
8月22日-23日,2019全球闪存峰会(Flash Memory World)在杭州国际博览中心正式召开,盛邀众多存储行业技术专家与知名企业代表等发表主题演讲,以便更快更好地推动闪存及芯片市场发展,增进产业上下游交流与互动。

美国杜克大学电子与计算机工程系教授、IEEE Fellow 陈怡然,受邀出席了智能存储与存储新架构学术论坛,并发表《人工智能应用开发的Processing-In-Memory(PIM)解决方案》的主题演讲。
整理速记如下(未经演讲人确认)。
非常感谢大会邀请我来给大家做关于存内计算的报告,我今天讲的题目是存内计算如何在人工智能应用上的解决方案和它们的一些背景。
大家知道,深度学习特别火,在日常有非常广泛的应用,比如图像处理、对象锁定、翻译、语音识别,甚至包括手势翻译、医疗影像等等,而且这些应用实际上是呈现一个爆炸性的增长。
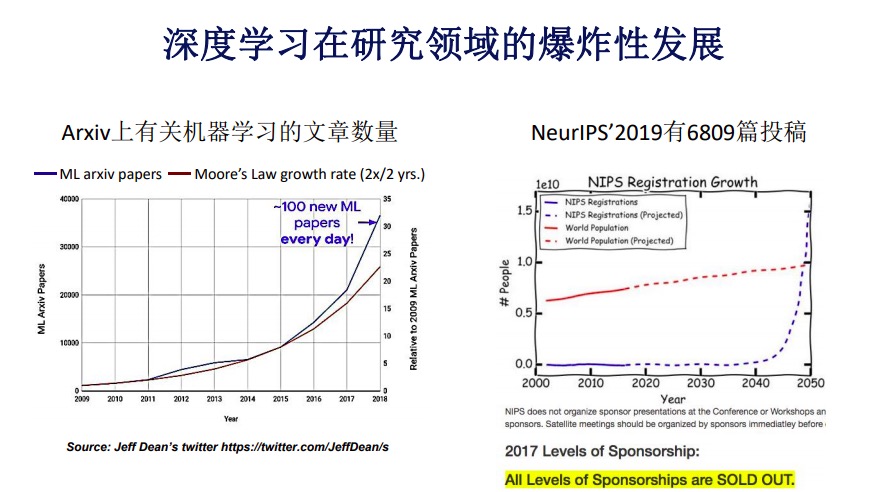
深度学习在我们科研领域仍然保持指数级增长的态势。这里有两张图,第一张图,左边的线形图是Arxiv网站有关机器学习的发表文章数量。在过去的十年里其数量基本呈指数增长态势,右边是摩尔定律,差不多每两年翻一番,前者的趋势已经超过摩尔定律的趋势,是非常惊人的数量增长。
右图更有意思了,NeurIPS是神经网络研究中极为重要的会议,每年投稿量也基本呈指数级增长,去年有将近700篇投稿量,而参会人数也在呈指数级增长,以至于在前年开始限制大会注册的人数。有人画了一张图,如果允许大会注册不受限,那么在2050年大会参赛的总人数将超过全世界人口的总数,当然这是大家开的一个玩笑。
机器学习在工业界的发展基本也是呈指数级增长。2013年如果大家回去看英伟达,当时的年会还在讲游戏,2014年的时候就完全转到深度学习上了。2013年英伟达开始做人工智能联盟,当年只有100家企业入选。这个数字在2017年增长到差不多2.7万家,也就是说四年的时间这个数字增长了270倍。当然,像谷歌、百度All in AI,内部关于人工智能的项目数也有巨大增长。
在神经网络技术70余年历程当中我们经历了很多发展,1940年代第一次提出电子脑概念,大家希望通过生物上的神经网络研究应用到电子设计的领域,能够实现相应的功能。
在1957年第一次发明了感知机,基本上神经元加上神经突出的结构,它能够完成简单的设计,在后面的时间里我们逐渐加入了非线性,加入对于信号控制等更丰富的架构。
第一个实际可应用的神经网络是在六十年代发明的,是MLP多层感知机,主要有多层神经网络能够完成比较复杂的功能,这个架构一直在被广泛应用,而且仍然是最广泛应用的神经网络的架构。
