2018年12月12日,2018中国存储与数据峰会的闪存存储与应用论坛上,Memblaze软件开发高级总监袁戎详细介绍了用NVM set和Namespace实现host可控的flash管理,袁戎此次介绍内容详实,干货十足,是有大量测试和优化实践经验之后得到的宝贵内容,非常值得推荐和学习。另外,本场闪存存储与应用论坛得到了Memblaze高级副总在张泰乐的策划邀请了包括英特尔、美光、阿里巴巴的用户专家以及大家非常熟悉的存储界KOL冬瓜哥,整场内容既权威又丰富而且干货十足。
以下内容根据现场速记整理,未经演讲人本人确认,或有疏漏刊物,仅供参考:
张泰乐:感谢美光的陈诗义先生,站在最前沿的技术探讨了QLC、Xpoint、AI、ML这些应用,我觉得这是一个非常好的介绍。我们知道最近可能SSD上最主要的接口就是NVMe,NVMe这个接口有一个非常大的好的地方就是它能够高速地运用到多通道进到多核,把速度可以达到非常高。但是它继承了大量过去的块接口作为一种交互的界面,但是作为这种块接口它就不可避免有一些问题,如果对SSD有了解的就会知道SSD里面有很多后台需要处理,而这些后台的处理方式对于上层应用是不可见的,所以使得有时候SSD的延时对上层来讲是不可控的状态。
我先想请Memblaze的同事袁戎,来给大家分享在NVMe世界大家怎么解决这个问题?下面我们有请袁戎来介绍NVMe Set和Namespace实现Flash的可控管理。

袁戎:非常感谢大家今天来听我的演讲,我希望能够在这个演讲中给大家带来一些干货,这是我们在NVMe这个领域,Memblaze不断地去实现、演进这个协议做的一些探索。
PCIe SSD的发展阶段一:性能峰值
首先我想说一下,其实我们大家都知道我们SSD拿到最外面讲的东西都是它的性能,它的性能是非常优越的。我们从客户的角度来看,我们对一个SSD的追求其实我们大家很多人都可以看到各种各样的评测,铺天盖地的都会大讲SSD顺序读、顺序写、随机读、随机写的能力到底是多少,我们把这叫做(PCIe SSD)最开始的性能追求阶段一。
SSD的性能追求阶段二:IO低延迟
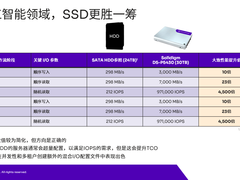
当前的NVMe SSD已经比SATA SSD在性能方面有了巨大的质变了,我们还知道SATA SSD是集中在600MB/s以下的传输数据。在NVMe阶段上,我们可以把大量的Flash带宽利用到,直接透传给Host,让Host享受到最高的读写带宽。
所以NVMe SSD可以达到接近6GB/s的读和接近4GB/s的写,100万IOPS,这在SATA SSD的时代都是完全不能想象的数字。但是实际上很少有客户真的能够把NVMe SSD的性能能够利用到极致,这就带来了我们看到的第二个阶段的性能追求。
