【按:在深度学习“红透”半边天的同时,当前很多深度学习框架却面临着共同的性能问题:被频繁调用的代数运算符严重影响模型的执行效率。本文中,微软亚洲研究院研究员薛继龙将为大家介绍能够轻松玩转计算性能的“加速神器”——内核融合,探讨内核融合在加速深度学习上的主要方法以及当前面临的主要挑战。】
如今,较为常见的深度学习框架(如CNTK、TensorFlow和Caffe2等)都会将一个深度学习的模型抽象成为一个由一些基本运算符(Operator)组成的有向无环的数据流图(DAG),然后再由下层计算引擎按照某一种拓扑序来依次调度并执行这些节点对应的内核函数,从而完成一个模型的执行。为了能够支持在不同的硬件上进行计算,一个Operator往往会对应多个内核函数的实现,例如,GPU上的内核函数是由CUDA或者一些GPU的函数库(如cuDNN、cuBLAS等)提供的操作组合而成。
为了提供较好的灵活性,大多深度学习框架中的Operator都是定义在了代数运算符这个粒度上,例如向量的加、减、乘、除和矩阵乘法等等,一般的计算框架都会有几百甚至上千个Operator。由于这些运算符的抽象粒度较低,所以一个真实的训练模型的数据流图往往会包括数千个节点,这些节点在GPU上的执行就会变成数千次GPU上的内核执行。这些粒度较小的内核函数在提供了灵活性的同时,其频繁的调用也成为当前影响许多深度学习框架性能的一个重要因素,其带来的性能开销主要体现在:数据流图的调度开销,GPU内核函数的启动开销,以及内核函数之间的数据传输开销。
解决这些性能问题的一个直接方法就是内核融合(Kernel Fusion)。所谓内核融合,就是将一个计算图中的节点所对应的内核函数融合成一个函数,使得整个数据流图只需要通过一次函数调用即可完成,从而减小平台调度和内核启动带来的开销。并且,通过合理地设计不同内核函数的输入输出数据的放置(例如使用GPU上的共享内存或寄存器),可以极大地提高数据传输效率,从而提升整体计算性能。
为了展示内核融合能够带来的好处,我们对比了一个80步长的单样本LSTM网络在TensorFlow上的模型推理(inference)时间和我们手工将所有计算融合并优化在同一个内核函数中的计算时间(图1)。可以看出,在相同的GPU上,融合的内核函数比TensorFlow上基于图的计算可以快40倍左右。当然,这里的TensorFlow与手动融合的内核的性能差距除了来源于上述性能开销外,还包括TensorFlow本身的框架开销。
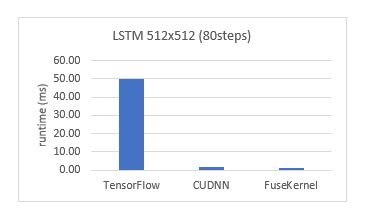 LSTM网络在TensorFlow上的执行时间和手工融合内核的执行时间对比
LSTM网络在TensorFlow上的执行时间和手工融合内核的执行时间对比
然而,为每一个计算图的内核函数进行手工融合并不是一种可以扩展的方法。因此,研究自动化的内核融合成为最近的一个热点,例如TensorFlow中的XLA项目就是要将给定的计算图生成硬件设备相关的机器码,再如NNVM-Fusion是DMLC社区为加速MXNet所提出的相关项目,还有最近比较流行的动态图计算框架PyTorch也开始逐渐引入内核融合的技术来提升性能。