1979年,日本人发明了Neocognitron(神经认知机模型),第一次把卷积结构引入到神经网络里。大家经常讲Yann LeCun发明了卷积神经网络,这实际上是有道理的,他是一个集大成者,但卷积结构实际上是福岛邦彦在1979年发明的。在之后发明了后向传播。此前如果进行网络序列的时候,要从前开始序列,希望输出能够满足我们的要求,大家知道这个是非常困难的。
在1986年发明了后向传播,我们先看输出差多少,根据这个差值再反过来去训练这个网络。紧接着遇到很多问题,比如这种差别会越来越小,逐渐就消失了。还有比如说在那个年代,计算机比现在大概要慢10的7次方,很多想法都没有办法实现。
一直到2006年有一篇文章说,我们可以用GPU来进行神经网络的训练,从那个时候开始才真正进入了人工智能时代。人工智能发展有三次主要的浪潮,每次浪潮都伴随着基础架构的更新,比如在1950年我们第一次发明了计算机,80年代末PC开始进入各个行业,尤其是研究领域,到现在包括GPU的广泛应用,作为算力的提升,对于存储要求一直在不断地增长。
从右边这张图大家可以看到,蓝色部分是我们网络规模的增长态势,但在过去几年里无论是GPU也罢,存储也罢,基本都是线性增长,在这个过程当中差别会变得越来越大。
深度学习的硬件加速其实有很多不同的平台,比如说像GPU、FPGA,甚至有些公司在做ASIC设计,还有其他比较新型的架构,都是不同的解决方案。这些解决方案各自有优势和劣势。
比如说当你用GPU的时候,它可能更普适化一些,但反过来计算能效可能就更低一些。而用我们的自研设计,周期会变长,反过来讲能效会越来越高。
一个比较明显的例子就是英伟达的GPU,基本上是一个普适平台,现在绝大多数的人工智能算法训练都在GPU平台上完成。另外一个例子谷歌的TPU,完全是为了业务场景设计的,因此TPU会在单一业务场景下,相比GPU会有更好的性能表现,当然功耗也非常高,每个芯片200瓦功耗。
传统冯诺依曼体系在神经网络里被认为不是十分有效,因为有几个问题,第一个问题是计算和存储分开,导致存储增长态势跟计算增长态势不一致,在过去这些年里随着主频不断地提高,片上多核的引入,差别会一直在增大。
除此之外,我们没办法在固定时间内将芯片上产生的热量全部挪走,因此逐渐摒弃了越来越高的使用频率,转而在片上集成更多的核。当然,对于单一线程由于并行度有限,对性能发展造成了一定的影响。
从存储角度来讲,我们遇到的最大问题是内存墙,因为在冯诺依曼体系里计算和存储是分开的。也就是说,当需要一个数的时候,需要从存储器里读到运算器里面。比如我有CPU做多核,有缓存,有一些忆阻器,到其他的存储里面去。我们实际上分成三个部分,计算、存储与其之间的通讯。
