,但自研数据库产品仍然处于空白期,阿里云发挥自身多年在硬件和数据库源码上的积累,实现当前最全主流数据库的覆盖同时实现商用关系型数据库POLARDB的自研,和MySQL等其他数据库一起满足不同用户需求。
也因此,在云计算市场里,也由此可以划分为两类厂商。一类是具备自研第三代架构数据库能力的云计算厂商,另一类是提供其他数据库的云计算厂商。
 阿里云数据库建立新的行业标准
阿里云数据库建立新的行业标准
POLARDB通过计算与存储分离的革命设计,既拥有分布式设计的低成本优势,又具有集中式的易用性,从底层解决了海量数据扩容的问题。同时,通过分布式存储技术,使数据库的成本远低于商用数据库。正是有了这样低成本,高性能,高可靠性的数据库产品,未来中国才会诞生越来越多的爆发式独角兽,而无需担心高昂的数据库成本与扩容的问题,最大化地利用互联网的能力、使IT基础设施轻装上阵,全面云化,用更低的成本、获得了更好的IT处理能力,这才是未来企业的数字化答案。
就在不久之前,据媒体报道,众安保险将以750亿元的价格在香港上市,而很少有人知道的是,众安保险从诞生的第一天起,数据就在阿里云云数据库上。而在全国的各个城市,如火如荼的共享单车背后,云数据库支撑着OFO在三个月中从数万用户增长到千万量级。
今天的云数据市场,这样的故事正在不断发生着。然而不同的是,这样的转移并非自然发生,而是一群平均年龄不到30岁的中国工程师的努力。而在他们身后,阿里云上已经有超过10万个数据库实例,正在运行。