2019年7月23日,阿里巴巴资深技术专家吴忠杰在于西安举办的2019存储与数据峰会上发表了题为《针对云计算的统一存储引擎》的主题演讲,以下内容根据现场速记整理:

大家下午好,今天非常有幸和大家分享面向数据中心的分布式存储系统相关的一些进展,这次我的题目是与性能相关,围绕数据中心的存储,今天就讲一个话题,就是性能。
讲这个话题之前,首先讲一个背景,我们阿里云整个系统有一个天基的操作系统,这样一个操作系统里面有很多模块,做云计算设计的时候,不是针对每个业务场景做系统设计,而是面向很多业务,整个计算平台是层次化、结构非常清晰的。盘古(Pangu),我们叫做分布式的存储系统,盘古之上还有很多的存储业务,这种存储业务可以在阿里云的官网上看到,比如很多人谈到的块存储,文件存储和对象存储,还有我们今年刚刚推出的面向大数据计算的一个接口,就是技术兼容的接口,但是这些系统都离不开盘古,都在盘古里面。
盘古这个系统经过了超过十年,今年是第十一年的技术演进,2008年开始,阿里云刚刚成立的那一刻,第一行代码就是盘古代码。2008年盘古开始写下第一行代码,到2009年的时候发布了盘古1.0,那个时候存储主要介质是磁盘,这个磁盘存储基础上,如何去构建分布式存储,是那个时候非常重要的一个话题。所以在2009年盘古1.0推出之后,实际那个时候云计算没有什么,应用非常少,那个时候应用主要是邮件系统,搜索为主,当时出现盘古1.0就是邮件系统和搜索相关的应用。
蚂蚁金服刚刚创建的时候也是采用盘古1.0。到2013年的时候有非常重要的时间点,我们叫做5K,就是我们单台支持的推广达到了五千台,这个规模很大。
如果采用开源的系统你达不到五千台这样的规模量产,盘古当时规模达到了五千台,当时参加了国际上的一些测试,性能非常不错,排名靠前。2015年单台技术规模达到一万台,阿里云飞天园区,飞天也是从这个地方来的。
飞天园区里面有一个雕像,就是为了纪念2013年这个关键时间点。还有一个关键时间点就是2018年,发布了第二代系统,就是飞天系统2.0,其中有一个重要的子系统就是盘古2.0。因为2018年的时候,数据中心闪存是重要的方向,如果这个时代用盘古1.0支撑业务系统基本不可能,那个时候做盘古2.0,是2016、2017年开始,真正发布是2018年。为什么去年双十一达到两千多亿的数字,实际背后就是盘古2.0。
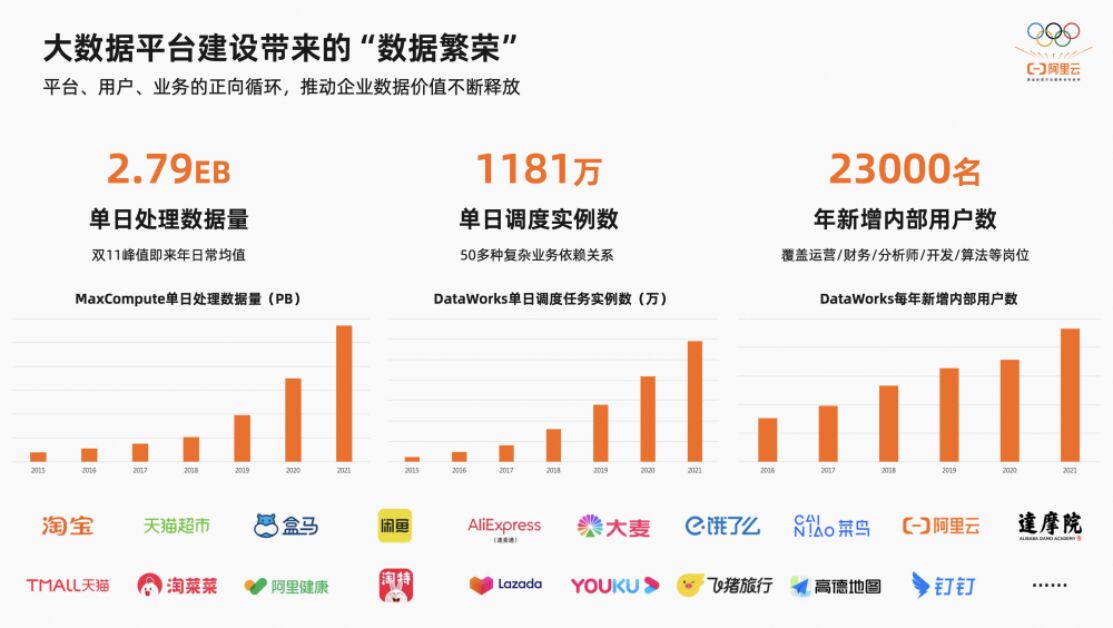
我们看一下整个行业,整个存储系统,这个实际上这几个阶段,我做存储到今天有13年了,整个阶段除了存储大型机接触比较少,其它几个阶段我都是经历过的,从最小系统,实际反映出来我们存储的系统,第一是硬件向软件引进,第二是整个存储系统慢慢变成云化,通用的硬件支撑存储,下一步存储系统如何发展呢?今天想跟大家重点分享的就是上面标出来的,云化之后到底面临那些挑战,我们具体要做那些事情呢?