自动化的内核生成一般包括以下几个步骤:1. 图优化。即在进行内核融合之前,首先对计算图进行分析并应用一系列与硬件无关的优化策略,从而在逻辑上降低运行时的开销,常见的类似优化策略包括常数折叠(constant folding)、公共子表达式消除(common subexpression elimination)等;2. 检测融合子图。即在给定数据流图中,找出一些可以被融合的图节点,这些节点往往是一段连续的子图。3. 代码生成。在给定一个融合子图,为其生成一份内核函数代码。这里可以直接生成与硬件相关的代码,也可以先生成到一个统一的中间表示层(intermediate representation),如LLVM,然而再由相应的编译器将其编译到与针对特定硬件的执行代码,TensorFlow的XLA就采用了后者的方法。4. 图的修改。即将融合后的内核所对应的Operator替换之前的子图,并插入原来的数据流图中。整个流程如图2所示。
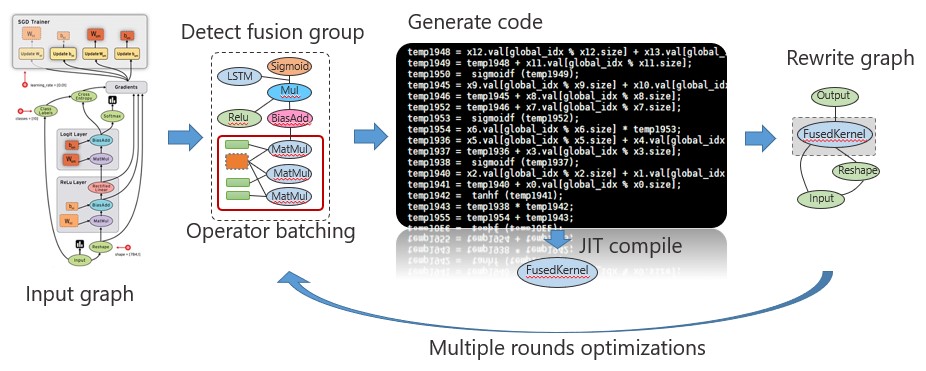 内核融合在数据流图计算框架中的应用流程
内核融合在数据流图计算框架中的应用流程
然而,自动化的内核融合并生成高效的内核代码还存在着许多挑战,如何解决内核间跨线程的数据同步和如何实现高效的线程模型及任务划分都是非常重要的问题。
内核间的数据同步
当前,在GPU上的内核融合技术大部分都只支持element-wise的Operator,如PyTorch和NNVM-Fusion。其主要原因是由于CUDA采用的是SIMT(单指令多线程)的编程模型,这使得融合element-wise的操作更加容易。例如,在图3的示意图中,如果我们想将y1=x1+x2 和h=sigmoid(y1) 两个计算表达式进行融合,那只需要让每个线程都处理输入向量中的一个元素并且执行相同的表达式h=sigmoid(x1+x2) 即可,在这种情况中,由于融合后的计算逻辑都在相同的一个线程内完成,所以前一个计算输出的结果可以通过寄存器或共享内存直接传到下一个计算的输入中。
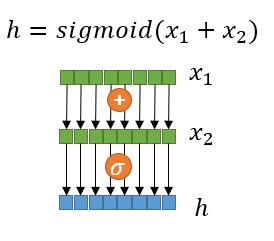 GPU上的element-wise内核融合示意图
GPU上的element-wise内核融合示意图
然而,如果我们想将两个矩阵乘法、或更加复杂的计算(如卷积操作)融合在一起,就需要引入数据之间的同步机制,即前一个内核完成的结果需要传播到下一个内核的部分或全部线程中。这时,若想融合这样的内核,我们必须有较为灵活的同步机制。然而,在CUDA 8.0之前,CUDA只支持同一个线程块内的计算同步,其无法满足融合的需求。Shucai Xiao等人早期提出一种能支持全局跨线程块的同步机制,但其需要对计算的资源有一定的假设,即要求线程块个数要小于SM的个数。最近,在Nvidia发布的最新版CUDA 9.0中首次提出了Cooperative Groups的概念,其可以灵活地支持不同粒度上的线程同步,这将会使得在GPU上的更加复杂的内核融合变得容易,也同时为实现更加高效的融合提供了更多空间。
线程模型与任务划分
内核融合中另一个挑战是如何优化任务的划分,从而充分发挥GPU的计算和片上存储性能。我们知道,执行一个GPU的内核函数,不仅需要指定内核函数的计算算法,还需要指定其调度逻辑,即如何分配线程块的大小和数量等等。通常,这需要有经验的程序员根据计算算法的特性仔细地设计每一个内核的调度逻辑。然而,在本文介绍的内核融合的场景中,我们需要系统能够根据当前使用的GPU架构快速、自动化地生成调度逻辑。因此,目前一种研究趋势是采用来自于MIT的Halide项目的思想,即通过将计算算法和调度逻辑进行抽象并分离,然后采用一些搜索算法来找到较优的调度方案,从而自动生成最终的执行代码。Halide项目是针对图像处理所设计的编译系统。目前,像来自DMLC的TVM项目、以及MIT的Taco项目都采用该思想并针对深度学习库进行自动化的优化,目前大部分这些项目还都还处在较早期阶段。