未卜先知、研判吉凶一直是人类自古以来孜孜以求的一种向往。时至今日,随着消费升级带来的市场竞争和产业模式的转型,企业也越来越希望在预测能力上能有更好的提升。做预测分析时,通常会使用时间序列算法或回归模型。时间序列算法在做预测分析时,只考虑了数据在时序上的规律,而忽略了相关的影响因素,适用于比较简单的预测分析场景。在情况比较复杂的情况下,需要考虑到相关因素的影响时,则需要考虑用回归方法做预测分析。
纵览近几年在预测分析领域的学术研究成果,GBDT(Gradient Boosting Decision Tree,梯度提升决策树)算法作为机器学习算法的一种,跃然成为众多研究机构和学者积极推荐的预测分析算法,并且结合Hadoop平台取得了很好的性能表现和预测准确度。主要的应用方向有如下方面:
①故障预测分析
②欺诈预测分析
③搜索引擎用户体验提升
④视频流媒体服务体验提升
⑤个人征信
在商业应用中,需要用到机器学习技术做预测分析的场景还有很多。面对大量的数据,如何更好利用GBDT进行分析预测是个极大的应用挑战,本文将会围绕基于GBDT算法探讨如何实现预测分析的创新模式,帮助企业实现大数据预测分析的应用普及。
GBDT算法简介
GBDT的算法最初是由Leo Breiman[1] 在1997年提出的,1999年Jerome H. Friedman将GBDT算法用于回归分析[2][3]。随后几年,陆续有学者对GBDT回归算法进行了改进和优化,GBDT在回归问题中取得了很好的效果。陈天奇博士还根据GBDT多年的发展,对GBDT进行修改和优化,得到了XGboost算法[4]。在Apache Spark的Mllib库中也整合了GBDT回归算法,可以方便地在Spark平台上使用GBDT做回归预测分析。
GBDT的原理是利用梯度下降学习出多个弱学习器,组合产生一个强学习器。假设初始得到的学习器是公式1,其中 指的是模型 的损失函数, 是训练集,特征 对应的结果是 。初始化模型可以使用决策树算法,也可以使用最小二乘法。初始化模型是根据当前数据,使得损失函数最小的模型。
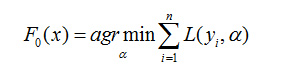 (公式1)
(公式1)
设定迭代次数是M,那么GBDT算法就是要根据公式1,使用梯度下降算法通过M次迭代后得到的优化模型。下面简单分析下,第一次迭代的得到 的过程。
第一步,计算梯度:
分别对 计算梯度,梯度如公式2所示。

(公式2)
第二步,训练一个基学习器,根据训练集特征可以计算得到梯度:
使用特征和梯度 作为训练集,训练学习器,得到 。使用的训练算法可以是决策树算法,也可以是最小二乘法。
第三步,寻找合适的步长:
在梯度下降算法中,需要用步长确定梯度下降的速度,步长是自己指定的,在GBDT算法中用到的梯度下降,步长是通过计算得到的。计算的规则是使得到的新学习器 损失函数值最小数。

(公式3)
第四步,根据梯度和步长,迭代得到模型 ,如公式4所示。
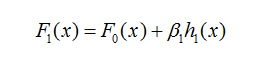