我们平时所说的所谓的顺序读、顺序写、随心读、随心写的性能,其实它标称的数据我们在现实生活场景中很难遇到。首先我们知道顺序写的测试需要单线程,如果多线程引入了之后,顺序写的东西在落盘的时候实际上会变成随机写,自然就带来了额外的垃圾回收效果在里面,这些效果会导致我们硬盘实现的性能其实是会有一定下降的。
同样,我们在随机写的测试中也有一些很苛刻的要求,测试它需要极高的压力,这样它才能够把这些性能发挥到极致。这样的测试环境往往在现实中不常见,导致用户感受不到性能带来的变化,我称之为这是阶段二的性能追求,本质上的原因是需要低延时。
不管是什么样的IO模型,不管是多小的IO请求,我的每一个IO都必须从硬盘上得到一个最及时的响应,这意味着不管在什么样的应用场景,请求都能够得到最高速的响应,这样才能够体现出你的性能在整个系统级是低延时的。
那么NVMe SSD做了什么来做到极低的延迟?从系统的IO路径角度,NVMe比原来的SATA SSD多了很多优势,原来的SATA SSD的CPU从芯片和内核要走到南桥,再通过南桥和SATA 的Bus再加上SATA 协议的一些东西,导致它天生延时就是非常高的。NVMe通过PCIe直接连接到CPU内部,就把这些全部都给抹杀掉了。
我们现在可以看到最高性能的SSD档次已经做到10微秒的响应时间,这10微秒仅仅是把数据从Host送到内存。我们知道Flash响应时间是比较慢的,这个时间在后台操作中对于Host而言根本不用在乎,只要我的电容可以保证这部分的数据从内存写下去,数据只要落地就是安全的,这是主流的SSD都可以保证的东西。
我们可以看到主流的硬盘现在写的延时都已经降到20微秒以下,现在我们自己的产品可以做到10微秒,这个速度会体现在大量应用中,都可以看到我的各种顺序写、小带宽、小压力的写都可以得到快速响应。
另外在读延时没有写延时那么有优势,因为写延时只要把数据落在内存就结束了,但是读的话所有每一笔数据都是来自于你的Flash,这方面最大头的时延其实是在我们的Flash上面。
我们现在知道其实我们的3D TLC主流的Flash已经比2D时代要好了很多了,2D时代那时候还是接近100微秒的读延时,更有极致的产品,我们也非常欣慰地看到Intel推出的一些产品,更加进一步地把Flash上的读延时推进到了一个极致,都已经到了10微秒左右的级别。这样的效果,就会使得我们在NVMe或者SSD上看到的延时效果越来越好,对于用户来说性能感受也就越来越好。
阶段三-NVMe SSD在广泛部署后面临的QoS挑战
从阶段二的性能追求之后,我们又会发现很多的用户现在随着硬盘越用越大,一块硬盘4TB、8TB,一个用户他用不到,他需要分成两个用户(共用一块SSD)。这时候SSD会面临一些新的挑战,因为当两个应用同时在使用一块硬盘的时候,互相会对对方进行一些干扰,这样的干扰可能不会体现在IOPS,你的盘整体性能还是挺高的,但是从每一个用户的角度看来,都会认为旁边的应用(Noisy Neighbors)影响了自己的正常响应。

