
云计算环境中,高可用(HA)是IaaS层必备的特性,在云环境中,失效状态是云管理系统必须解决的问题,研究并增强高可用性无疑是一个很有价值并且具有挑战性的工作。
可用性是指系统在执行任务的任意时刻能正常工作的概率,提高可用性需要强调减少从灾难中恢复的时间。从某种意义而言,提高可用性就是一场与时间的赛跑,从故障中恢复的耗时越短,价值就越大。
浪潮InCloud OpenStack(以下简称ICOS)从产品设计之初,就将HA作为第一优先级的需求。目前,OpenStack开源社区并没有一个完整的云业务HA解决方案。起初社区认为虚拟机的HA不是云平台层次的特性,虚拟机的HA应该通过应用层面而不是在云平台层面来实现。但是在实际部署中,有相当数量的应用并不具有应用层面的HA,OpenStack在HA特性上的缺失带来了业务中断的风险。随后社区也提出过计算节点HA解决方案,例如在管理程序或其底层硬件出现故障时,虚拟机在不同的计算节点上自动重启等,但方案仍然是相对不成熟的、实验性的,并没有应用到生产环境上来。而比较受关注的Masakari项目也由于未考虑虚拟机脑裂和计算节点的隔离,缺乏成熟的应用场景。
从度量可用性“三维”入手
如何提升OpenStack的HA特性,从而消除用户的使用障碍,使更多的用户从开源云计算中受益?浪潮基于对行业客户上云的深刻理解和丰富的实践经验,认为应该先从度量虚拟机、关键进程和物理机的可用性“三维”入手,有的放矢的采取多种维度的故障检测与应对策略,解决云环境特别是大规模云环境的可用性问题,从而实现高可用的云环境。
业务虚拟机宕机:组件服务程序的运行时异常,如系统资源不足或者hypervisor层的系统bug都有可能引起业务虚拟机宕机的发生,导致对外服务的中断,影响用户正常业务开展。
计算节点上的关键服务意外退出:业务虚拟机的健康运行离不开计算主机上必要的虚拟网络设施以及后端分布式存储。负责维护这些资源的关键服务如果发生异常退出,将会引起业务虚拟机死机或网络中断,从而导致服务的不可用。
计算节点宕机:在发生主机掉电或者硬件故障时,如果没有精准的宕机感知机制来获取意外的发生,且没有自动修复机制,将导致运行在其上的虚拟机全部宕机,最终导致虚拟机上运行的大量应用服务不可用,直接导致业务中断,会给企业带来无法估量的损失。
ICOS集群HA管理服务实现全方位高可用
面对云环境中如此复杂多样的引发业务主机“服务不可用”的元凶,ICOS提供了集群HA管理服务。目前,高可用性实现模式主要有三种,分别是主从模式、双机模式和集群模式。通常来说,云计算的计算资源和存储资源是以集群形式实现的,特别强调可扩展性。从理论上而言,集群模式是最优的选择,这种模式可以在保证高可用的同时,利用多机分担负载,确保整个IT基础设施具有更高的扩展性。
浪潮ICOS从业务高可用、关键进程高可用、主机高可用三个方面入手,为客户业务提供真正的高可用保障。