(公式4)
通过上面四个步骤,利用梯度下降算法,可以从初始模型 优化得到第二个模型 。迭代操作以上四个步骤M-1次,就可以得到最终的GBDT模型。GBDT模型就是这样由多个弱学习器组合而成的。
简而言之,GBDT是一种迭代的决策树算法,该算法由多棵决策树持续迭代而成,这个迭代过程就是一个机器学习的过程,直至所有树的结论和残差等于或趋近于0为止,进而得到一个高准确度的预测模型。
基于GBDT的传统数据科学家工作模式
在使用GBDT算法进行预测分析之前,首先需要对原始的数据进行数据预处理,然后才可以使用处理好的数据进行预测分析。
2.1 数据预处理
拿到数据的第一件事情就是对数据进行预处理,将原始数据处理成可以分析的形式。数据预处理一般包括特征提取、数据清洗、标准化等操作。
①特征提取
特征提取是根据要预测的内容,选择可能会影响到预测结果的特征,在不同的问题中需要提取的特征是不一样的。
比如想要预测下个月猪肉的平均价格,通过分析影响猪肉价格的特征可能有“生猪个数”、“玉米价格”、“豆粕价格”、“是否包含节假日”、“猪类疾病”等。如果原始数据中包含这些特征值,那么直接将这些特征选取出来;如果数据中没有这些特征,但是可以计算得到,那就通过计算来获取这些特征,提取完特征后进行数据处理。
再比如想要预测下个月书店里某本书的下个月的销量,通过分析影响该书店某本书销量的因素可能有“该书店上个月该书的月销量”、“该书去年同一时间该书的月销量”、“该书的作者影响力”、“该书所属出版社的影响力”等。如果原始数据中包含这些特征值,那么直接将这些特征选取出;如果数据中没有这些特征,但是可以计算得到,那就通过计算来获取这些特征,提取完特征后进行数据处理。
②数据清洗
在完成了特征提取之后,并不能将数据直接用于计算,很多情况下需要对数据进行一些基本的处理。这些基本的处理包括缺失值的处理、非数字形式的特征值处理、异常值的处理等等。
缺失值可以根据项目需要采取多种方式进行处理。最简单的方法是补充一个统一的值,显然这样的方法在大多数情况下不是很好。还可以通过相关的特征值计算得到缺失位置的数值,然后补充该值。对于缺失值,在有必要的情况下,还可以专门训练一个模型,预测缺失位置的数值。在某些情况下,也可以不处理缺失值。
如果特征值不是数值形式的,需要首先进行转化,将取值转成数值形式。转化的方式有很多种,可以根据相关的数值特征计算得到该特征的数值,也可以用枚举的方法为不同取值分别赋值。
不可避免的在原始数据中会在一些异常值,在数据预处理中需要能够检测到异常值,并做相应的处理。可以选择直接过滤掉异常值,也可以对异常值进行修正。
③标准化
标准化在很多情况下是一个很重要的步骤,其目的是将各种各样的特征进行归一化处理。直接选取和计算出的特征取值范围往往很不规则,标准化能解决这些不规则的问题。
2.2 模型调用
对数据进行预处理之后,就需要使用GBDT模型对预处理好的数据进行拟合。回归模型是用一个模型拟合已有的数据,在得到这样的模型之后,如果知道想要预测数据的特征,就可以通过特征预测出目标值了。
