
 李洪革在演讲中首先对比了近年来全球集成电路的整体市场情况,在2018年上半年全球集成电路市场,全球Top15企业排行中,美国依然是主场,美国企业控制了60%的市场,而韩国,日本,中国台湾,欧洲则各自为营排列其后,进一步表明集成电路相关顶级产品依然是由国外垄断和控制。
李洪革在演讲中首先对比了近年来全球集成电路的整体市场情况,在2018年上半年全球集成电路市场,全球Top15企业排行中,美国依然是主场,美国企业控制了60%的市场,而韩国,日本,中国台湾,欧洲则各自为营排列其后,进一步表明集成电路相关顶级产品依然是由国外垄断和控制。
 全球芯片战场概览
全球芯片战场概览
 传统集成电路芯片可以放置在Amp,RF,ADC上,它们在芯片市场占比达22%;
存储器(DRAM,SRAM等),以三星,美光,海力士为代表,所占份额达到29%;
传统CPU,英特尔依然是一头独大,AMD最近也逐渐被边缘化,其在芯片市场占比22%;
以ARM为核心所诞生的移动处理器市场潜力巨大,由高通,苹果,博通等巨头领衔,在芯片市场占比16%;
在上周五,华为宣布推出7纳米的AI芯片,这意味着华为已将AI CPU,列为与CPU,GPU并行的第三个处理单元,未来市场趋势是否会向AI CPU倾斜,需要时间来验证。
各领域芯片产业界的地位
传统集成电路芯片可以放置在Amp,RF,ADC上,它们在芯片市场占比达22%;
存储器(DRAM,SRAM等),以三星,美光,海力士为代表,所占份额达到29%;
传统CPU,英特尔依然是一头独大,AMD最近也逐渐被边缘化,其在芯片市场占比22%;
以ARM为核心所诞生的移动处理器市场潜力巨大,由高通,苹果,博通等巨头领衔,在芯片市场占比16%;
在上周五,华为宣布推出7纳米的AI芯片,这意味着华为已将AI CPU,列为与CPU,GPU并行的第三个处理单元,未来市场趋势是否会向AI CPU倾斜,需要时间来验证。
各领域芯片产业界的地位
 传统处理器市场,由英特尔,AMD,IBM等垄断;存储器领域,三星和海力士主导;在image sensor(图像传感器)细分领域中,日本索尼则排位第一,而AI芯片方面(ISSCC2018没有称之为AI芯片,而是将概念扩展为Neuromorphic类脑计算),近年来美国,韩国,日本,欧洲都在不断发力人工智能芯片市场,美韩两国具有领先优势,而国内研究则有待加强。
传统处理器市场,由英特尔,AMD,IBM等垄断;存储器领域,三星和海力士主导;在image sensor(图像传感器)细分领域中,日本索尼则排位第一,而AI芯片方面(ISSCC2018没有称之为AI芯片,而是将概念扩展为Neuromorphic类脑计算),近年来美国,韩国,日本,欧洲都在不断发力人工智能芯片市场,美韩两国具有领先优势,而国内研究则有待加强。
 人工智能的新一轮热点是完全基于传统神经网络的计算兴起,因此李教授科普了神经网络的发展历史。
李教授指出, Neuromorphic研究成果基本集中在计算能力和性能上。而在1998年,卷积(深度)神经网络之所以没有流行是因为其在初期需要进行大量计算,但当时的芯片工艺几乎不可完成,之后我们也可以看到英特尔和英伟达计算力的提升基本与芯片工艺的尺寸成正比,因此卷积(深度)神经网络能够在如今大规模发展完全得益于片上系统的高性能计算,没有纳米级IC支撑,网络很难真正实用化。
深度学习神经网络主要由三层组成,前两层是全连接和输出层,是标准的双层BP网络。其区别在于后面增加了N层卷积计算层来进行特征提取。DNN由微软从5层拓展到152层来增强计算力,其中卷积计算就消耗了90%以上的计算和运行资源。但相比之前,耗时耗力的利用软件方式进行特征提取再放置到网络进行特征分类,也实在是简单粗暴。
