
为什么要把智能放在存储里面呢?
比如,以前交付一台10亿美元的存储系统,由于用户应用场景都不一样——像华尔街VS沃尔玛,对存储系统优化需求也不同;那么,把这样的存储系统送到用户现场,需要同时派驻工程师对参数和软件进行调配和优化,这个过程经常花费几个星期,甚至几个月时间。
这引发了我们的思考——怎么样能够更有效地针对不同客户的不同应用场景进行优化,这就是提出智能存储概念的原因。如果,存储系统能够现场进行机器学习,得到不同应用的数据模式,存储控制里面就可以做很多更友好的事情,例如:可以尽量减少垃圾回收,可以进行资源的合理分配、业务的优化调度、进程的统筹安排等等。换言之,如果能够预测数据访问模式,就会更好地对存储性能进行优化。
举一个垃圾回收性能及开销的简单例子,这里有两个闪存块(Block),每个Block里面有四个Pages,它们的生命周期不一样——其中,有两个周期比较短,另外两个生命周期相对比较长。因此,在做垃圾回收的时候,就要把有效数据页(Valid Page)迁移到新的Block中,这个过程就造成了“写放大”。这个问题处理不好,不但影响I/O性能,而且会额外增加很多不必要的操作,进而缩短闪存的寿命;如果能够合理配置、组合Block中的数据,使其生命周期接近,就会有效减少写放大——这就需要让人工智能和机器学习来发挥作用。
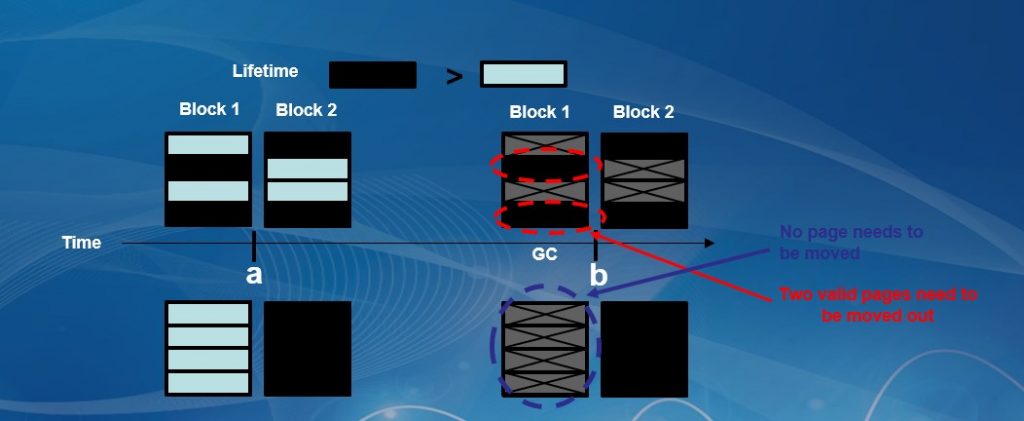
如图,这里黑色Pages相对蓝色的生命周期较长,如果不能根据生命周期对Block的数据进行组织,将会产生很多的Pages在空间垃圾回收时需要迁移(效果如图上方所示)。假设能够很好的组合这些Pages,使得在一个Block中的全部Pages生命周期变化最小化;当进行空间垃圾回收时,就不需要再搬移这些Pages(效果如图下方所示)。

这里,我们采用的基本方法是强化学习(Reinforcement Learning),通过学习I/O访问模式,来判断那些Pages应该放在一个Block里面。如果,我们发现组合不好,使得Pages之间生命周期变化过大;那么,我们通过反馈机制给判别模型以惩罚,最终使每一个Block里面的Pages的生命周期尽可能一致。
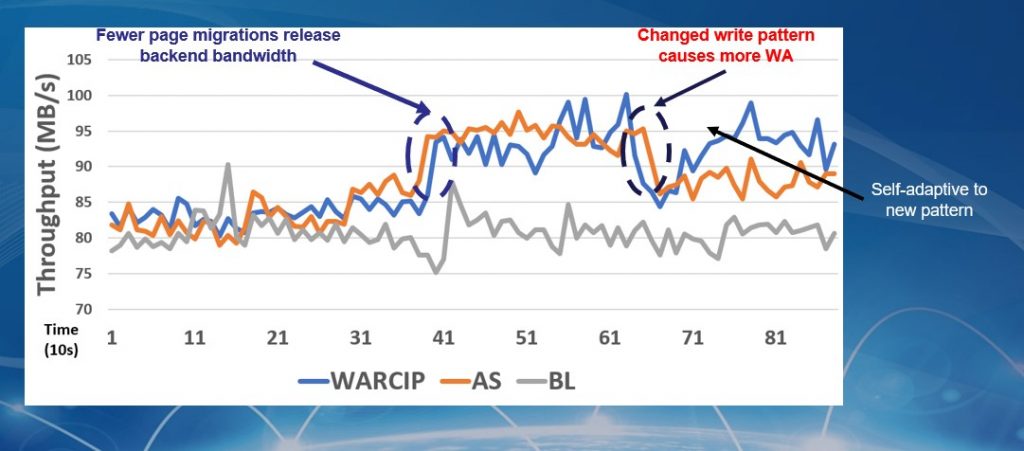
下面是我们做的实验结果,通过在30个左右的I/O Traces数据上的对比实验,大家可以看到“写放大”的减少是很可观的;并且,整个方法是存储系统自动完成的,无须工程师的人工干预。

目前,还有一项技术也在产品里面做实验。我们注意到,监督式学习(Supervised Learning)模型中循环神经网络可对数据序列有效预测,其在语音识别、语言处理等领域被广泛运用。我们技术的基本原理就是——将其这个优势发挥在存储领域,利用这个技术来学习I/O Trace的模式并预测。在一个循环神经网络基本的Cell里,这些Gates需要长时间地在I/O操作的同时进行学习,产生下一阶段I/O的预测结果;并通过反向传播机制,对模型进行调整,以求更拟合实际I/O模式。
随着学习时间的增加、模型的不断训练,一个星期或者两个星期就会看到效果,根据历史来预测将来。预测问题一般需要定义一个滑动窗口,这个滑动窗口包括:一部分历史的I/O,当前的I/O,以及未来的I/O。我们的网络有四层:Input Layer、Hidden Layer、LSTM Layer和Output Layer。最终模型大小只有264KB。
随着学习时间的增加、模型的不断训练,一个星期或者两个星期就会看到实际与预测的I/O模式逐渐拟合。这个图展示了系统运行时实时的比较情况,红线代表了实际的I/O Trace,蓝线则是预测的I/O Trace。大家注意到了,在通过滑动窗口选取不同时间段上,两者的形状和结果都非常接近;并且,基于FPGA的开发实验中,资源占用也是可以接受的。
通过上面的介绍,大家看到了,通过机器学习与人工智能技术的运用,存储系统得到了性能的提升与功能的增强。另外,我们已与东芝合作,采用基于XL-Flash进行SSD优化与研究。DapuStor对存储新技术的探索将在未来给大家带来更多的惊喜,更多的机器学习技术在闪存固态盘领域的应用与研究,将使新一代存储智能化——使其具有更好的性能、更可靠的稳定性、更久的寿命。