我们看一下,数据中心,我们今天云计算的数据中心,云计算一共分成三大块,计算、存储、网络,这三大块都是采用虚拟化的方式,给用户提供资源,讲一讲容易,但是实际上构建这样的一个云计算平台所遇到的挑战,计算这一块不仅仅是我们通用的X86、CPU在计算,还有很多平台,并且计算虚拟化,今天不是传统的软件上提供这种计算资源的虚拟化,还有其它的很多硬件虚拟化相关的技术在这个里面做的,所以这一块也是阿里云非常重要的,也是中间往前演进。
网络虚拟化更不用提了,整个云计算离不开网络,如何构建一张虚拟的网络,并且相互之间是独立的虚拟的网络,采用资源的方式对外提供服务,所有离不开网络。
还有存储,存储肯定是软件定义,我想强调软件定义不是一定要在我们现有的硬件基础上,去做这种存储系统就是软件定义,就是规定非得在今天X86的平台上做存储软件,我们面对数据中心存储的时候,需要思考一个问题,因为应用场景发生变化,我们面对社群也发生变化,软件和硬件的边界发生了变化,我们未来通用硬件到底是什么?这个问题是需要回答的。我们要做的是在通用硬件的基础上,去做我们的软件定义存储,这样才能把整体的效能发挥到最大。
我们从整个系统,云计算系统或云存储系统的角度分解一下,我们今天看到的几个性能的平行点,第一个从虚拟机出来以后,我们今天在云计算里面看到的云上的计算结果,云上的计算,从第一个虚拟器出来之后,往往需要有一个前端的网络,通过前端的网络接入后端的存储,后端的存储有一个后端的网络进行互联。
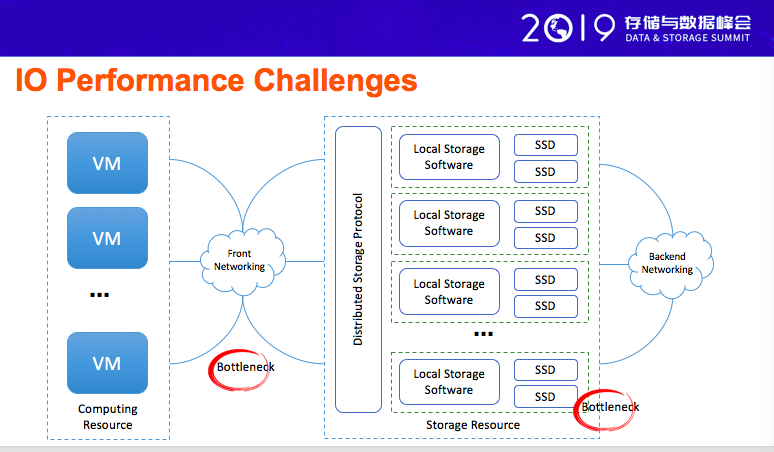
这整个环节里面是比较抽象的,整个环节里面,有几个重要的点,第一个就是我们前端的网络,如果前端的网络性能不行,我们整个计算到后端的时候,也就是说计算那个系统盘,或者计算资源里面那个数据盘,性能是没有办法得到突破的,因为没有办法突破,实际上在现在用户使用的时候,甚至还会用本地的盘,就是我在虚拟器里面插几个盘,做客户端的存储服务,这个是一个过渡的阶段,为什么呢?就是因为我们后端的存储能力,今天还不够,没有办法满足很多在极端场景下的性能需求,所以才会直接在虚拟器里面用物理盘的方式提供服务,这是一个过渡。很重要的原因我们前端网络有很多平行点。
第二个是后端的SSD,实际也是我们今天遇到的一个非常重要的一个平行点,我这有一些数据可以跟大家分享的,今天我们数据中心的网络,普遍的不大,最差的就是25G,我们实际上很多的网络环境就是单机是100G,出口的网络带宽是100G,单机100G谁是我们的性能平行点,CPU不是,网络也不是,而是SSD,是一个性能平衡点,为什么SSD做到百万级的IOPS,为什么还不是平行点呢。这个后面会讲。
