【按:AI能否解决更多现实问题取决于各行业的技术开发人员能否对AI善加利用。通过将AI技术嵌入到应用程序中,开发人员能为用户带来独特的个性化体验。本文中,我们将与大家分享一些源代码和资源,让非AI领域专家的开发人员也能够设计以数据驱动的个性化AI应用程序。文章译自微软机器学习博客文章“Now Available: Access to Source Code & Demos of AI-Infused Apps”】
随着技术的发展,AI可以为我们本已熟悉的应用程序增添很多意想不到的力量。而AI应用程序有三个关键特征:
——随着时间的推移更加智能;
——可以提供新的体验,消除人与技术之间的障碍;
——可以帮助用户理解海量的数据,从而带来更好的体验。

为了帮助更多非AI技术领域专家的开发人员也能将AI应用到自己的程序中,微软提供了一系列源代码及相关资源,从以上三个特征角度升级开发者们的应用程序。
1. 更加智能的应用
机器学习是可以使应用变得智能的关键技术之一,但并不是每个开发者都有能力创建机器学习模型。为此,微软在微软认知服务中提供了预先构建的、以抽象库形式呈现的机器学习模型。搭建在微软Azure云平台上的微软认知服务易于使用,可以定制,并且还可以提供一系列解决AI领域应用常见任务的API服务,如视觉、语音和自然语言理解等。
让我们看看如何通过微软认知服务将AI注入到真实世界的应用程序中(内含源代码):https://github.com/Microsoft/Connect-keynote_AI_demos/blob/master/visionapi/CognitiveServicesVisionAPIDemo.md
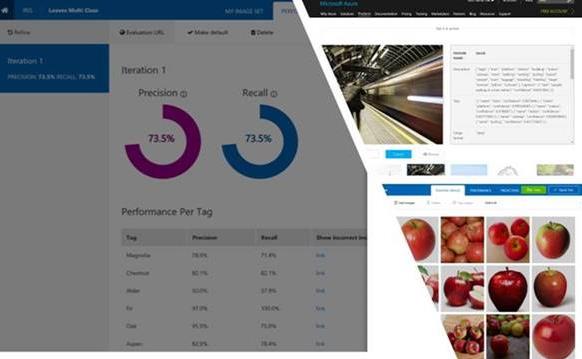
事实上,企业最重要的需求之一就是能够定制API,以适用于他们自己的产品。为此,微软于2017年5月发布了定制视觉服务(Custom Vision Service),让任何开发人员都能快速地将视觉服务嵌入到应用程序中,并轻松构建和部署自己的图像分类器。更多信息请访问:https://customvision.ai/。整个定制开发流程也非常简单,只需上传一些数据进行训练,然后通过REST端点来调用模型,最后再将调整好的模型应用到实际程序中即可。
以创建一个在iPhone上实时识别水果图片的程序为例:
——首先利用CustomVision.ai等API的可定制性轻松构建自定义图像分类器;
——然后通过使用Xamarin,将微软认知服务整合到iOS应用程序中;
——最后将模型部署到本地iOS设备里,这样可以在不需要网络连接的情况下提供较高的识别准确度,并增强应用性能和用户体验。

Demo演示:https://github.com/Microsoft/Connect-keynote_AI_demos/tree/master/Xamarin
