为了更好的探讨如何引导IT基础设施向更加智能化的方向发展,构建部署灵活、自动化的云环境,开创产业的崭新未来,12月22日,由中国信息通信研究院主办,云计算开源产业联盟承办,中国移动苏州研发中心协办的“2017首届全球存储大会”在北京国宾酒店举行。在会议上,云计算开源产业联盟融合数据项目组组长,中国信息通信研究院马飞博士代表项目组,发布了《融合数据白皮书第一部分:融合数据存储》。

马飞博士表示,在大数据时代,大型企业数据爆发式增长。在企业快速转型过程中,企业数据处理场景日益丰富,数据分析要求越来越灵活,从传统的报表分析、OLAP、OLTP业务,到新兴的批处理、实时数据分析、机器学习,新的数据分析模式层出不穷。但是,不同数据处理架构对底层数据的存储/组织、检索(引擎),乃至处理接口都提出不同要求,对一份数据需要配套构建多套不同结构的数据集,导致数据冗余严重,数据不能共享。这导致了平台维护成本、数据冗余和数据转换代价的与日俱增,严重阻碍了大数据分析技术的应用和发展。而融合数据存储通过一份数据存储,可以实现海量复杂数据(总量达到EB级的,单表数据达百亿行级别以上,单表属性维度达百维以上的数据)的归并,并支持多维度任意组合查询和分析,支持多种快速查询需求(如过滤查询、快速扫描、详单查询等)的统一响应。将有效解决多业务场景下多份数据存储的问题。因此,融合数据是大数据未来的发展方向。

马飞博士介绍了不同行业对融合数据存储的不同需求,以及目前业界典型的大数据系统存储方案,在面对行业融合数据存储需求时的局限和不足。并介绍了以Apache社区的ORC、Parquet和CarbonData等为代表的目前业界主流的融合存储技术,这些主流技术的技术对比,以及在10亿数据规模下的过滤查询场景和聚合计算场景下的性能对比。

表1 开源融合数据存储技术特性对比
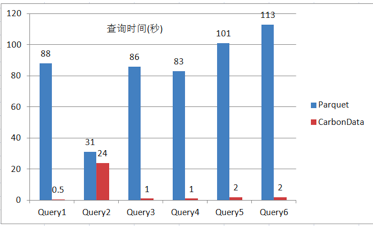
图6 Parquet和CarbonData在过滤查询场景下的性能对比

图7 Parquet和CarbonData在聚合计算场景下的性能对比
最后,马飞博士也就融合存储技术的发展进行了展望。希望一方面用户企业积极参与开源社区的活动,通过贡献需求与场景,推动融合数据存储技术的业务落地。另一方面利用产业组织、会展活动、技术交流等场合加强厂商间的沟通与合作,共同促进技术的发展与应用水平的提升。
Apache® CarbonData™介绍:
Apache® CarbonData™是由华为开源贡献的大数据高效存储格式解决方案。Apache® CarbonData™致力于推动大数据开源技术的持续发展,以一份数据同时满足多种业务场景诉求,打造高效、开放、完整生态的大数据新融合数仓存储方案。目前,CarbonData技术已经在华为云MRS服务获得使用。华为云MRS服务,在完全兼容开源组件的基础上,融合CarbonData优势,支持大规模的数据存储、分析和计算,为客户提供云时代企业级一站式大数据服务,帮助企业轻松驾驭海量数据,洞察数据价值,在商海中占得先机。
点击了解华为云存储产品:http://www.huaweicloud.com/product/