2018年下半年,UCloud首尔数据中心因外部原因无法继续提供服务,需要在很短时间内将机房全部迁走。为了不影响用户现网业务,我们放弃了离线迁移方案,选择了非常有挑战的机房整体热迁移。经过5个月的多部门协作,终于完成了既定目标,在用户无感知下,将所有业务完整迁移到同样位于首尔的新机房内。
本文将详述这个大项目中最有难度的工作之一:公共组件与核心管理模块迁移的方案设计和实践历程。
计划
整个项目划分为四个大阶段:准备阶段、新机房建设、新旧迁移和旧机房裁撤下线。正如一位同事的比喻,机房的热迁移,相当于把一辆高速行驶高铁上的用户迁移到另一辆高速行驶的高铁上,高铁是我们的机房,高铁上的用户是我们的业务。要让迁移可行需要两辆高铁相对静止,一个方法是把两辆高铁变成一辆,如此两者速度就一致了。UCloud机房热迁移采用类似方案,把两个机房在逻辑上变成一个机房。为此,上层的业务逻辑要在新老机房间无缝迁移,下面的管理系统也要统一成一套。

其中,我们SRE和应用运维团队主要负责以下几个工作:1)机房核心ZooKeeper服务的扩缩容服务;2)核心数据库中间层udatabase服务的部署和扩容;3)大部分管理服务的部署和迁移;4)核心数据库的部署和迁移。以上涉及到前期规划、方案设计、项目实施、稳定性保证、变更校验等所有方面。
挑战
我们刚接到机房整体热迁移需求时,着实有些头疼,首尔机房属于较早期部署的机房之一,相关的技术架构比较老旧。而核心数据库、核心配置服务(ZooKeeper)、核心数据库中间层(udatabase)等几个服务都是比较重要的基础组件,老旧架构可能会因为基础层面的变动发生复杂的大范围异常,从而影响到存量用户的日常使用。