我们回过头看,基于NAND比以前的子卡性能高很多,但是这个有条件,单纯从性能来讲,性能确实高不少,这些性能对比来讲,但是这些性能的对比,不是我们实际的应用场景,尤其不是我们云上的实际的运用场景,而是单纯的物理硬件的测试结果,这个测试结果,实际对我们实际的云上的系统设置没有参考价值的。唯一有参照价值就是随机的东西,这个东西有一些参照价值,其它的参照价值基本没有的。因为云上的那个特别是公共云上面的业务,你不知道它的开口是什么。
所以今天上午很多报告提到双十一的事件,双十一的流量,但是我今天跟大家说,双十一对阿里巴巴来讲这个流量不大,特别对于我们盘古来讲,这个流量太小,今天真正的压力在公共云上面,公共云上面那些流量压力,才是我们造成很多故障的主要的原因。
所以我们压力不是来自双十一,双十一是狂欢节。所以它的很多流量,电商的流量相对公共云还是非常小的。我想通过这个对比说,公共云的流量和业务的匹配性才是我们存储系统设置的最重要的挑战。
刚才讲到那个SSD的性能,看起来很好,但是它也是有很多问题的,这里面实际讲了一个问题,首先CPU上的问题,如果单纯用我们传统意义上的X86 CPU跑那个SSD性能,看怎么跑,如果采用内核的方式做,肯定是不够的,作用发挥不出来,无论怎么优化,无论采用传统的任何手段,都已经不行了。
所以这个地方,实际上就是一个很重要的趋势就是用盘古上,今天分布式存储系统,线上所有的都是用盘古的软件,一下把SSD的性能发挥出来,这两张图不一样,大家可以看一下。为什么会是这样呢?我们SSD下一步如何演进呢,如果单纯这个性能来讲,我们SSD演进方向是性能越来越差。
这个实际是我们整个盘古2.0里面我们实际上前两年做的非常重要的工作,把整个分布式存储,特别单机运行,针对高性能存储的引擎,全部替换。功能很强,盘古1.0都是基于内核构建,今天整个软件都是基于用户端做的,这个地方不仅仅是驱动,而是一套系统。当你把CPU管理起来,内存管理起来,文件系统管理起来,驱动硬件管理起来,自然而然,就是一个用户的操作系统。用了这个我们整体的效果还是非常不错,这是我们今天在线上进行大规模部署的原因。
下一步要进一步思考一个问题,我们SSD的性能,可以把CPU解放出来,可以把SSD的性能,从一定程度提高到一定程度,这个一定程度是什么,如何我们要评价一个SSD性能就是看随机性带宽,对于我们今天最好的SSD来讲,带宽在400到500兆B这样一个量级。通过用户带宽也是在这个级别,我们要将这个性能提升到1个G到2个G的性能,这是我们下一步要重点考虑的。