多个应用共用一块SSD造成延迟提高(Source: facebook)
在用户的真正场景上,QoS是我们重要的第三个挑战。在应用共享SSD的时候,应用之间干扰造成延时的巨幅升高。比如其中一个应用程序在用的时候不停在写,这个写的过程就会对另外一个以读为主的应外造成巨大的影响,这个影响没有办法避免,因为硬盘只有一个。
这个问题怎么解决?我们现在实际上看到了很多解决方案,比如OpenChannel是一个方案,它希望通过对Flash的直接管理能够进行QOS控制。
NVMe的协议从一开始定义到现在,就是纯粹为了Flash而生,它在这方面也有它自己的演进路线。NVMe 1.4的时候有IOD规范的加入,其中文词义就是IO的确定性。实际上它包含了什么内容?实际上它是会在NVMe 1.4加入之后,会把SSD 分成不同的Set,这个Set是一组Flash LUN的集合,称之为一个Set。
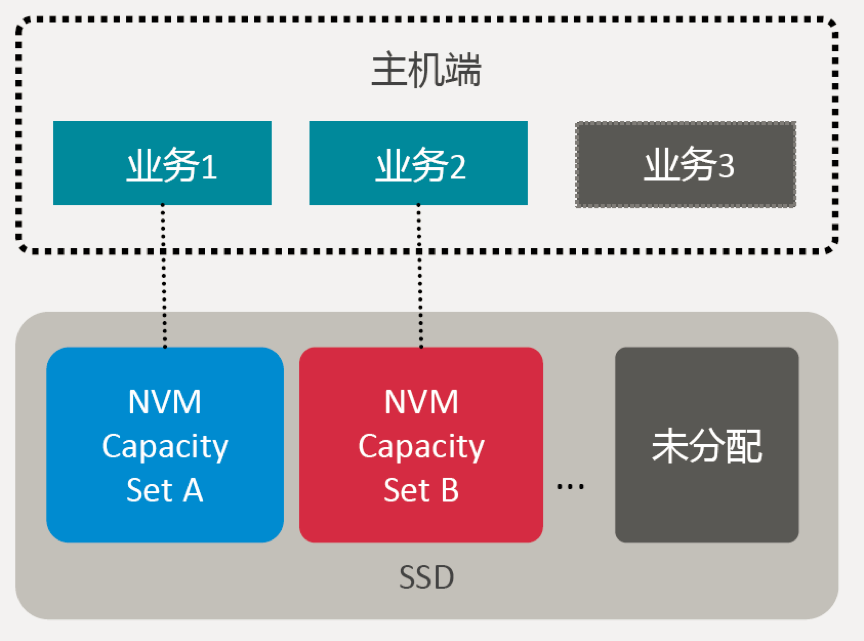
通过NVM Sets机制对设备进行物理隔离
比如说我们可以知道我们现在一个固态硬盘有4通道、8通道、10通道,每个通道上还会有4个、8个、10个LUN,这些LUN可以拆分成一个一个Set,在Set上通过协议划分成不同的Namespace,可以在协议中确定的要求每一个Namespace只属于一个Set或者多个Set。这样当用户访问其中一个Namespace,这部分空间是必须要落在一个确定的Flash LUN上面,也就是一个确定的Set上面。
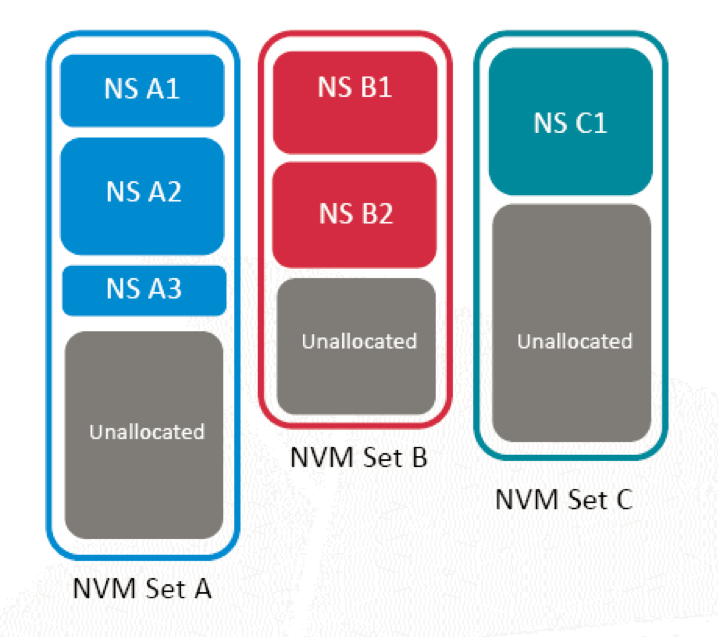
NVM Set
这样的好处很多,两个独立的Flash不像磁盘只有一个磁头,盘片在转的时候无论如何只有一个通道能够出数据,但SSD的场景非常不一样,SSD的场景里面不同的Flash完全可以独立工作,这就带来一个好处,可以把IO的影响彻底隔离。接下来会有具体的实例来看一下我们具体的操作。
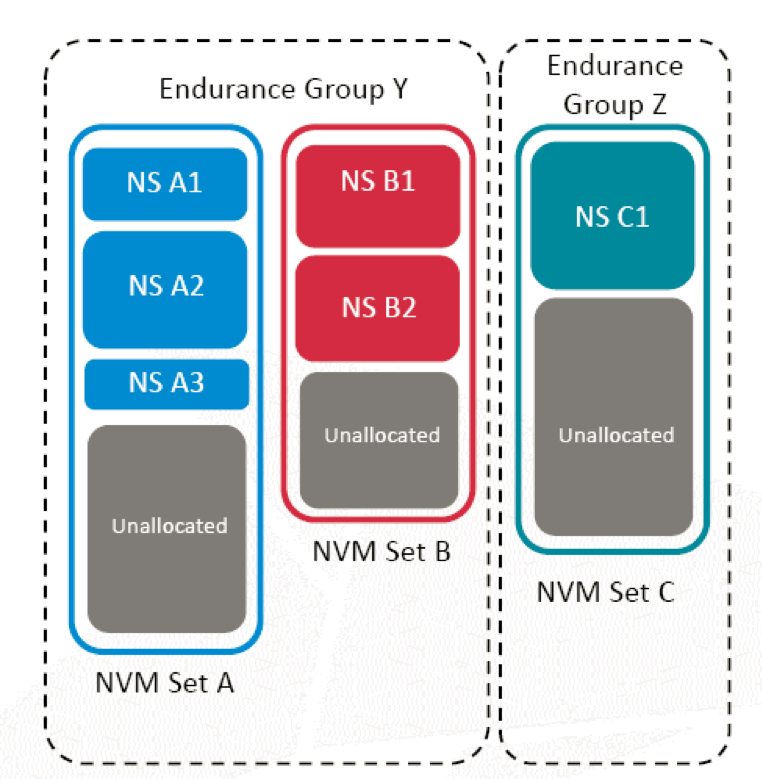
Endurance Group保证NVM Set间磨损均衡
其中在NVMe Group ID的设置里面,除了刚才说的Set,还有Endurance Group的概念(如上图),这个可以让SSD进行磨损均衡的管理。如果只有一个NVM Set和Endurance Group ID关联,磨损均衡范围不能跨越该Set,但主机端可以选择跨Set进行寿命管理。
本质上我觉得Endurance Group带来的好处是说没有规定你的Namespace只能属于一个Set,实际上你的Namespace可以跨多个Set。为什么要跨多个Set?后面我会讲到Set的使用由于它把Flash进行了隔离,也会带来了一定的带宽。如果我们再把Set聚合在一起,我们的性能其实可以根据Set的数量线增增长。