幸好SRE团队在过去一年里,针对各种服务的资源数据进行了全面的梳理,我们开发了一套集群资源管理系统(Mafia-RMS) ,该系统通过动态服务发现、静态注册等多种手段,对存量和增量的服务资源进行了整理,每一个机房有哪些服务和集群,某个集群有哪些服务器、每一个实例的端口/状态/配置等信息,都记录到了我们的资源管理系统中,如下图所示:
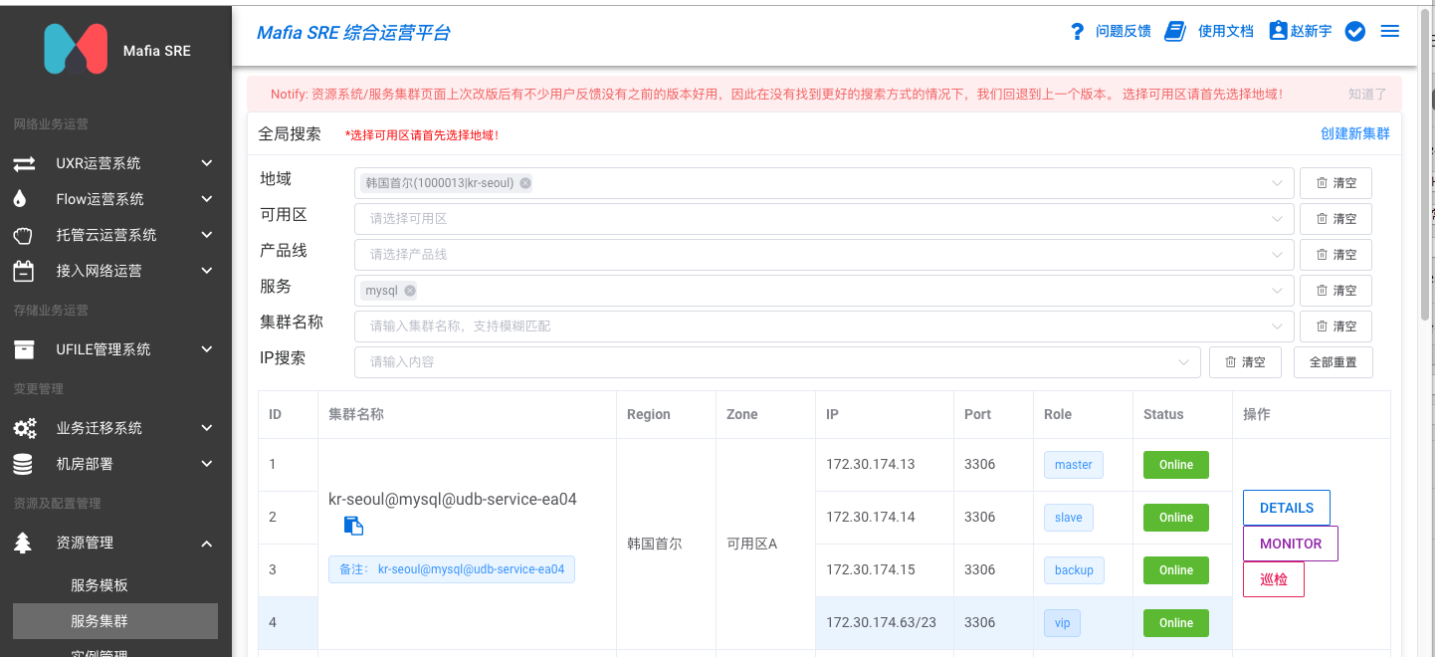
图1: UCloud SRE资源管理系统-集群管理功能
通过SRE资源管理系统,可以清楚地知道首尔机房存量内部服务的集群信息、每个实例的状态。我们基于SRE资源系统还构建了基于Prometheus的SRE监控体系,通过上图右侧Monitor按钮就可以跳转到监控页面,获取整个业务的实时运行状况。
有了这些资源数据之后,剩下的就是考虑怎么进行这些服务的扩容和迁移工作。
ZooKeeper服务的扩缩容
首先是内部服务注册中心ZooKeeper的扩缩容。
UCloud内部大规模使用ZooKeeper作为内部服务注册和服务发现中心,大部分服务的互访都是通过使用ZooKeeper获取服务注册地址,UCloud内部使用较多的wiwo框架(C++) 和 uframework (Golang) 都是基于主动状态机定时将自己的Endpoint信息注册到ZooKeeper中,相同Endpoint前缀的服务属于同一个集群,因此对于某些服务的扩容,新节点使用相同的Endpoint前缀即可。wiwo和uframework两个框架的客户端具备了解析ZooKeeper配置的能力,可以通过对Endpoint的解析获取到真实的IP和端口信息。然后通过客户端负载均衡的方式,将请求发送到真实的业务服务实例上去,从而完成服务间的相互调用。如下图所示:
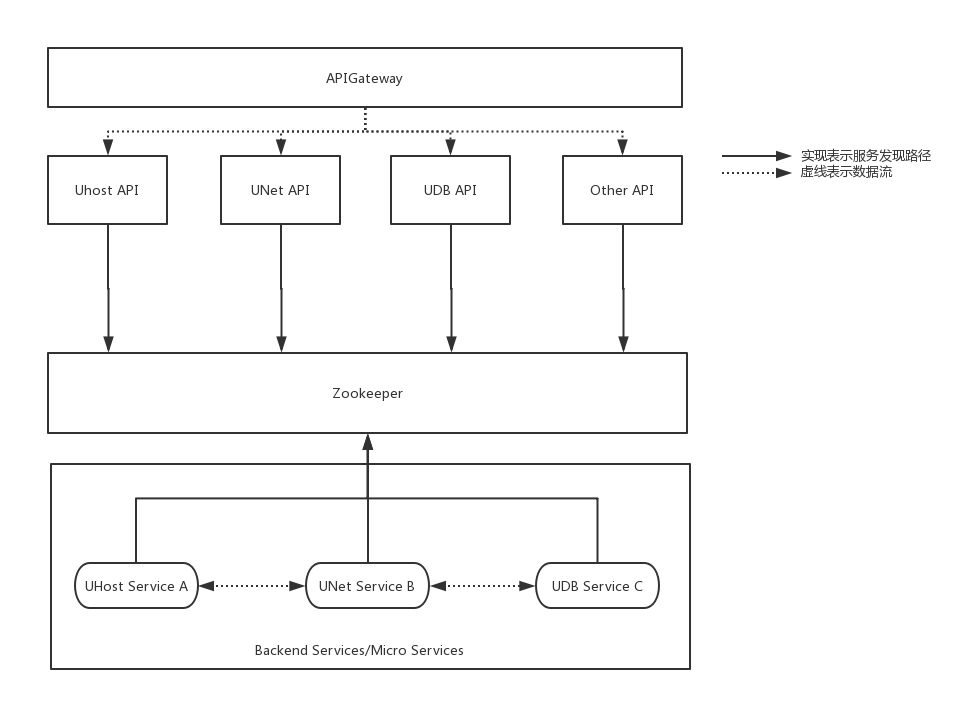
图2:UCloud 首尔机房部署调用及服务注册/发现路径图
首尔老机房的ZooKeeper集群是一个具有3个节点的普通集群(当时规模相对较小,3个节点足够)。 然而首尔新机房的规模要大很多,因此新机房ZooKeeper的集群规模也要扩充,经过我们的评估,将新机房的ZooKeeper集群扩充到5个节点,基本上可以满足所需。
其实,一个理想的迁移架构应该是如图3所示,整个新机房使用和老机房相同的技术架构(架构和版本统一),新架构完全独立部署,与老机房并没有数据交互工作,而用户的业务服务(如UHost/UDB/EIP/VPC等)通过某种方式平滑的实现控制和管理面的迁移,以及物理位置的迁移工作。
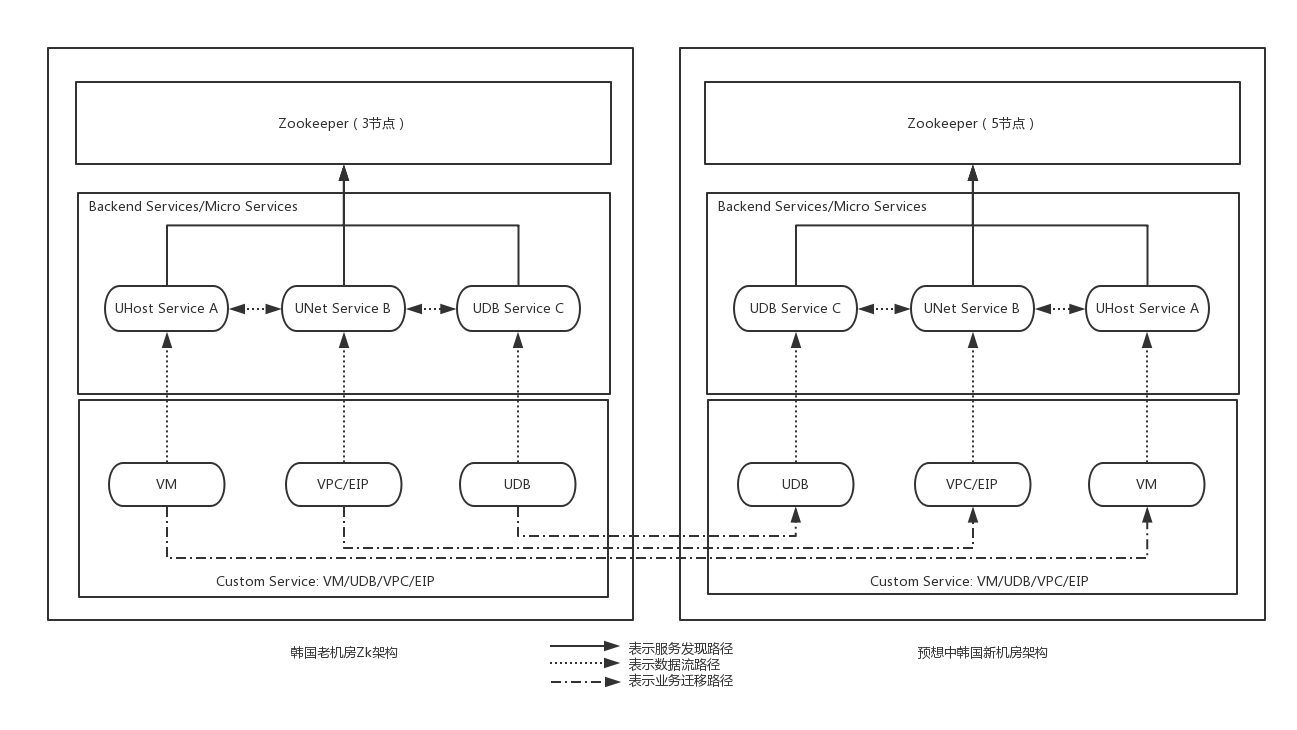
图3:理想状态下的老旧机房服务迁移示意图
但是理想状态在现实中无法达到,内部架构和代码逻辑的限制,导致业务实例无法平滑实现逻辑和控制层面的迁移,更何况物理层面的迁移。新部署的管理服务需要和老机房的管理服务进行通信,因此,我们调整了新机房服务的部署架构,并适配实际情况分别使用两种部署模式,如图4和图5所示:
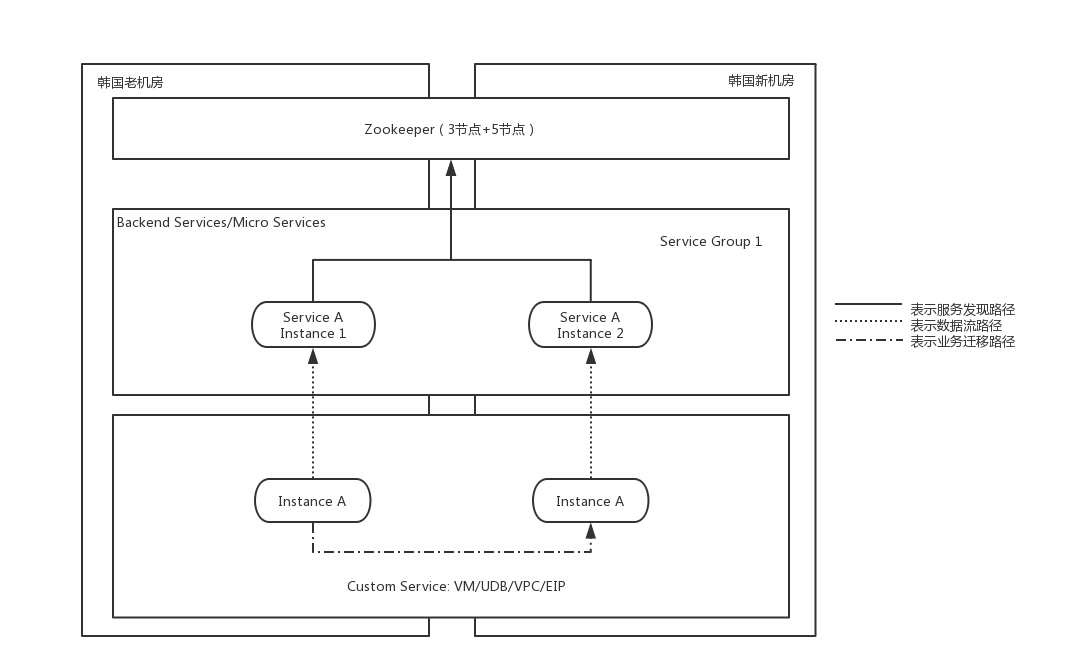
图4: 同集群扩容模式的跨机房服务部署
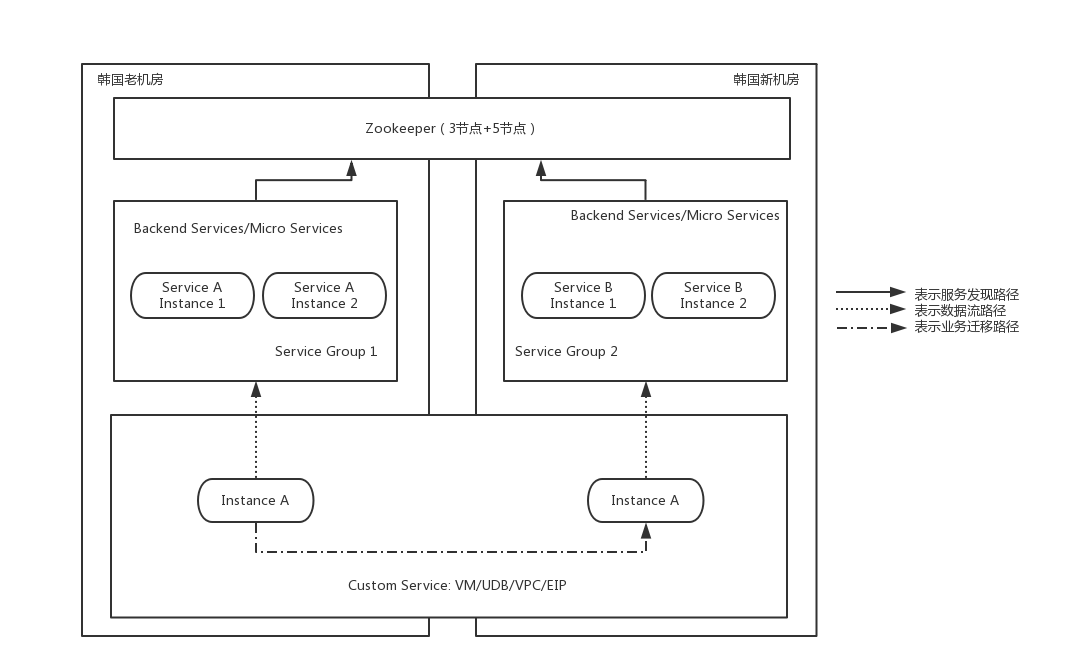
图5: 新建集群灰度迁移模式的跨机房服务部署