具体看一下SSD内部的结构,这个实际是一个普适的SSD内部的结构图,上面是软件,下面是硬件,软件的角度来讲,分成两大部分。一个是DATA LAYOUT,这个也是我们正在做的工作,并且有了很多成果出来。下面是NAND FLASH,这个有不同场合,本身介质发展非常快。这里面有一个标准ZNS,这个标准也是我们参与的标准,这个标准也是英特尔等厂商,包括阿里巴巴在内一块联合推的标准,这个标准实际上是说就是我们下一步存储软件栈和SSD如何深层次融合。
这个标准它的答案是什么呢,就是我们要打破原有的接口,需要提供类似于KV,但是不是KV的。这里面有几个概念,FULL有一定的生命周期,这个标准现在正在制订中。
如果采用这个ZNS对我们存储系统来讲,最大的价值是什么,这里面对打的价值就是QOS,提升SSD盘的能力,只有把SSD的盘的能力提上去之后才有空间更好的做QOS,如果我做QOS实际我会投入更多钱。要把QOS做好,首先第一步需要把SSD的能力或者说我们需要把硬件的能力进一步发挥出来。
接下来看一下网络,分布式存储的场景,尤其面向数据中心的存储场景,这个网络是非常重要的话题,今天的网络我们可以看到实际在100G,但是受限,正常的硬件可以达到200G。这个网络要分成两方面看,第一个就是物理网络的速度,第二个是上面该运行什么样的协议,这个是非常重要的事情。通常来讲,我们在整个行业里面,我们今天已经在线上或者说在业务里面,已经部署了。这些协议是我们今天已经得到规模化的部署的。
这个是简单的RDMA系统,大家可以看一下。这里要讲一下,我们那个RoCE RDMA,系统达到一定程度以后,链路不允许通行了。这个也是规模化运用非常重要的障碍。

这张图就是我们RoCE RDMA的技术站,我们今年实际上阿里巴巴的网络团队在一个业界的学术会议发表了两篇论文,是阿里巴巴网络团队做的,这个应该说也是阿里巴巴的首次,第一次在这样一个平台上做了两篇,这个峰会今年8月份在北京召开,这个会议上去讲下一代高性能的网络协议,这个协议对外叫HPCC,就是这个东西,通过这个协议站点的优化,我们整体数据中心这个高性能网络站就可以服务今天云存储、云计算相关的应用场景。
讲了这么多,我做一个总结,性能是云存储里面临的非常重要的问题,针对这样的问题,我们需要思考几个点,第一个是怎么样把硬件的潜能充分发挥出来,不是硬件今天做这样就是这样,需要改变。需要面对特殊的应用场景重新定义,重新定义以后再次变成一个面向数据中心的通用的。
第二个云存储云计算的场景里面,如何做更好的隔离等很多问题。第三点怎么保证做很好的IOPS,从QoS的角度考虑。这几个点都需要考虑,思考这三个问题。
第二个点从SSD的角度,下一步如何去引进。这里面有一个标准,不一定是未来数据中心的标准。第三点就是我们的网络如何发展,物理网络、网络的协议站如何发展。这样才能把问题解决掉以后打造一个高性能,面向数据中心场景的完美的系统。
这是我今天的报告,谢谢大家。