
在GPU、FPGA、XPU等AI计算服务器层出不穷的今天,AI计算力得到大幅提升,算法框架的选择成为了优化AI运算效率的重要因素。同时,由于AI计算系统从单机单卡到单机多卡,再到后来的多机多卡并行计算发展,数据中心需要同时管理数量庞大的AI计算服务器来支持应用。如何更好地进行管理和监控,也将影响AI应用的产出效率和运转成本。近期,浪潮与美国某知名的互联网公司开展联合测试,对主流的深度学习框架进行了一次测评,希望在框架选择上给予大家一些经验和建议。
如何选择一款合适的深度学习框架?
随着人工智能的火热,目前开源出来的深度学习框架非常多,如Caffe、TensorFlow、MXNet、Torch等等。框架众多,如何选择?选择一种框架还是多种组合?针对不同的场景或者模型需要选择什么样的框架?面对多大数据量需要选择多机并行的框架?这些我们针对深度学习框架所面临的挑战,难免会让很多人犯难。
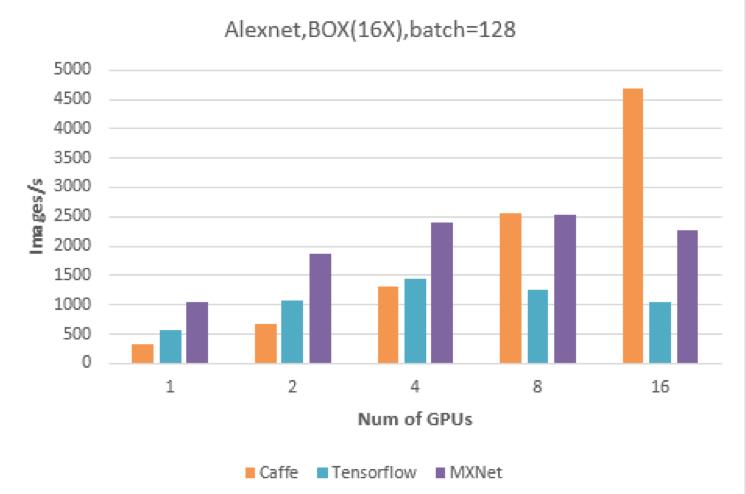
近期,浪潮与美国某知名的互联网公司开展联合测试,对主流的深度学习框架做了一个测评。把三个主流的框架Caffe、TensorFlow和MXNet部署到浪潮SR-AI整机柜服务器平台上(配置16块GPU卡),采用ImageNet数据集,测试AlexNet和GoogLeNet两种典型网络。
 浪潮联合美国某知名的互联网公司对主流深度学习框架的测试结果
浪潮联合美国某知名的互联网公司对主流深度学习框架的测试结果
从测试结果来看,当运行AlexNet网络时,Caffe性能最好,每秒可以训练图片张数达到4675张,16个GPU比单个GPU的加速比达到14倍。其次是MXNet,最后是TensorFlow。
当运行GoogLeNet时,MXNet性能最好,每秒可以训练的图片张数达到2462张,16个GPU比单个GPU的加速比达到12.7倍。其次是Caffe,最后是TensorFlow。
从这个评测来看,基于不同的网络,所选择最优的框架是不一样的。
基本上可以有大致的一个原则来选择:我们会根据不同的场景和模型来选择至少一种深度学习框架,目前很难说一种框架能在所有的应用场景中表现最优。
如果是图像方面的应用,主要采用Caffe、TensorFlow和MXNET这三种框架;
如果是语音的话,可以选择CNTK;
自然语言处理的话可以采用PaddlePaddle。
针对大数据量的训练,采用单机训练的话时间会很长,有可能是几周或几个月训练出一个模型,需要采用分布式框架。浪潮自研的深度学习框架Caffe-MPI,就实现了多机多GPU卡的并行训练。通过实际测试,Caffe-MPI采用16个GPU卡同时训练时,每秒处理效率达到3061张,较单卡性能提升13倍,扩展效率达到81%,性能将近是TensorFlow的2倍。
目前,浪潮Caffe-MPI框架目前已在Github开源,如果有需要可以免费下载使用。
当机器越来越多,怎么管理才高效?
人工智能深度学习训练流程较长、开发环境较复杂,涉及数据准备和处理、特征工程、建模、调参等多个步骤及多个框架和模型,每个框架依赖环境不同且有可能交叉使用。同时,深度学习模型在训练时往往耗时较长,短则数小时长则数天,以往在训练完成后才意识到模型存在问题,大大耗费了用户的精力和时间。
浪潮AI管理软件AIStation可以提供从数据准备到分析训练结果的完整深度学习业务流程,支持Caffe、TensorFlow、CNTK等多种计算框架和GoogleNet、VGG、ResNet等多种模型。
AIStation支持对训练过程实时监控并可视化训练过程,支持打印每一步的损失函数值的日志、训练误差或测试误差等;支持动态分配GPU资源实现资源合理共享,实现了“一键式”部署深度学习计算环境、快速启动训练任务;还可以实时监控集群的使用情况,合理安排训练任务,可及时发现运行中的问题,提高集群的可靠性。
 浪潮AI管理软件AIStation
浪潮AI管理软件AIStation
除此以外,浪潮还可提供天眼高性能应用特征监控分析系统,量化超算软件特征,提取和记录应用软件在高性能计算机运行过程中实时产生的CPU、内存、磁盘、网络等系统信息和微架构信息,及时帮助使用者找到系统瓶颈,并能准确地分析出程序开发者的应用软件特征,帮助用户合理的划分集群使用资源、提高使用效率。
有了强劲的AI计算平台、适合的开发框架、高效的AI管理监控软件,一个AI基础平台就基本构建完成,剩下的就是靠优化的算法把你所拥有的数据,转化成更有价值的资源。2018年,AI仍将是一个巨大的风口,希望以上浪潮测试数据和选型攻略能够为大家带来一些启发。







