
近日,美国赛灵思公司收购中国AI 芯片初创公司深鉴科技的重磅消息另业界备受关注,作为FPGA技术的首创者和引头军,赛灵思的创新技术也是众多开发人员学习借鉴的标杆。就在2018全球存储半导体大会上,笔者聆听了一场由赛灵思数据中心架构师唐杰带来的题为《数据通道“硬”化,ARM存储系统的加速器》的精彩演讲,在此与大家分享:

以下内容整理于演讲实录,未经演讲人最终确认:
为什么做FPGA,可以看到一些趋势,第一个是数据爆炸,第二是人工智能的兴起,第三个就是后摩尔定律时代,不可避免要走向异构计算。说到NVMe Over Fabric,主要解决Storage Disaggreation,把原来插在服务器背板的NVMe拿出来,可以推到远端,和从传统的DAS走向SAN这个概念是一样,把高性能资源重复利用,同时又能够集中管理。某种意义上讲,FPGA是一种芯片可编程的芯片,不需要做很多的工作,这里有一个关键点,赛灵思发展FPGA分三个阶段,第一个阶段我们为芯片做验证,做原型系统,移动通讯爆发的年代,外面的各个基站,我们做这种天线矩阵、信号处理,包括任何雷达里面都会有FPGA的芯片,为什么要讲到数据中心,就是因为我们在全球有一个比较大的云,Microsoft Azure大量部署FPGA做异构计算,很多教授都讲过,为什么FPGA介入数据中心,就是为了做异构计算。做异构计算我们讲很关键一点,ARM在移动系统慢慢往数据中心走,大家都知道,做NVMe,我们就要关心PCIe,从某种角度,对ARM来讲是一个非常大的弱点,很少有手机的GPS能够支持PCIe,而赛灵思FPGA方案可以提升基于ARM的控制系统性能的可靠性。
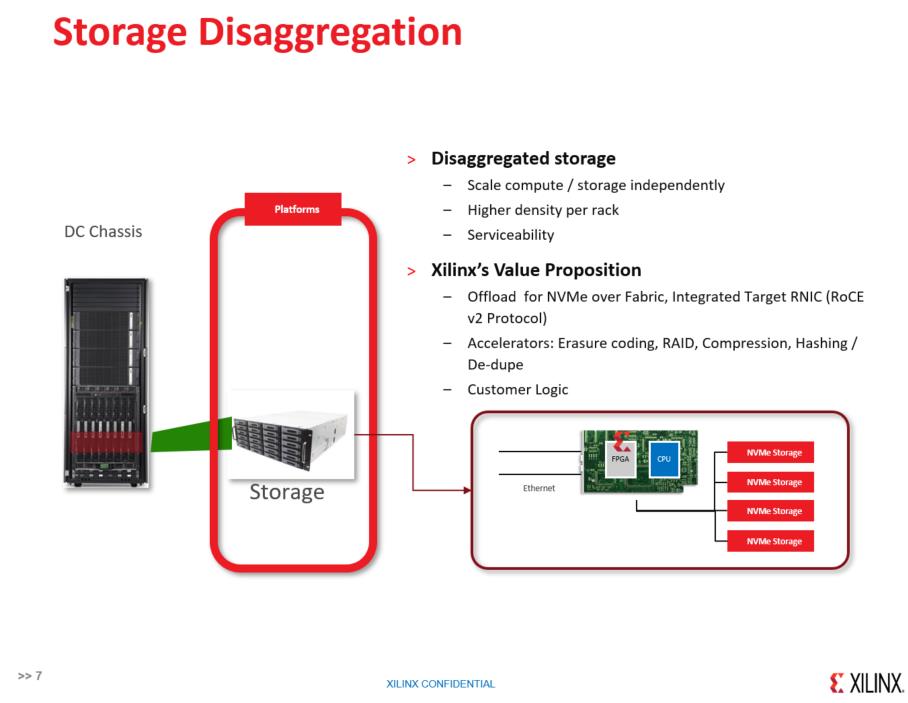
