
近期IBM称,通过采用基于相变存储的模拟芯片,机器学习可以加速一千倍。相变存储(PCM)是基于硫属化物玻璃材料,能在施加合适电流时将介质从晶态变为非晶态并再变回晶态,基于材料所表现出来的导电性差异来存储数据。PCM设备是非易失性的,访问延迟达到DRAM级别,是存储级内存一个很好的范例。
IBM博客透露,其正在建立一个研发中心,以开发新一代人工智能硬件并研究纳米技术。技术合作伙伴包括纽约Staye,纽约州立大学理工学院,三星,Mellanox和Synopsis。
新型处理硬件
IBM研究院半导体和人工智能硬件副总裁,Mukesh Khare表示,目前的机器学习限制可以通过使用新的处理硬件来克服,例如;
- 数字化AI核心和近似计算
- 带模拟内核的内存计算
- 采用优化材料的模拟核心
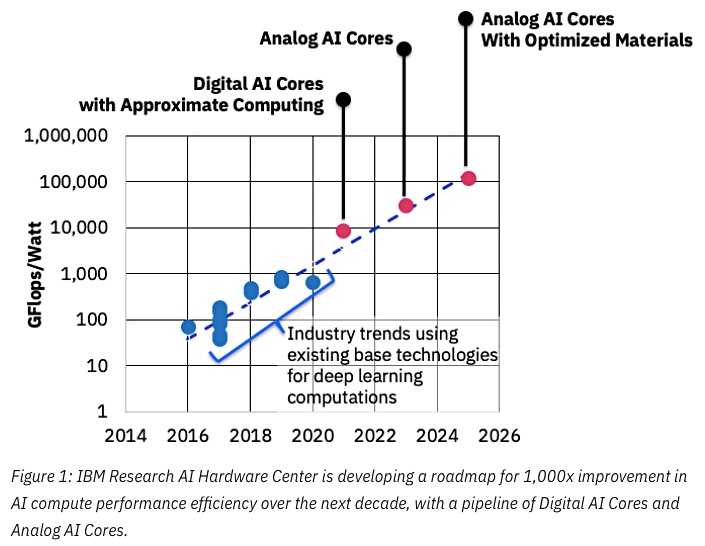
他提到将深度神经网络(DNN)映射到模拟交叉点阵列(模拟AI核心)。它们在阵列交叉点处拥有非易失性存储材料来存储权重。
为了提高训练过程中决策的准确性,DNN计算中的数值进行了加权。
这些因素无需主机服务器CPU干预,就可以直接用交叉点PCM阵列实现,从而提供内存计算,无需数据移动。相比英特尔XPoint SSD或DIMM等,这是一个模拟阵列。
PCM单元沿着非晶态和晶态之间的8步梯度记录突触权重。每个步骤的电导或电阻可以用电脉冲改变。这8个步骤在DNN计算中提供了8位精度。
非易失性存储的交叉阵列可以通过在数据位置处执行计算来加速完全连接的神经网络训练。

模拟存储器芯片内部的计算
IBM的研究论文指出:“模拟非易失性存储器(NVM)可以有效地加速”反向传播“算法,这是许多最新AI技术进步的核心。这些存储器允许使用的“累积乘法”运算,在模拟域中权重数据的位置上,用基础物理学进行并行化。
我们只需将一个小电流通过一个电阻器连接到一根电线上,然后将许多这样的电线连接在一起,让电流积聚起来。这样我们不需要一个接一个地执行计算,而是可以同时执行许多计算。并且相比在数字存储芯片和处理芯片之间花时间传输数据,我们可以在模拟存储芯片内执行所有计算。”
PS:昨天对单身狗来说不是情人节,而是IBM从Computing Tabulating Recording计算列表纪录公司改名为国际商业机器公司International Business Machines的日子——1924年2月14日。