无论是图4的同集群扩容模式,还是图5的新建集群灰度迁移模式,在ZooKeeper层面必须让新旧机房的ZooKeeper集群处于一体的状态,需要两个集群的数据一致、实时同步。因此在ZooKeeper的技术层面,必须将这两个集群变成一个集群,将原有的3节点的ZooKeeper集群,经过异地机房扩容的方式扩充到8个节点(1个leader,7个follower),只有这种模式下数据才能够保持一致性和实时性。
而对于新机房新部署的需要注册的服务来说,他们的配置文件中对于ZooKeeper地址的配置,却不是新建的8个IP的列表,而是只配置新机房5个IP的列表。这样新老机房的后端服务使用同一套ZooKeeper,但是配置的却是不同的IP,这样做的目的,是为了后续老机房下线裁撤时,所有新机房的服务不需要因为ZooKeeper集群的缩容而重启更新配置,只要将集群中老机房所在的3个节点下线,剩余5个节点的配置更新重新选主即可。
因此在ZooKeeper的机房扩容方案上,我们采用了先同集群扩容后拆分的模式。ZooKeeper的扩容是整个机房扩建的第一步,后续所有的服务都会依托于该操作新建的5个节点的ZooKeeper配置;而ZooKeeper集群的缩容是最后的操作,待所有的服务都扩容完成,所有业务实例迁移完成之后,将ZooKeeper集群进行缩容重新选主,这样即可完成整个机房的裁撤。
数据库中间层udatabase的迁移
接下来是数据库中间层udatabase的迁移工作。
图4和图5两种模式对于ZooKeeper的处理方式是相同的,不同点在于后端对于内部管理和控制面服务的扩容迁移方式。udatabase迁移使用图4模式,这种模式下相当于在原有的集群进行异地机房扩容,扩容的新实例使用和原有集群相同的Endpoint前缀,也就是说它们是属于同一个集群,当服务启动后,新扩容的实例的状态会与原有集群的实例相同,框架(wiwo或uframework)层会通过客户端方式从ZooKeeper中发现到该集群节点的变化(新增),同时使用某种负载均衡算法将请求流量路由到新的节点上。