对于DISAGGREGATION和FPGA的芯片来讲,我们天生可以支持5个PCIe盘,可以挂100G的系统,某种意义上讲,既可以支持PCIe也可以支持100G,底层都是串行服务。所以说,我们还不仅做这个,还可以加入一些定制的加速功能,就是我们讲的可以做coding、RAID、哈希、压缩等等,还有做客户的定制内容。整体的架构来讲的话,可以做到一个标准的24盘位JBOF,提供对外输出100G性能,把100G的带宽跑满4K性能。
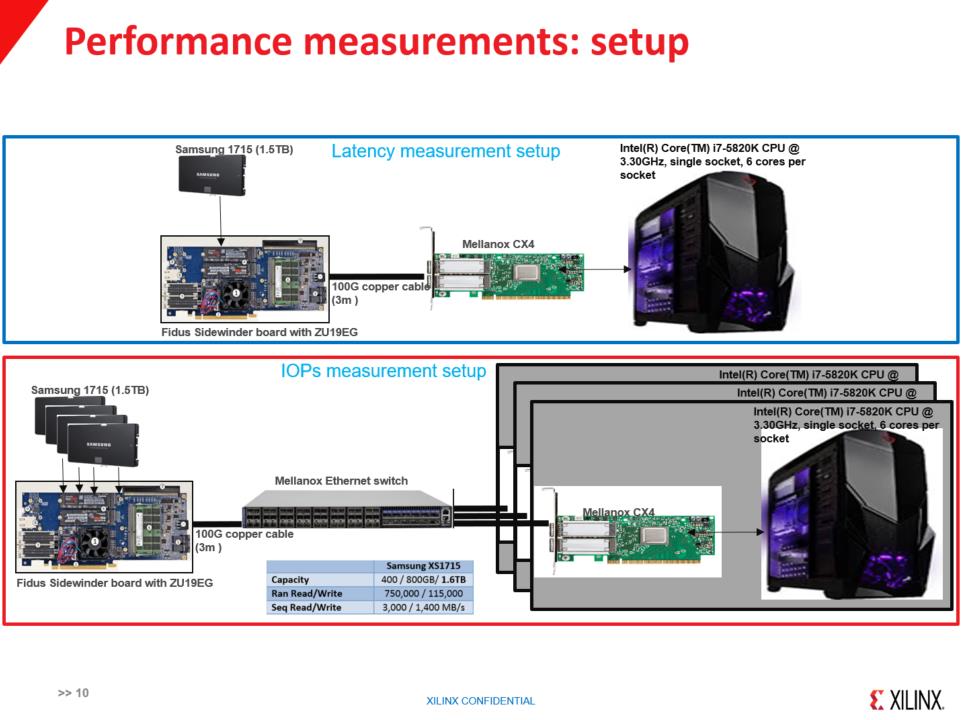
测试环境,上面测延时,下面测IOPS。在下面使用四个盘连在板子上,直接连接过来,测试性能,我们可以看到,在4K的情况下,随机读都是在2.32Millon,写的话基本上在1.1Millon左右,盘的写和读的概念比较大,延时差别,不管是顺序读的还是无序读,是在2-8M之间,写增加的延迟是在5-10M之间,为什么延时增加不一样,大家如果做PCIe协议,就知道读写是不一样的,写的时候不需要返回,读的话需要一个返回,所以不涉及介质的话,写是比读要好。在后续写的时候,其实是数据准备好了以后,发包,RAID读数据,然后写在后面的盘上,这就造成读写增加延时,对于小包没有苛刻要求的话,在写的时候把包里面数据放进去,这样就可以做到读和写延时差不多的时间。
关于存储产品路线,我们看标准的盘,或者具有标准的NVMe标准接口,都可以通过FPGA连接上去,会有一定的DDR控制器,在FPGA里有一个NVMe IP设置,在NVMe里通过一个地址转换成可以发送到后端的NVMe标准命令。
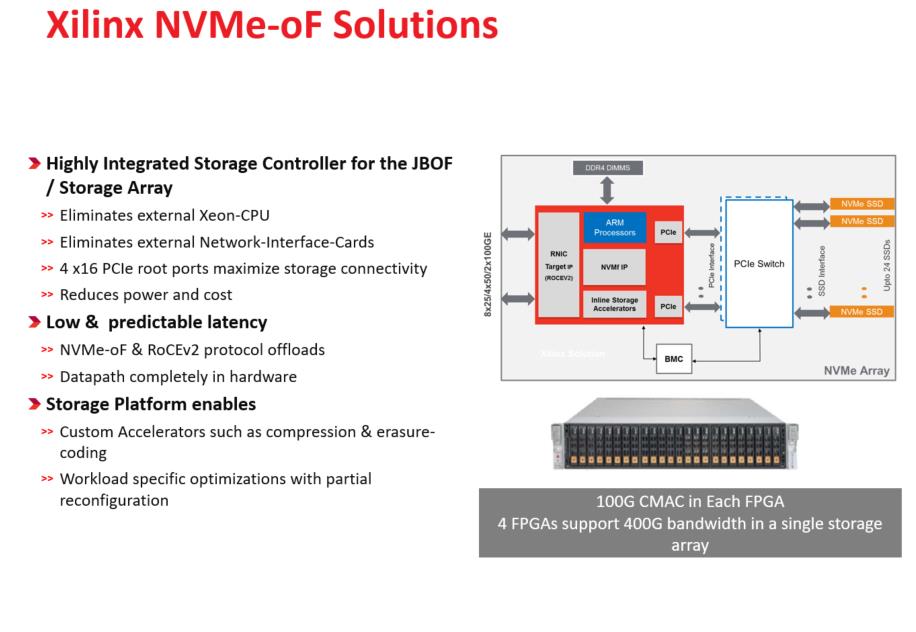 我们现在做的东西就是想做一个NVMe HBA,比如说客户要一个盘要128T,那我可以找三星英特尔,他说不好意思我可能要等到两年以后,那怎么办?