未来,深度学习神经网络的角力场将会是医疗诊断,金融服务,图像识别,工业机器人,无人驾驶,人机博弈方面。
AI芯片的主流架构有哪些
人工智能的新一轮热点是完全基于传统神经网络的计算兴起,因此李教授科普了神经网络的发展历史。
李教授指出, Neuromorphic研究成果基本集中在计算能力和性能上。而在1998年,卷积(深度)神经网络之所以没有流行是因为其在初期需要进行大量计算,但当时的芯片工艺几乎不可完成,之后我们也可以看到英特尔和英伟达计算力的提升基本与芯片工艺的尺寸成正比,因此卷积(深度)神经网络能够在如今大规模发展完全得益于片上系统的高性能计算,没有纳米级IC支撑,网络很难真正实用化。
深度学习神经网络主要由三层组成,前两层是全连接和输出层,是标准的双层BP网络。其区别在于后面增加了N层卷积计算层来进行特征提取。DNN由微软从5层拓展到152层来增强计算力,其中卷积计算就消耗了90%以上的计算和运行资源。但相比之前,耗时耗力的利用软件方式进行特征提取再放置到网络进行特征分类,也实在是简单粗暴。
未来,深度学习神经网络的角力场将会是医疗诊断,金融服务,图像识别,工业机器人,无人驾驶,人机博弈方面。
AI芯片的主流架构有哪些
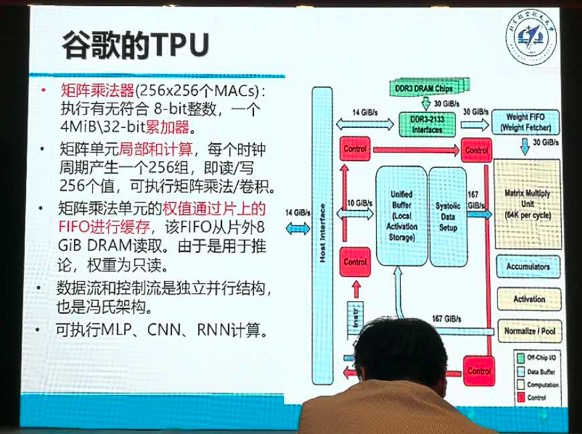 1.谷歌TPU。延用了传统的CPU和GPU技术,但通过一些技术的差异化及缺陷调整,性能快了15-30倍,采用28纳米制程工艺。不过计算方式仍是标准的冯诺依曼体系架构,即数据流与控制流独立并行的架构。优势是进行包括MLP,CNN,RNN的多层计算。
1.谷歌TPU。延用了传统的CPU和GPU技术,但通过一些技术的差异化及缺陷调整,性能快了15-30倍,采用28纳米制程工艺。不过计算方式仍是标准的冯诺依曼体系架构,即数据流与控制流独立并行的架构。优势是进行包括MLP,CNN,RNN的多层计算。
 2.IBM提出的Truenorth神经拟态处理器。完全基于人脑架构制成的类脑计算,功耗仅为65毫瓦。
2.IBM提出的Truenorth神经拟态处理器。完全基于人脑架构制成的类脑计算,功耗仅为65毫瓦。
 3.基于PE阵列的MIT Eyeriss芯片架构。功耗为278毫瓦。
3.基于PE阵列的MIT Eyeriss芯片架构。功耗为278毫瓦。
 4.哈佛为DNN加速设计的芯片架构。采用稀疏矩阵,算法和架构有了质的变化。采用28纳米技术,功耗达到23.5毫瓦。
4.哈佛为DNN加速设计的芯片架构。采用稀疏矩阵,算法和架构有了质的变化。采用28纳米技术,功耗达到23.5毫瓦。
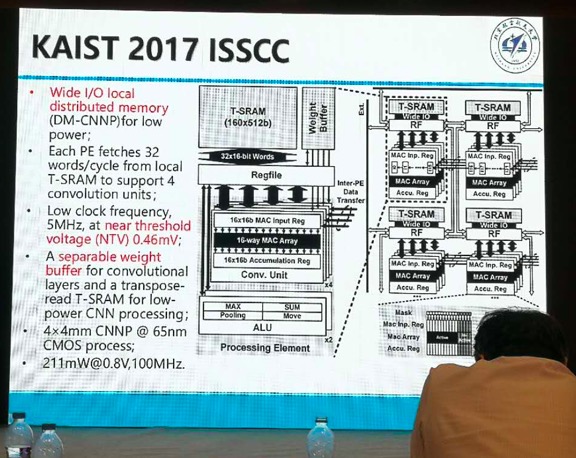 5.韩国科技技术院(KAIST)设计的芯片架构。
5.韩国科技技术院(KAIST)设计的芯片架构。
 6.佐治亚理工设计的芯片架构。
6.佐治亚理工设计的芯片架构。
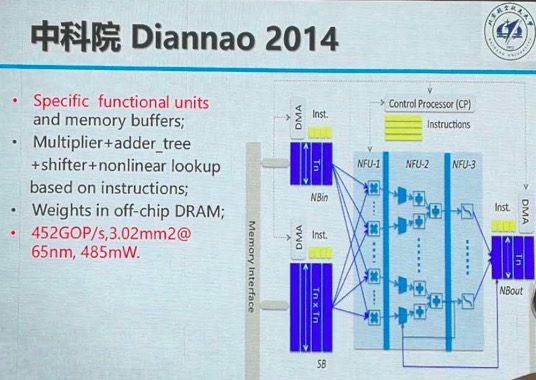 7.2014年中科院设计的Diannao芯片。
李教授还在最后提及了神经网络的未来发展方向:云端深度学习神经网络处理器,终端深度学习神经网络处理器,神经拟态处理器。
7.2014年中科院设计的Diannao芯片。
李教授还在最后提及了神经网络的未来发展方向:云端深度学习神经网络处理器,终端深度学习神经网络处理器,神经拟态处理器。

本文来源于DOIT传媒,文章内容仅供参考,不构成投资建议。


评论列表