这样属于同一个集群,但却处于两个地址位置的实例都有部分流量,而进行缩容的方式就是直接将老机房同集群的服务下线即可,这样客户端就会将所有该集群的流量都转发到新机房扩容的节点上,从而完成平滑的服务扩容。udatabase通过这样的方式完成了集群的迁移过程。
新建集群灰度迁移模式
其实图4模式对于大部分服务来说都是可行的,但为什么还出现了图5所示的新建集群灰度迁移模式呢?因为某些场景下图4会有一定的不可控性。假如新建的实例(如图4中Service A Instance 2)存在软件稳定性和可靠性的问题,比如配置异常、软件版本异常、网络异常,可能导致路由到新节点的请求出现问题,会直接影响在线业务,影响的规模由扩容的节点占集群总节点的比例决定,像我们这种1:1的扩容方式,如果服务有问题可能50%的请求就直接异常了。udatabase使用图4方案,是因为其代码的稳定性比较高,功能和配置比较简单,主要依托于其高性能的转发能力。
而对于某些功能逻辑都比较复杂的业务来说(如ULB/CNAT),就使用了更稳妥的图5模式,由于业务层面支持跨集群迁移,因此可以新建一个全新的无业务流量的集群,该集群在ZooKeeper中的Endpoint路径前缀和原有的集群不相同,使用一个全新的路径,然后在业务层面,通过迁移平台或工具,将后端服务或实例按需迁移,整个过程可控,出现问题立刻回滚,是最安全的迁移方案。我们通用的灰度迁移平台SRE-Migrate如图6所示。
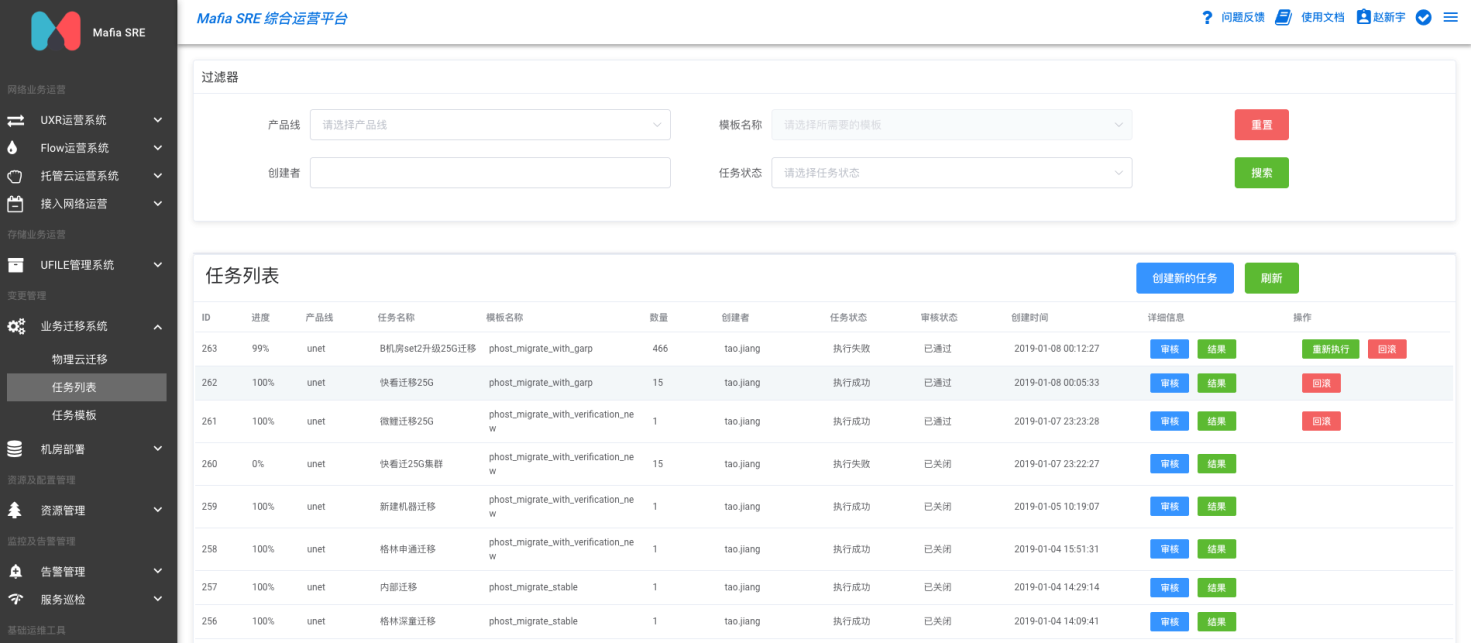
