近日,UCloud UHadoop 通过提供独立的HDFS存储集群、独立的Hive元数据管理和独立的计算集群,实现了兼顾灵活性与稳定性的存储计算分离架构,帮助用户更好的提升资源利用率,增加大数据业务部署的灵活性,同时降低运营成本。
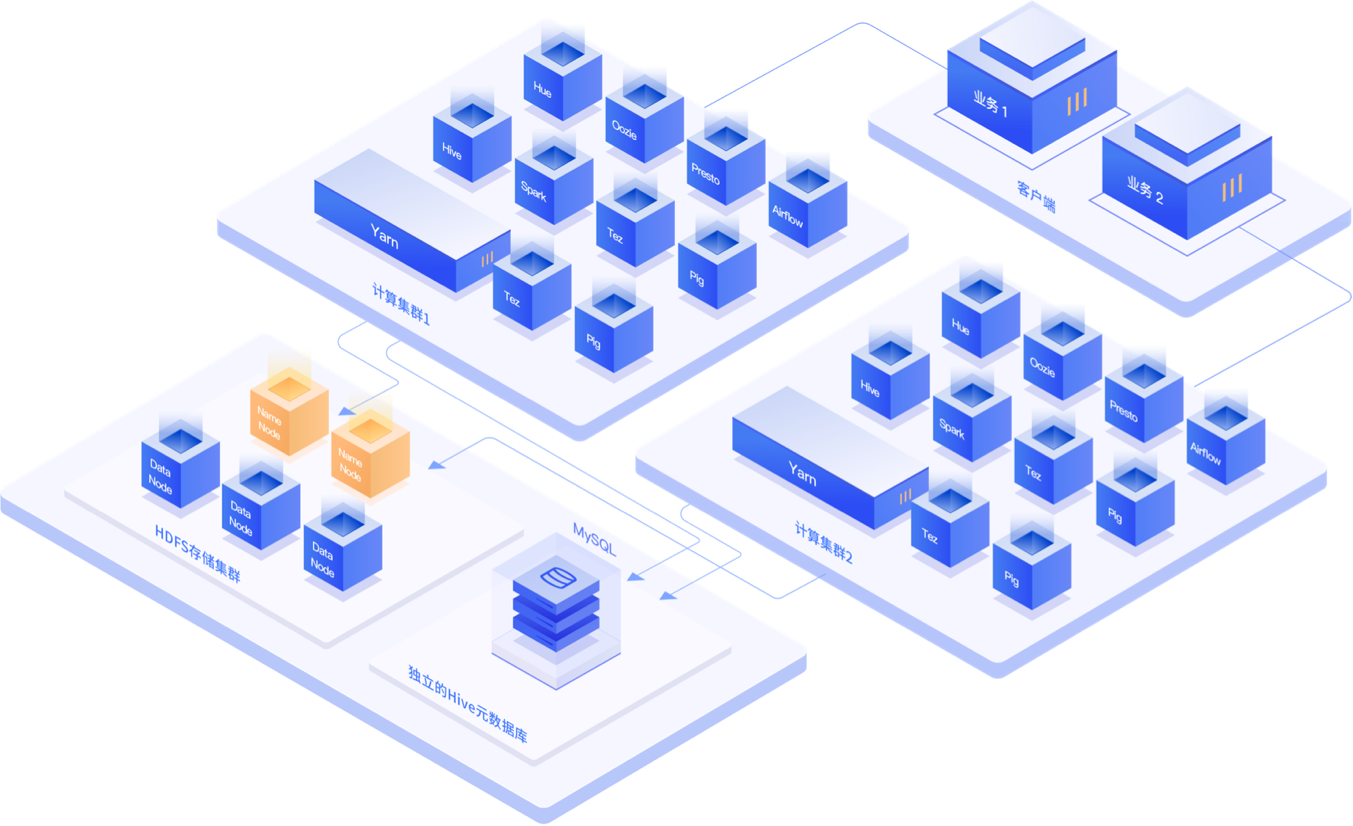
众所周知,为了让大规模分布式数据处理系统能发挥更好的性能,传统的Hadoop架构是将计算节点和数据节点连在一起的。但随着业务数据量爆发式增长以及企业对数据价值的不断重视,数据存储规模和数据计算需求经常是无法保持线性增长,计算和存储这两者之间随之产生了“木桶效应”,极易造成资源的浪费,而用户开始越来越关注数据存储成本及计算成本的问题。
这时,计算与存储资源的分离解耦,成为了一个非常合理的选择。UCloud UHadoop带来的计算与存储的分离,完全消除了计算与存储之间的“木桶效应”,在资源隔离、计算管理和存储管理三个方面具有极大优势,同时为业务创新、技术架构升级提供了更多的灵活性和可能性。
1. 不同业务计算资源的物理隔离,保障业务稳定
传统模式下,用户是通过配置资源队列,来为不同业务分配计算资源,但这种方式实际上只能做到逻辑隔离,无法真正实现计算资源的物理隔离,不可避免会发生计算集群抢占资源的情况,业务与业务之间相互影响,导致业务状态的不稳定。UCloud UHadoop 可以帮助用户将不同业务拆分到不同计算集群上,实现计算资源的物理隔离,避免资源抢占、相互影响,从而保障业务持续稳定。
如离线业务与实时业务的隔离业务场景,用户可以借助UCloud UHadoop将离线计算与实时计算 拆分成两个计算集群,然后访问独立的HDFS存储集群,有效隔离计算资源,保障业务的稳定。
2. 弹性管理计算资源,成本最优化
传统资源配置下,计算资源调度水平受限于单台机器的存储容量。UCloud UHadoop实现了存储与计算分离之后,用户可根据业务需要,单独增加计算节点,计算任务完成即可释放计算资源,无需担心临时的大规模扩容带来的成本飙升,更不用再进行跨集群数据拷贝操作,有效降低了管理集群的人力成本和服务器成本。
与此同时,若计算集群有故障或是计算集群框架升级,也不会直接影响独立的HDFS集群中的数据,更好的保障了数据安全,同时也可缩短故障排查流程,降低集群运维成本。
3. HDFS存储集群可单独使用,更好满足再分析需求
UCloud UHadoop提供独立的HDFS存储集群,用户可以单独使用存储资源构建存储集群,将历史数据或者原始数据压缩后进行归档存储,当有数据分析的需求时,不需要进行数据迁移,即可完成数据分析任务,使用简单、成本还低。
除了以上三个方面, UCloud UHadoop实现的存储计算彻底分离,还可以让多个不同版本Hadoop集群,分析底层同一份HDFS存储集群中的数据,满足了数据一致性要求,及历史原因导致的多版本Hadoop集群共存问题。为优化集群整体成本,UCloud UHadoop 更是针对存储计算分离场景推出了存储更大、价格更低的机型,可根据不同数据量规模选择不同节点机型,帮助用户更好的降低成本。