2. 新的应用程序交互体验
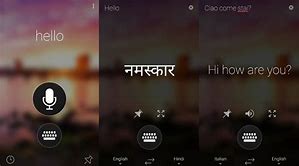
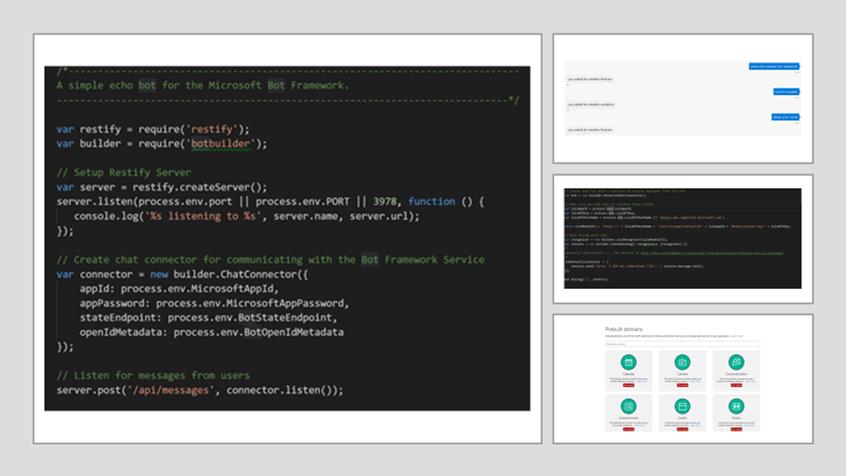
面向未来的应用程序该如何提供全新的用户交互体验呢?人机交互技术的发展正朝着对人类更加友好的自然交互模式的方向进行,对话式AI服务就是一个很好的例子,比如对话式智能客服、智能聊天机器人等。
微软AI云服务可以让构建对话式AI服务变得十分容易。Demo演示及相关源代码:https://github.com/Microsoft/Connect-keynote_AI_demos/tree/master/WeatherBot
3. 数据驱动的应用程序
未来的应用程序都将基于爆炸式增长的大数据所构建。然而,有时候由于数据的规模过于庞大,人类很难进行理解。在过去两年内,我们所创造的数据就超过了这个星球上以前所有人类历史中创造的数据量。而到2020年,我们每人将创造1.7兆字节的新信息。
作为开发人员,我们需要从数据中提取尽可能多的洞见,以便为用户提供更好的用户体验,比如推荐商品、发现朋友、识别并处理垃圾邮件、预估汽车的到达时间等等。但是,这些目标的实现需要适合的、且易于与应用程序整合的数据训练工具。
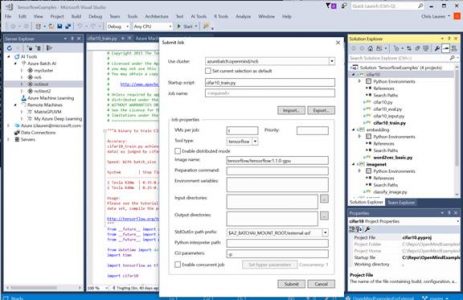
Visual Studio Tools for AI就是微软为开发者提供的一个强大的工具集,它可用于训练易于集成到应用程序中的模型。如何使用Visual Studio Tools for AI在本地训练深度学习模型,然后再将其扩展到Azure上,并将该模型包含在应用程序中呢?
一起来看看Demo演示(内含源代码):https://github.com/Microsoft/Connect-keynote_AI_demos/blob/master/vstoolsforai/visualstudiotoolsforAI-demo.md

除了上面讨论的从三个不同特征角度单独升级应用程序外,微软还提供了一套完整的AI赋能应用程序的解决方案,帮助开发者全面升级应用程序。下面我们提供几个案例演示。
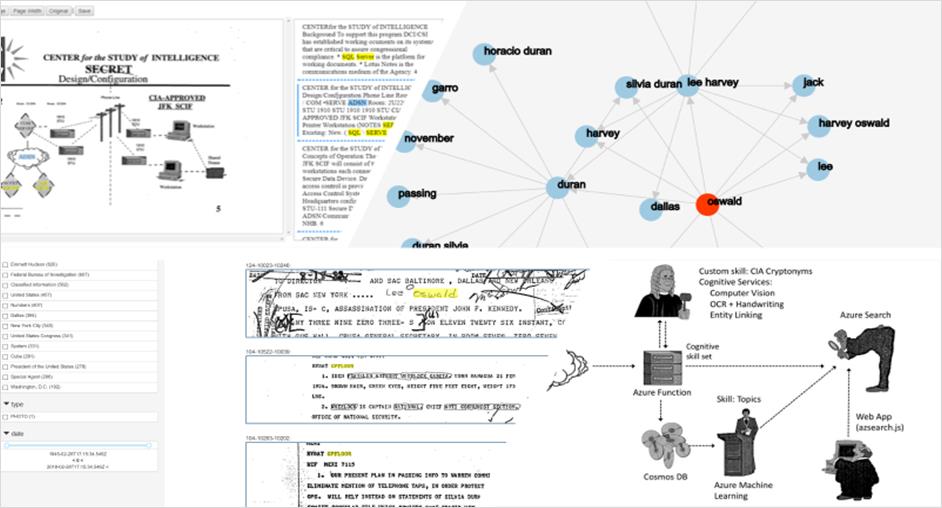
JFK文件演示
1963年11月22日,美国总统肯尼迪被暗杀,一直以来这次暗杀都是颇具争议的话题。25年前,与暗杀有关的所有文件开始被陆续公布。第一批发布的内容中有6,000多份文件,共计34,000页,而最后一批发布的文件量至少是它的两倍。要想知道文件的内容,你可能要花几十年的时间来阅读。
为了帮助用户从庞大的数据中探索整个事件,我们利用微软Azure搜索服务和微软认知服务开发了一个应用程序,以从大量的文档中获取洞见,并将原始文档整理成结构化的信息,使用户可以探索底层数据。