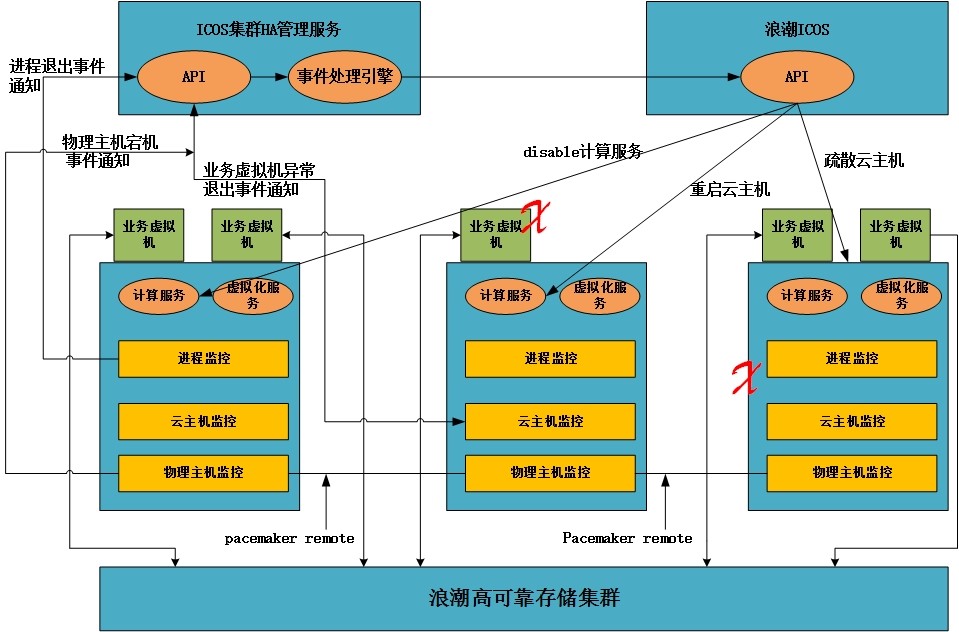
ICOS 高可用计算架构
业务层高可用:确保业务高可用的关键在于能敏锐感知Hypervisor虚拟化层面异常事件并及时采取合适的保护动作。ICOS的集群HA管理服务方案在计算主机配置云主机监控服务,轮询底层虚拟化接口,关注虚拟机异常事件,例如“异常退出”。当事件发生时,云主机监控服务封装并发送“云主机异常退出通知”到集群HA管理服务,由异常事件处理引擎甄别事件,并发送“云主机重启”请求到ICOS计算服务接口,完成对问题业务的恢复。
关键进程高可用:如果要确保业务云主机的健康运行,仅仅从Hypervisor层关注虚拟机是否宕机显然是不够的,因为在复杂的云环境下,业务的健康不仅取决于其挂载的后端分布式存储是否可用,业务网络是否畅通,还在于云环境中能否被良好地治理等诸多因素。在计算集群中,负责维护这些因素良好状态的进程就是我们所关注的“关键进程”。ICOS的集群HA管理服务方案提供了一套高度可配置化,自由定制化架构以实现对计算主机进程的监控:监控进程列表可配置,监控脚本以及异常处理Action可以自定义,支持基于Action列表的工作流定制化。
系统默认提供“尝试重新启动失败进程”的处理方式,一旦目标进程发生异常,可以在数秒内检测到并恢复服务以解决问题,如果多次尝试无果,即自动发送“进程不可用”事件到集群HA管理服务,由其通知云平台Disable本节点计算服务,使该计算主机不在为新建虚拟机提供计算资源,但并不妨碍既有业务运行,这时配合外部的集群监控系统告知运维人员,使其进行系统修复,并可以将该修复方法定义为新的Action以实现系统的进化。
主机高可用:各个计算主机上的主机监控进程集成了业界成熟开源的高可用心跳检测工具Pacemaker Remote,不仅可以提供高效率的运行状态探测,而且突破了Pacemaker集群最多16节点的限制,极大地扩展了计算集群大规模弹性的上限。主机监控进程借助该工具感知集群Peer节点的运行状态,一旦发生物理主机宕机,那么就会由心跳集群主控节点的主机监控进程产生“宕机事件通知”,并告知集群HA管理服务,并经后者的事件处理引擎甄别,触发ICOS计算服务的“云主机疏散”,将故障主机上的业务迁移到集群其他可用计算节点,从发现宕机到虚拟机重启并且能够正常运行,整体时间可以控制在1分钟左右。此外,ICOS还可以基于可配置策略对物理主机进行诸如重启或者关机的相应处理策略,从而防止业务虚拟机出现脑裂现象。当主机故障清除后,主机健康运行后,还可以根据配置策略决定是否自动加入高可用监控集群中,使得高可用的配置策略更加简单化、人性化。
借助于浪潮自研的高可靠分布式存储以及ICOS全方位的集群高可用管理服务,在主机硬件故障,机房断电等不可抗因素引发宕机的场景下,ICOS确保业务连续性,有效降低宕机时间。