相当于我的用户在面对一个有8个、16个Set的SSD时候,需要有多高的带宽就选几个Set,需要多好的响应就把Namespace放在单独的Set上,这些性能全部都是随着你的Set数量进行线性增长。
验证NVM Set带来的QoS提升
Memblaze对Set在具体的SSD应用中的效果做了几个验证试验。第一个试验是有和没有NVM Set两种状态下SSD的性能表现。
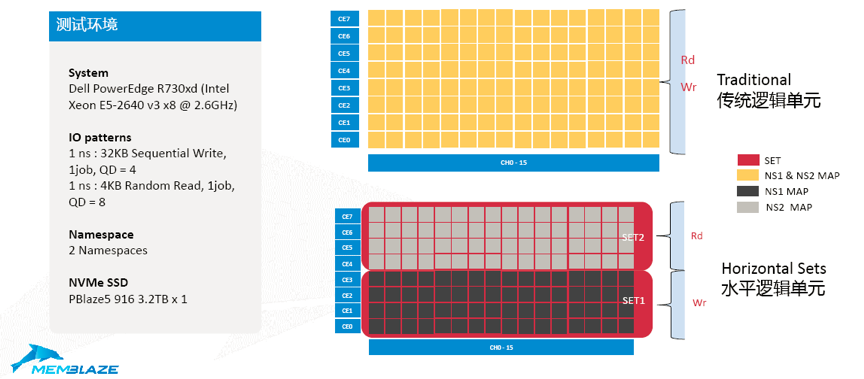
我们这边举的例子是8通道的SSD,上侧小黄块是所有的Flash LUN。这些在使用过程中,你的数据会全部铺在所有的LUN,就会导致我们前面说的问题,不同应用的读写在操作同一个Flash。
NVMe的Set实现有两种典型结构,一种是垂直结构,一种是水平结构。垂直结构的角度,Flash资源一半是属于一个Set,另外一半是属于另一个Set。
另外一种我们还可以看到水平的逻辑单元,每一个Set都是跨越了所有的T,这种IO并行程度会更加高一些,这边的隔离效果感觉会更加好一些,是不是真的是这样子,我们后面会有实测的结果向大家展示一下这两种不同方式带来的差别。
首先我们看一下最传统、最简单的水平逻辑单元。在这个测试中,我们把一块4T的SSD分成两半,每一半占了一半的LUN,我们操作的时候其中一个Namespace是在上面做顺序写,另外一个Namespace做随机读,这是一个非常典型的业务场景,有的业务以读为主,有的业务以写为主,把这两个业务拆成两个Namespace的时候,我们看看它的效果。

我们可以看到黄色这个是读的Latency的,我们可以看到这个线抖的很厉害,这个效果虽然其实还算可以,但在200—250微秒之间,它是在不停抖动,因为你的Flash一会儿在做读、一会儿在做写,不可避免Flash的读会受到写的影响。下面这条蓝色是一条平线,是我们用了Set的功能之后读的操作完全没有受到任何写的影响所达到的效果,100微秒。
我们可以看到这边有2.25倍的提升,再从QoS的角度看99.99%、99.999%、99.9999%的情况下有多大的影响?99.9999%下有21倍的差距,当多个应用读写混合在同一个硬盘上,你的IO延迟必然会遭到影响,延迟动辄到3毫秒、5毫秒、10毫秒,虽然现在有一些Flash的技术,让这种影响最小化。但实际上在QoS看到99.9999%的情况下,这个影响还是非常可观的。反过来我们如果再把两个Flash、两个Namespace、两个Set拆开之后,延迟所受的影响可能就微乎其微了。

上面这两副图表明了我们的IOPS、QD和QoS之间的关系,同样可以看到如果没有NVM Set,我们的QoS大幅下降,QoS的延时水平都在大幅下降,并且我的IOPS是显著翻倍式的提高。原因无它,就是因为专注,SSD的特定的资源池可以在专注做读的操作,或者专注做写的操作,这个时候你的效果是最好的。我们可以看到使用了NVM Set之后,被测设备4K随机读的IOPS提高了2倍,延迟也降低了2倍以上。