图6 UCloud内部通用业务迁移系统SRE-Migrate
机房部署平台SRE-Asteroid
UCloud产品线和产品名下服务数量繁多,无论是图4还是图5的方案,都需要大量的服务部署工作。SRE团队在2018年中推进的机房部署优化项目,意在解决UCloud新机房建设(国内及海外数据中心、专有云、私有云等)交付时间长和人力成本巨大的问题,2018年底该项目成功产品化落地,覆盖主机、网络等核心业务近百余服务的部署管理,解决了配置管理、部署规范、软件版本等一系列问题。首尔机房迁移也正是利用了这一成果,才能够在很短的时间内完成近百个新集群的部署或扩容工作,图7所示就是我们的新机房部署平台 SRE-Asteroid。
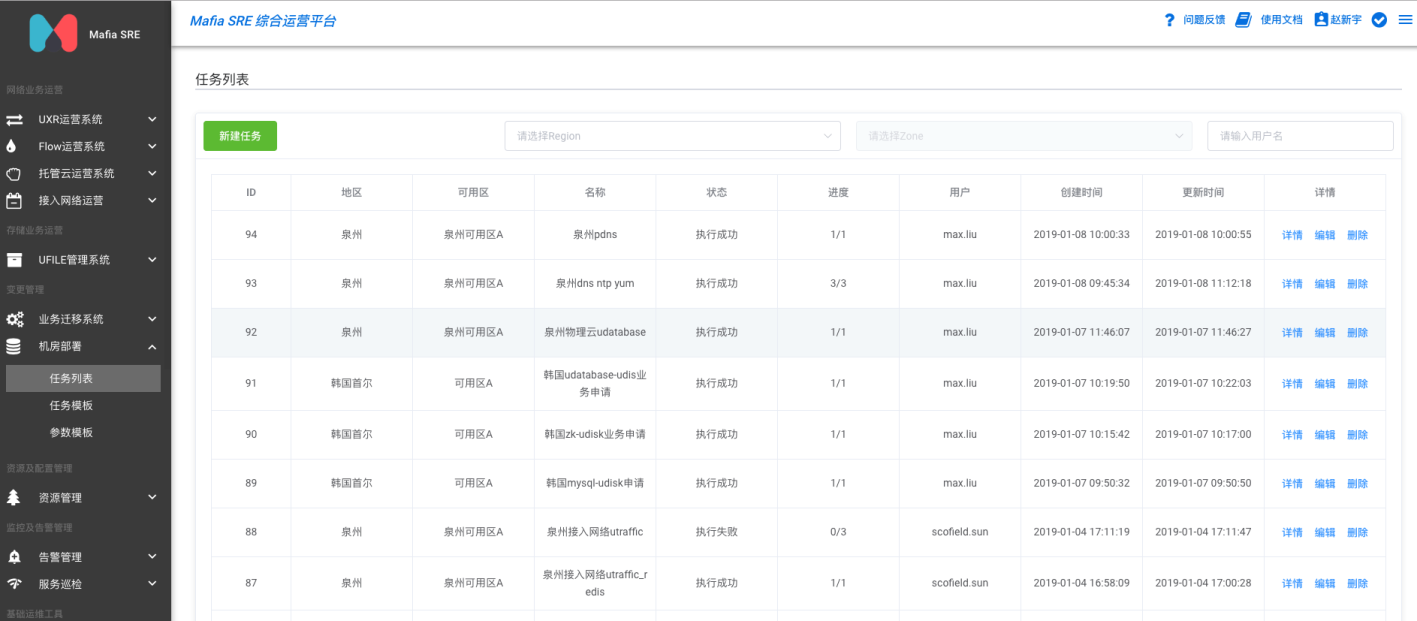
图7 UCloud内部机房部署平台SRE-Asteroid
核心数据库的部署和迁移
最后,是核心数据库层面的部署和迁移工作如何进行。UCloud内部服务所使用的数据库服务为MySQL, 内部MySQL集群采用物理机/虚拟机在管理网络内自行建设,以一个主库、一个高可用从库、两个只读从库和一个备份库的方式部署,使用MHA+VIP的方式解决主库的高可用问题,使用BGP/ECMP+VIP的方式解决从库的负载均衡和高可用问题,大体的架构如图8所示:
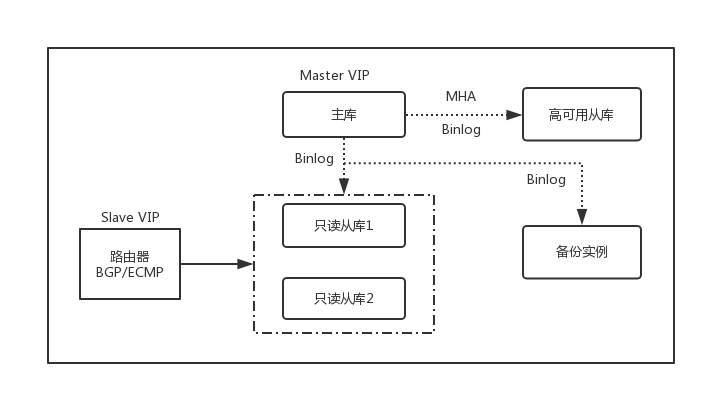
图8 UCloud内部MySQL服务架构图
首尔新老机房使用的内部MySQL数据库集群的架构跟上图类似,为了进行新老机房的集群切换,我们设计了如下的方案,如图9所示:
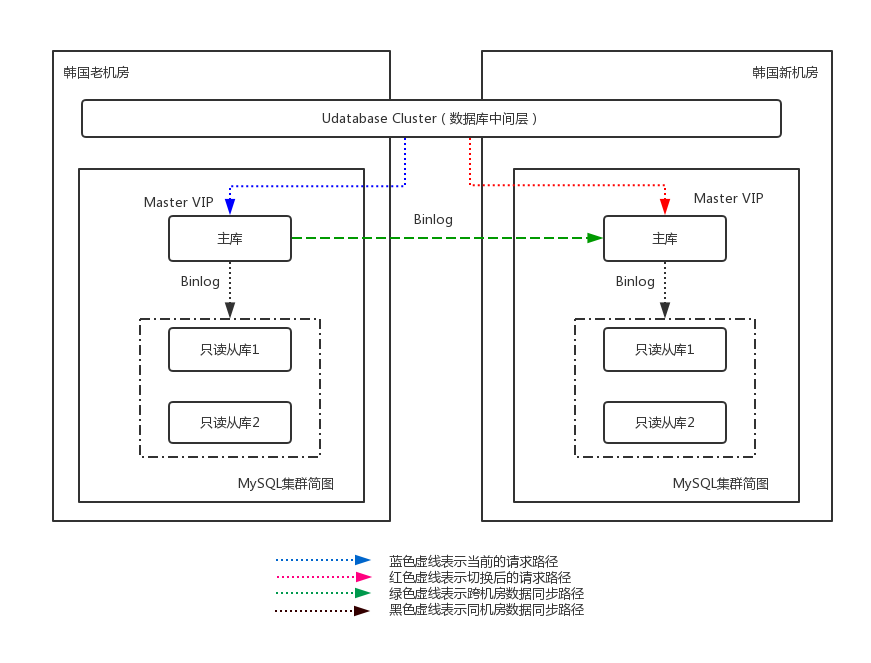
