(之前的章节介绍了NVMe over Fabrics的发展背景及协议的基本内容,查看上文《为了部落:NVMe over Fabric诞生记》,这节将介绍与NVMe over Fabrics密切相关的一个传输层协议——RDMA。)
在这些众多的传输层协议中,重点介绍一下RDMA。RDMA(Remote Direct Memory Access)是一项古老的技术。它通过互联网络把数据直接传入某台计算机的一块存储区域,不需用到多少计算机的处理功能。普通网卡集成了支持硬件校验和的功能,并对软件进行了改进,从而减少了发送数据的复制量,但无法减少接收数据的复制量,而这部分复制量要占用处理器的大量计算周期。
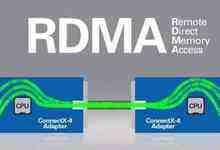
为充分发挥万兆位以太网的性能优势,必须消除主机CPU中不必要的频繁数据传输,减少系统间的信息延迟。从下面的图中看出,RDMA通过网络把数据直接传入计算机的存储区,降低了CPU的处理工作量。当一个应用执行RDMA读或写请求时,不执行任何数据复制。在不需要任何内核内存参与的条件下,RDMA请求从运行在用户空间中的应用中发送到本地NIC(网卡),然后经过网络传送到远程NIC。

RDMA对于NVMe over Fabrics协议的便利性体现在下面几个方面:
- 提供了低延迟、低抖动和低CPU使用率的传输层协议;
- 最大限度利用硬件加速,避免软件协议栈的开销;
- 依赖于开放互联联盟组织维护的Verbs和代码库,RDMA定义了丰富的可异步访问的接口机制,这对于提高IO性能是至关重要的。
RDMA依据底层的不同,可进一步分成InfiniBand,RoCE和iWarp。它们的区别主要是底层实现协议的不同。其中InfiniBand需要依赖于专用的InfiniBand网络,因此可以提供非常好的服务质量,而RoCE和iWarp则可以基于以太网络,并使用专用的RDMA NIC和Switch来实现高服务质量。RoCE的两个版本中,v2依赖于UDP/IP协议提供了在局域网中灵活的路由和拥塞控制功能;iWarp则是基于TCP协议提供了更加灵活的网络互联方式。

在各种RDMA中,定义了硬件操作的基本原语。在软件层面,需要执行RDMA操作的命令按照硬件制定的方式组织成命令请求项,并添加到位于内存中的工作队列中。硬件再依次从这些队列中取出命令开始执行;命令的执行结果会记录到一个完成队列中,这个完成队列也是处于内存中的,因此可以为软件层面感知到并进行后续处理。

由于RDMA底层实现可以使用任意一中接口方式实现详尽的功能,在每种协议背后又有众多的厂商支持,为了统一应用接口,便于软件开发人员理解和使用RDMA,每种RDMA协议定义了Verbs用于异步操作实现RDMA的语义。Verbs是一种比API更加底层的编程方式,根据使用方式的不同,可分为两类:
1、 控制路径Verbs,用于管理RDMA的资源,通常需要上下文切换。例如Create,Destroy,Modify,Query,Work with events。
2、 数据路径Verbs,用于使用Handle来发送、接收数据的操作,不需要上下文切换。例如Post Send,Post Receive,Poll CQ,Request for completion event。
而对于RDMA至关重要的远端内存空间,在RDMA协议中是通过内存区域(MR)来进行描述。定义内存区域实际上就是把这个虚拟内存锁定到物理内存中,并告诉NIC对应的关系。这样,依据MR的Key,NIC硬件可以不依赖硬件去操作数据在本地内存和远端的MR之间进行传输。
从上面关于RDMA的介绍来看,RDMA设计初衷就是为了高性能、低延迟访问远端节点的,并且它的语义非常类似本地DMA的过程,因此很自然就可以将RDMA作为NVMe协议的载体,实现基于网络的NVMe协议。但是,毕竟基于网络的传输模型与本地的PCIe传输模型还有种种差异,因此将NVMe协议拓展到互联层面需要解决一系列问题。
因此,综合RDMA,FC等等各种不同传输层协议的特点,NVM Express Inc.提出了NVMe over Fabrics协议实现了一个完整的网络高效存储协议。需要注意的是,NVMe over Fabrics协议的基础是NVMe Base specification,目前特指的版本是NVM Express revision 1.2.1。
本文作者路向峰现任Memblaze公司CTO,文章最先发布于公众号晶格思维(crystalwit)。该系列文章将从NVMe over Fabrics的诞生背景及技术细节入手,向读者全面解析当下存储领域这一热门话题。文章后续部分将陆续发布于本公众号,读者亦可扫描下面二维码关注晶格思维公众号阅读原文。