如果你的编程能力足够好,完全可以自己动手写自己的GBDT模型。不过目前已经有很多成熟的GBDT代码,可以直接使用。
如果不需要在Spark平台上运行程序,可以使用Python语言直接调用Scikit-learn中的GradientBoostingRegressor包。如果需要在Spark平台上运行程序,则可以直接调用Apache Spark Mllib中包装好的GBTRegressor。借助这些已经存在的库,可以很容易地调用GBDT回归算法。同时根据上面介绍的GBDT算法的原理,数据科学家会基于对GBDT算法中各个参数的理解,对模型进行调参。
经过上述操作,可以实际得到一个GBDT回归模型。
2.3 基于GBDT的预测示例
问题:预测书店里每本书在2017年12月份的月销量
数据:书店中2017年12月之前的所有销售数据,书店里每本书的基本信息

图1 数据的简单处理之后的形式
对原始的数据进行简单的预处理之后,得到图1中的数据形式。第一行是每一列数据的含义,之后的每一行是书的月销量以及影响月销量的特征。其中第二列是书的月销量,第三列及之后的列是影响书的月销量的相关特征(其中第三列是书的历史总销量,第四列是书所属作者所著所有书的历史总销量,第五列是书所属出版出版的所有书的历史总销量,书的标价,……)。从中可以看出,不同特征的取值范围差异很大,因此对数据进行归一化操作是有必要的。
在训练模型时,需要将数据分为训练集和测试集两个部分。在这里,将2017年11月之前的数据当做训练集,将2017年11月的数据当做测试集,通过这种方式对模型进行调参和训练,得到更优化的模型,使得模型的预测能力更好。
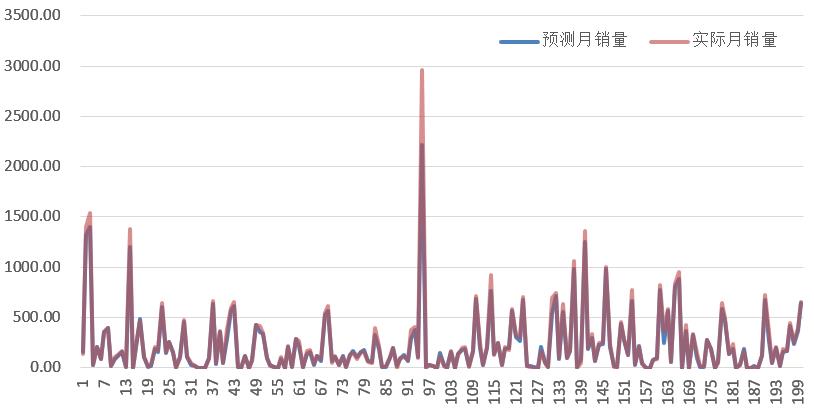
图2 2017年11的实际月销量和预测月销量对比图
图2是2017年11月的月销量预测结果和实际结果的对比。其中横坐标是书本的编号,纵坐标是书的月销量。从图中可以看出,预测的月销量和实际月销量是很相近。
基于GBDT的业务驱动创新应用模式
3.1 平民化一键完成GBDT分析
在实际的企业应用中,预测分析的场景有很多,除了案例中介绍的可以预测图书的月销量之外,还可以预测股票的价格、预测某种蔬菜的价格、预测景区人流量、预测高速路某断路的车流量、预测餐厅的就餐人数、预测服装店的月销售量等等,基本的覆盖了所有的预测分析案例。
尽管预测分析的应用场景很多,但是将GBDT算法应用到实际场景中却很难。很多企业并没有雇佣数据科学家,普遍缺乏使用GBDT算法做预测分析能力,但是却有预测分析方面的普遍需求。另外,这个应用过程还需要选择合适的特征数据,需要对数据进行预处理,如果数据量过多,还需要考虑Spark部署和Spark编程等等。
综合上述,企业预测需求和能力短板之间的差距,用友分析云基于GBDT算法进行预测分析应用方面有了创新应用模式,力求让所有企业能够普及使用这个强大的机器学习预测工具。