图9 首尔集群内部数据库集群迁移示意图
整体来说,为了保证核心数据库集群能够稳定完成迁移工作,我们抛弃了双主库、双写的切换方案,防止因为网络或其他因素导致新老集群的数据不一致、同步异常等问题。我们采用了最简单的解决方案,在业务低峰期停止Console服务,直接修改数据库中间层配置切换的方案。
在部署阶段,我们在首尔新机房部署了相同高可用架构的MySQL集群,老机房的数据库逻辑备份导入,将新老机房的集群做成级联模式(图9中绿色虚线),新机房的主库作为老机房的从库,通过MySQL异步同步的方式(binlog)进行数据同步。我们使用pt-table-checksum工具,定期对两个集群的数据一致性进行校验,以保证新老机房的数据完全一致。与此同时使用内部开发的拓扑分析工具,将所有调用老集群数据库主从库的业务情况确认清楚(主要是哪些udatabase集群)。
部署完成后,数据一致性和实时性通过级联得到保障,udatabase仍然访问老机房的MySQL主库的VIP(图9蓝色虚线),此时并没有业务通过直连的方式写入新机房的主库(为保证数据的一致性,新机房的主库暂时设置成只读模式)。
在确定迁移时间和迁移方案之后,在某个业务低峰期的时间点,公告用户后,首尔机房整个console的操作停止一段时间(期间首尔机房的API请求可能会失败),在确定流量很低的前提下,通过修改数据库中间层(udatabase cluster)中数据库主从库VIP的配置,将业务从老机房MySQL集群切换到新机房MySQL集群,此时该业务所有的请求都会流入到新集群(图9红色虚线)。为了防止老集群仍然有业务写入或读取,我们将老集群主库设置为只读,然后继续通过tcpdump抓包分析老集群上可能存在的请求并手动处理,最终保证所有业务都使用新的MySQL集群。