NVM Set效果验证二:传统逻辑单元VS 垂直逻辑单元VS 水平数据逻辑单元
接下来我们再看看另外一组对比,这组对比时我们现在将加入垂直逻辑单元的对比。这里的测试设备的资源划分如下图:
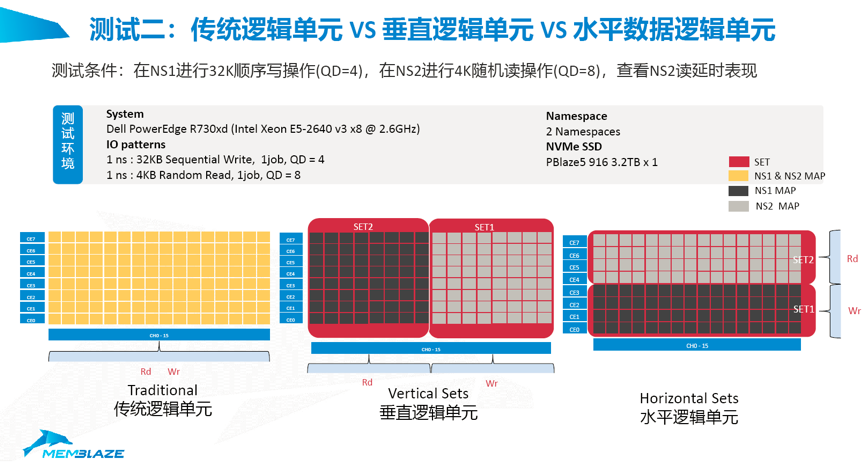
我们在设计的时候会想到垂直的单元由于它的Flash是有独立接口的,我们想象这个效果可能会更好,但是这个测试过当时测出来有点出乎我们的意料,我们来看一下结果。

这里红线是Vertical Sets的结果,蓝线是Horizontal Sets的结果,虽然垂直设置的时候它的Flash接口等等是独立的,但是出来的效果怎么会比水平的情况还会要差一些?
后来我们发现读和读之间由于你的平铺的关系,你在不同的接口上,你利用的Flash BUS数更多了,同时并发的数就更多了。你只用了8个接口和用了16个接口,本身你在同一个接口上的数量更多之后,本身你自己会对自己造成影响。
所以何以看到在Vertical Sets上的时候,读的大压力下去,它的QOS这边比Horizontal Sets要更加小一些。如果你在非常小的读压力下,Vertical Sets由于它完全不受到影响,它的QOS还会要更好一些,这就是压力大小的差别会造成一些细微的变化。从QOS角度来看,不管是Vertical Sets还是Horizontal Sets都对比原来的做法有了接近十几、二十倍的提升。

上图展示了整体的QOS数据。在下面的时候,比如说在99.99%的时候,我们已经看到传统的模式下延时已经上升的很厉害了,大是在使用NVMe Set的情况下,不管是红线还是蓝色都非常低。只有到99.9999%等情况下,才会看到红线、蓝线上升了一点,但即使在这种情况下,跟传统的混合情况下还是有差距。由于Link带来的差距,同样也会反映到IOPS上。不管是在哪个QD,在QD的测试下,我们依然可以发现不同队列深度下性能都是线性增长的,并且它会比我们的传统模式要好得多。
写带宽对比
最后我们再看一下写带宽的对比,当你把Flash切成一半的时候,你的写带宽到底会受多少影响?这个我们也拿出了实测的结果。这条黄线使用了最多的Flash,它的写性能毫无疑问到了2个G以上,这是比后面两种都更高的。黄线的两点几个GB其实也是一个在混和写和读同时操作的情况下得到的写带宽,本身写的带宽受到了上面读的IO影响,并不能有效利用到所有的Flash Learn的能力,我们在V和H的使用情况下,都各用了一半的Flash,导致它其实只有整体带宽的一半效果。实际上你跟传统对比的时候,它大概是在70%左右的情况,所以它使用了一半的Flash带来了70%写的效率,还是非常不错的一个投写。