我们现在做的东西就是想做一个NVMe HBA,比如说客户要一个盘要128T,那我可以找三星英特尔,他说不好意思我可能要等到两年以后,那怎么办?
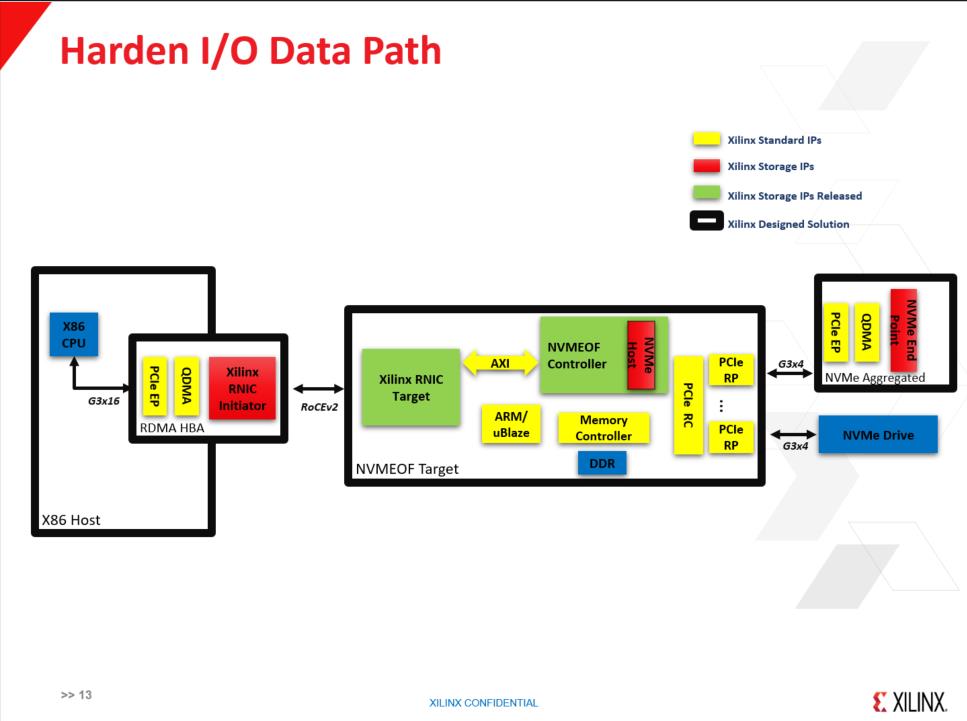
我甚至可以支持虚拟化,可以做很多的基于NVMe的事,基于此,中段可以从16个盘变成一个盘,大大降低对主机CPU的占用,这些我都会放在FPGA里,减少CPU的使用。现在大家都面临一个问题,CPU拿来卖而不是拿来跑盘。举个例子,对100G的包做一个分流,所有的I/O的包全部通过硬件输出,因此任何一个小小的ARM都可以来做存储控制器,所以要做I/O和数据分流。我们的计划就是,把NVMe加进去,大家可以想像,假如我是一张网卡,对于主机来看我是一个NVMe盘,我这个盘子上面可以切成很多的小盘子,对于用户来讲,我们所做的事情就是希望把和CPU打交道的接口,能够通过FPGA做硬件的实现,降低I/O等等对CPU的占用。一个IP打包,然后集成到一个芯片,或者一个系统里面。
赛灵思成立于1984年,已经35年了,总部在硅谷,中国北京有一个研发中心,我们现在所有的员工有4000人,我们客户差不多有2万多个客户。看一下,我们全球大概有4300多个合作伙伴,我们出品全球第一款FPGA,第一个挂ARM存储系统,随着数据爆炸和AI的兴起,以及后网络时代的到来,不可定义的就要FPGA。把原来差的服务器拿出来,可以推到远端,从传统的原来的DAS走向SAS这个概念是一样,把我们高性能的资源重复利用,同时又能够集中管理,好处颇多。
赛灵思的创新在于基于FPGA方案,实现了数控分离,在ARM系统上实现I/O控制,形成完整的数据通路。