使用用友分析云,不需要做数据预处理工作,也不需要动手写代码,就可以使用GBDT算法进行预测分析,所有的这些工作,用友分析云会在后台的Spark平台上进行分布式计算,帮助企业方便、快捷、高效地将GBDT算法应用到需要的大样本数据分析场景中。
在用友分析云中,可以将数据导入用友分析云的数据集中,用友分析云会在后台做一些数据预处理的操作。接下来只需要将影响月销量的特征拖拽进维度里,将需要预测的列名拖拽进指标里,分析云就可以帮助企业使用GBDT回归算法对指标列的内容进行预测。图3是在分析云中预测生成的,对某书店的书“海底两万里”的月销量的高准确度预测结果。用友分析云可以帮助企业轻松地做预测分析。
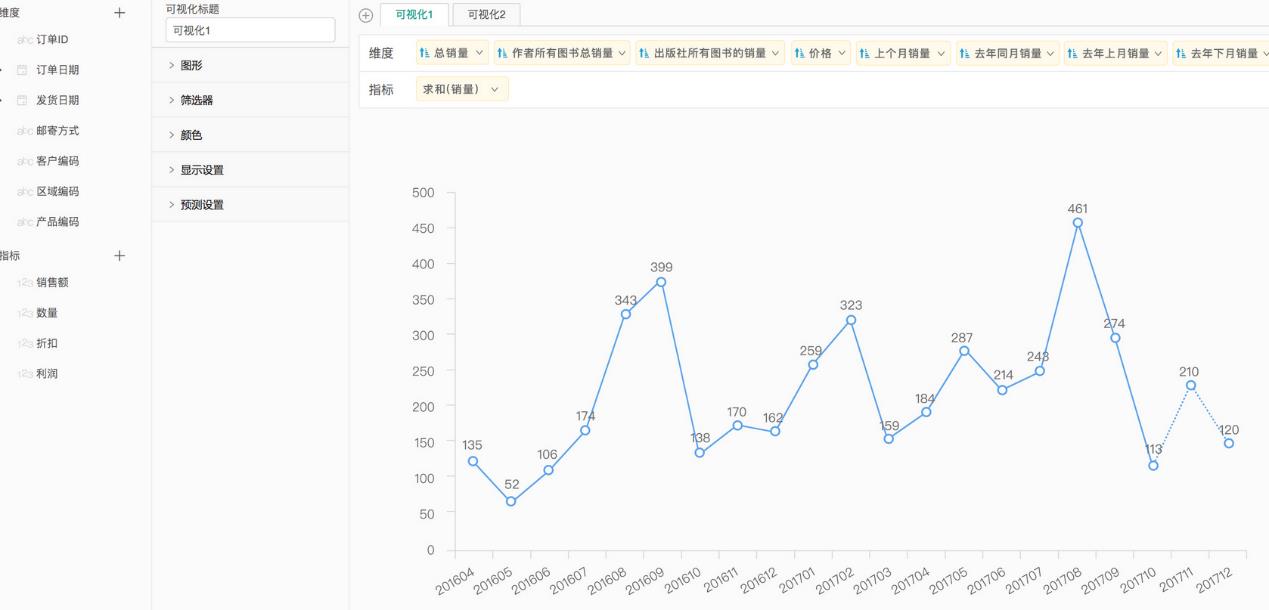
图3 分析云中预测书店中“海底两万里”的月销量
3.2 基于算法竞争的模型优化
用友分析云中的预测分析,除了使用GBDT算法外,还使用了时间序列算法。GBDT算法做预测分析时考虑到一些影响目标值的因素,而时间序列主要考虑到数据在时序上的一些规律,忽略了其他因素对目标值的影响。这两种算法在实际应用中刚好互补。如果原始数据中包含足够的数据特征,通常情况下使用GBDT回归做预测分析效果会比时间序列更好。如果原始数据缺乏特征信息,使用时间序列进行预测反而很好。
在用友分析云中,同时使用了时间序列和GBDT回归算法做预测分析。用友分析云会自动将数据分为训练集和测试集两部分,分别使用GBDT回归算法和时间序列算法在训练集上训练模型,并使用测试集对模型进行调优。在具体使用时,用户不用关心具体选用底层实现,只需要在界面上进行简单的拖拽,后台就会自动地帮用户选择合适的模型进行预测分析,并将结果用图形界面显示出来。
总结
在数据量日益递增的今天,对数据进行预测分析是很有必要的。本文介绍了GBDT算法的基本原理,讲述了如何在项目中使用GBDT算法进行预测分析,描述了在用友分析云中如何使用GBDT算法做预测分析,用友分析云将大数据预测分析简单化,为有预测分析需求的企业降低了使用门槛,让没有数据科学家的企业可以方便地使用大数据算法进行预测分析,推进机器学习在企业中的普及应用。
引用
[1] Breiman, L. “Arcing The Edge”. 1997
[2] Friedman, J. H. “Greedy Function Approximation: A Gradient Boosting Machine”. Annals of Stattistics, 2001 29(5):1189-1232
[3] Friedman, J. H. “Stochastic Gradient Boosting”. 1999
[4] Tianqi Chen and Carlos Guestrin. “XGBoost: A Scalable Tree Boosting System”. In 22nd SIGKDD Conference on Knowledge Discovery and Data Mining, 2016
本文作者系 用友分析云专家 李谨秀 胡钢