关于这个应用程序的详细信息,请访问:Demo演示:https://jfkfiles2.azurewebsites.net/
皮肤癌项目演示
皮肤癌是最常见的一种癌症,占全球所有癌症病例的40%。幸运的是,只要在早期被检测出来,皮肤癌就可以被有效地控制。为此,我们希望为每个人创建一个移动的AI应用程序,以便能够快速检测用户是否有患皮肤癌的风险,同时帮助医生提高效率。
该皮肤癌项目使用了ISIC皮肤癌数据集,利用端到端的预览版Azure机器学习服务来创建皮肤癌检测的机器学习模型,并可以在手机上运行该模型。你可以在以下链接中查看皮肤癌项目的数据集、源代码及演示视频等信息。
项目中使用到的ISIC数据集GitHub链接:https://github.com/antriv/ISIC-Dataset-Downloader
项目源代码:https://github.com/Azure/ai-toolkit-iot-edge/tree/master/Skin%20cancer%20detection
项目演示视频:https://channel9.msdn.com/Events/Connect/2017/T109
雪豹项目演示
雪豹是高度的濒危动物,全球野生雪豹的数量大约仅在3,900至6,500只之间。由于栖息地偏远、活动范围广阔且拥有难以捉摸的本性,雪豹的研究工作很难进行。因此,很少有人知道它们的生物特点、存活率和运动模式等信息。要想真正了解雪豹并更直接地提高它的存活率,我们还需要更多的数据。
为此,生物学家们在雪豹经常出没的地区安装了许多运动摄像头,以记录它们的活动。多年来,这些相机已经获取了超过100万张的图像。这些图像既可以被用于了解雪豹的行为,也可以用于建立新的保护区。
但是生物学家必须对所有图像进行分类,以识别雪豹或猎物的图像。手动分类就像在干草垛里找一根针一样困难,对一个相机拍摄的图像进行分类就需要大约300小时。为了解决这个问题,国际雪豹基金会(Snow Leopard Trust)和微软合作,使用大规模神经网络建立图像分类模型。你可以在以下链接中查看雪豹项目的源代码及演示视频等信息。
项目源代码:https://github.com/mhamilton723/snow-leopard/blob/master/Saving%20Snow%20Leopards%20with%20MMLSpark.ipynb
项目演示视频:https://channel9.msdn.com/Events/Connect/2017/G102
借助微软强大的AI工具,开发人员只需一点编程技术,就可以轻松将AI融入到应用程序中,让应用程序变得更智能,跟用户沟通更加友好、自然,并且还可以帮助用户充分利用大数据。