在这里我们还可以看到在垂直模式,其实比Horizontal Sets模式要略高一点,这个有细微的一点点差别,这也是由于Vertical Sets的模式是不占带宽的,让传输能够更加专注放在上面。所以就我看来,不管是Vertical Sets还是Horizontal Sets,其实都是一个非常有效的隔离手法。具体要怎么使用?这个可能是见仁见智,看你的软件怎么实现更加方便。
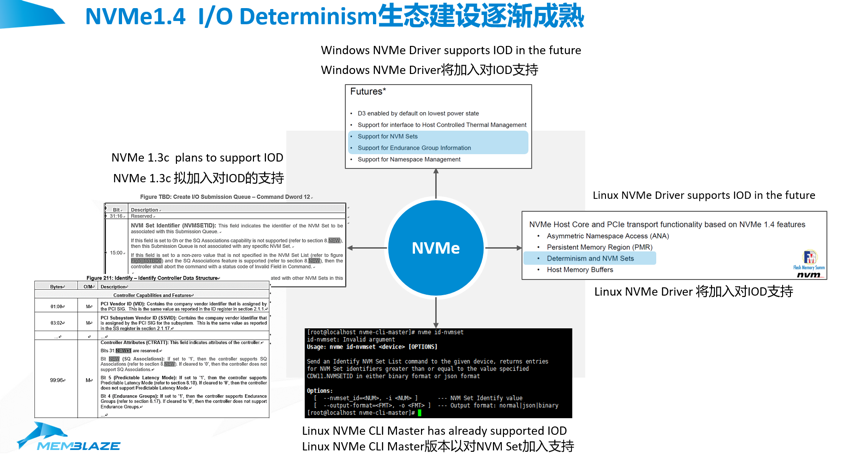
IOD的生态其实在NVMe协议中还是一个正在演进的过程,我们可以看到Windows Driver很快会加入IOD的支持,Linux Driver也会加入IOD的支持,我们常用的管理工具NVMe的CLI也已经支持IOD。最后1.3C和1.4都已经把IOD摆上了日程,并且这是一个比较确定的要发布的东西。所以我们可以看到在整个生态系统中,IOD的支持会是一个快速现金、快速得到全面响应的过程。
回到我们刚开始的话题,我最开始就说了Open Channel的SSD也是为了控制QOS和延时来出生的。我们比较一下Open Channel的SSD跟NVMe的IOD有什么样的优缺点?其实效果毫无疑问Open Channel的效果是更好的?
因为Open Channel的效果是把所有的Flash都交到了Host应用软件的手上,让Host进行有效的管理,这种管理会可以避免在垃圾回收和各种操作的时候对前台IO的影响。
IOD的情况效果会略低,虽然我们刚刚看到的演示效果还是很不错的,但是我们不能不承认我们当时只是对单一Set做了单一操作,这种在应用场景还是比较少的,这要看我们的Host能否真的隔离非常彻底,在每一个Namespace上要么只做读、要么只做写,那种情况下效果比较好。但如果Host的应用还是会采取读写混合等一些奇奇怪怪的操作,SSD的操作不可避免还是会影响到前台的QOS。
从另外一个角度看,Open Channel带来的复杂度远比IOD带来的要高。IOD非常简单,就是把一个SSD在逻辑上分了区,分了区之后就跟你原来使用任何一个硬盘,分几个驱动器是一样的效果。这个非常简单,只要你开始配置好了,后面就不用管了。
第三个就是标准化的程度,Open Channel的标准化现在已经演进到Open Channel2.0,但是在这个基础上还是会有很多需求。对应起来IOD是NVMe1.4的标准协议,我相信它会很快成为所有SSD的标配功能,可以提供到用户去使用。
所以我们最后觉得不同的类型客户,应该是根据自己的情况,根据自己的应用可配置情况、可定制情况能够去选择最合适自己的产品。在这里,Memblaze的SSD我们会随着NVMe的协议一起不停往前去演进,希望能够提供给用户层面更多不一样的功能,提供给更多用户更好的用户体验。我今天的介绍就到这里,谢谢大家!