由于需要对主机、网络、存储和监控等几个业务都进行集群切换,为保证不互相影响,使用逐个集群处理的方式,整体切换加检测的时间耗时近1个小时。
在整个机房切换的过程中,只有数据库集群是有状态的业务,因此重要性和危险性也比较高,该服务切换完成后,最重要的一个环节也宣告完成,剩下的业务层面(UHost/UDB/EIP等)的迁移工作由各个业务团队自行完成即可。
收尾
最终所有业务实例完成迁移后,理论上就可以完成本次机房迁移工作了,不过还是要对老机房仍然运行的实例进行流量监测,确认没有流量后进行下线,停止服务。最后对老机房的ZooKeeper集群(老机房的3个ZooKeeper节点)进行请求监测和连接监测,确认没有本机房以及新机房发来的请求(排除ZooKeeper集群自主同步的情况),在完成确认后,进行最后的ZooKeeper集群变更,将整个集群(8个节点)拆分成老机房(3个节点)和新机房(5个节点),老机房的集群直接停止服务,而新机房的新的ZooKeeper集群完成新的选主操作,确认同步正常和服务正常。
写在最后
经历了上文所述的一切操作后,整个首尔机房的迁移工作就完成了,整个项目历经5个月,其中大部分时间用于业务实例的迁移过程,主要是针对不同的用户要确定不同的迁移策略和迁移时间;内部管理服务的迁移和部署所花费的时间还是比较少的。UCloud内部针对本次迁移的每一个步骤都制定了详细的方案规划,包括服务依赖分析、操作步骤、验证方式、切换风险、回滚方案等,为了完成如此巨大的新机房热迁移工作,团队投入了充足的人力和时间。首尔新机房具有更好的建设规划、硬件配置和软件架构,能够为用户提供更好的服务,我们相信这一切都是很有价值的。