
在2019英特尔以数据为中心的创新产品发布会上,上海交大网络信息中心计算部主任林新华介绍了构建上海交大“π 2.0”超算系统时,选用了英特尔第二代至强可扩展处理器。

英特尔与上海交大的合作可以追溯到2013年,2013年上海交大建设的“π1.0”超算中心,当时这一超算中心的计算能力在国内高校中排在第一位,性能够好,够稳定,但五年之后,这些资源明显已经不够用了。2018年,在上海交大校领导的支持下,林新华所在的网络信息中心计算部开始建设二期项目。
高校超算发展简史
林新华是非常资深的专家,对超算在中国,尤其对高校超算的发展历史非常熟悉。他记得,在他上学的时候,高校机房里的高性能计算机都是小型机,大都来自IBM、SGI这样的厂商。这一局面在2010年前后开始有很大改观,业内开始用英特尔的x86架构CPU构建集群,国内高校也都纷纷效仿。
基于x86架构的超算降低了成本带来了很高的开放性和灵活性,超算行业也步入发展快车道,而在学校,由于各个院系都在构建超算集群,超算的资源利用率开始成为新的问题,需要有专业的技术团队去维护超算中心,学校的领导也意识到必须有专门的队伍去维护超算设施,让专业的人做专业的事儿,使用者可以把精力放在自己本身的业务上。
超算资源是战略资源,很多科研工作都需要超算,在学校,用超算的人也越来越多了,林新华介绍说,很多现在的学科都需要做一些计算,传统的数值模拟仿真是一类,新兴的AI计算用的也越来越多,现在开始流行用AI的方式来做材料科学研究,一批新的计算负载开始出现。于是,上海交大的π集群就不够用了。
二期项目在技术方面得到了英特尔的大力支持,与英特尔技术团队的多次沟通后,最终决定选择当时还未发布的Cascade Lake处理器。林新华表示,之所以选择这款处理器,除了看中性能以外,还特别看中新处理器能支持智能应用程序这点。
上海交大“π2.0”超算系统

在上海交大构建的“π2.0”超算系统中,计算存储和网络三部分都有创新,三大创新都有英特尔的身影。
在计算方面,π2.0系统采用了第二代至强可扩展处理器,采用了658台双路节点,1316颗第二代至强金牌6248处理器,双精度浮点理论性能能达到2.1PFlops。在应用负载方面,新一代的处理器既支持传统HPC负载又面向AI负载进行优化。
在高速互连方面,π2.0采用了英特尔Omni-Path架构,可以帮助MPI应用平滑升级,无需更改代码就能将应用迁移到新的架构。基于Omni-Path架构的交换机芯片支持48端口,单交换机支持最多1152个端口。
在存储方面,π2.0还构建了中国高校第一台全闪存NVMe Lustre存储系统,这一系统基于开源分布式架构,集合了英特尔两种创新硬件方案,DC P4610 NVMe SSD和OPA卡,分布式存储系统Lustre是支持HPC仿真环境的并行文件系统。
一体化的方案,性能大幅提升
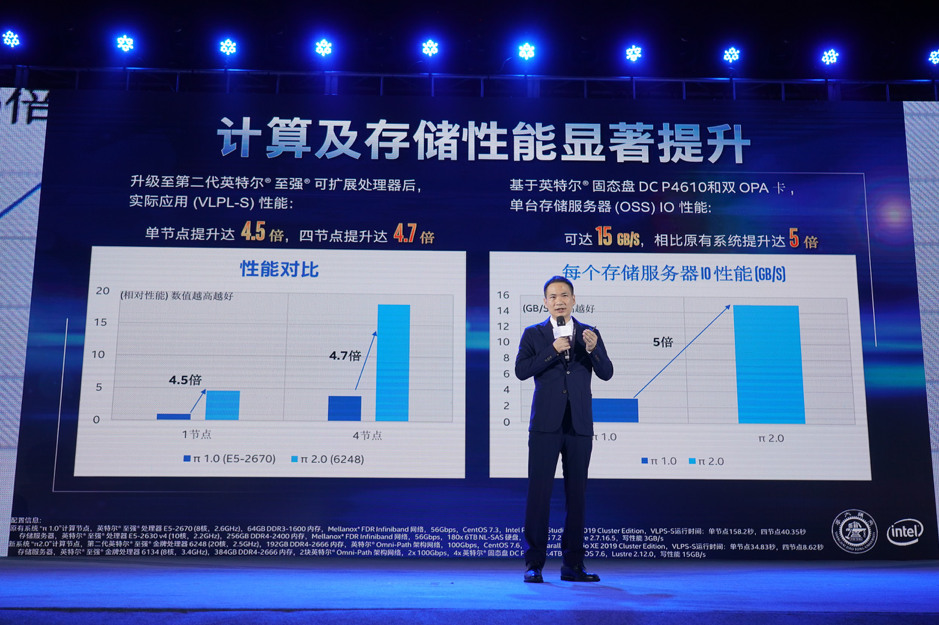
π2.0超算系统较为全面的采用了英特尔一体化的HPC解决方案,整体性能都达到了很好的效果,计算和存储性能显著提升。林新华介绍说,与π1.0相比,π2.0在单节点的计算能力提升了4.5倍,四节点的性能提升了4.7倍。存储方面,传输速度能达到每秒15GB/s,相比原有系统性能提升了五倍。
系统升级的苦很多人都有体会,PC的Windows升级,手里的安卓IOS设备升级,多少都会有点问题,有部分APP都不支持新系统。
而在上海交大的这次更新中,令林新华感到意外的是,系统升级迁移程序的时候,完全无需修改代码,直接拿源代码即可运行。从一个平台搬到另外一个平台通常都需要去改源代码,这对学校的老师有非常大的困扰,就像搬家一样麻烦,如果说可以拎包入住,原来有的东西这里都有,这该有多大的吸引力?
从上海交大此次升级π2.0系统的实践中,我们看到高校对于超算中心的重视,在技术实践上,中国高校在基础设施方面走在了世界前沿。林新华介绍说,国内高校在高性能计算方面有很大投入,许多知名高校都有非常好的计算平台支持,而且这些计算平台哪怕放到美国、日本、欧洲国家相比也都不算差。