2016年有过一个统计,真正在计算的时候,在加法器、乘法器这样的运算器里消耗功耗是非常低的,绝大部分功耗消耗在存储本身的读取上。大家紧接着想到两种方法。一种是把片上存储做大,另一种把计算下沉到存储端,就是直接在存储里做计算,而不把计算再挪到计算单元里去。好处就是避免了功耗较高的读取,以及一些性能优势。

举一个例子,传统AI芯片也面临一样的问题,这是某家一线厂商AI芯片的版图,可以看到虽然芯片这么大,但实际上里面真正用于计算的单元只有中间红色那一块(FU),其他部分要么是片上存储,要么是存储控制单元。所以传统AI芯片几大技术特点实际上非常简单:
第一,增大乘法器的矩阵以便获得更高的计算力,在同一时钟下可以得到更多的计算能力。
第二,增加片上内存的容量以便获得更大的存储空间,并减少对片外存储器的读写次数。
第三,增加存储器与有效单元之间的带宽,更快地获得数据,我们都知道在AI芯片里数据是像流媒体一样不断进来的。
第四,传统存储器不具备在电源关闭之后还保留数据的能力,也就是说把它关掉重开,所有数据都要从底层存储系统中往上把它读取进来。
而这一切的技术特点,当你在往下走的时候都会带来更大的芯片面积,更多的硬件成本和功耗。
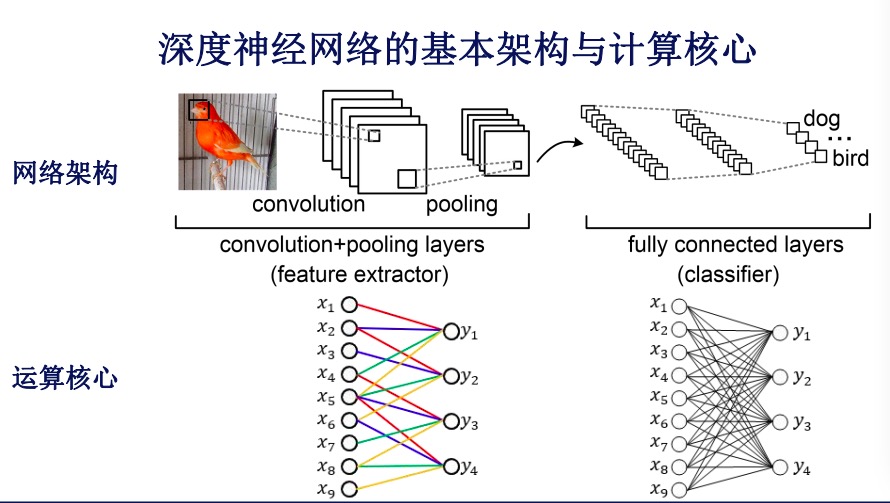
深度神经网络的基本架构与计算核心并不复杂,相对我们工程计算领域实际上只有两个,一个是卷积层,这个层基本上的架构输入层,连接输入、输出。第二个是全连接网络,每个节点都与输出的节点连在一起。所以左边我们认为是计算占优,右边是存储占优,在实际计算过程中,都需要不断地进行优化。
为什么存内计算会适用于深度神经网络呢?存内计算其实并不是新想法,在存储器容量不断增大过程中已经有很多人在做这方面的工作了。但如果大家来看这个计算核心,它与传统科学计算有一个本质的区别,这个区别是做一个乘法,一般都是两数相乘,这里面输入是不断地变化,我们在处理新的语音信号,但当我们的神经网络训练好后是固定在那个地方的。也就是说,训练好之后是不变的且存在某一个地方。
大家会发现这三个变量里,有一个是你要得到的变量,有两个是输入量,但两个输入里面有一个是不变的情况下,不变的这个量实际上就应该被存在内存里面,而且就应该直接在这个地方进行计算。
我们不需要把它挪到另外的地方,而科学计算两个数都是随时在变的,可能从存储器里读出来,也可能是平时算的,这种情况下存储计算就不是那么有优势,这就是为什么存内计算比较适用以于深度神经网络或者是未来更应用广泛的图计算领域。
我们知道英伟达有很多的非易失性存储器也可以达到这样的效果,就像忆阻器,它其实就是天生可以做这件事情的一个器件。简单来讲它就是一个纳米器件,它的组织可以随着加的电信号变化不断地变化,来代表某一个神经网络里面的权重。
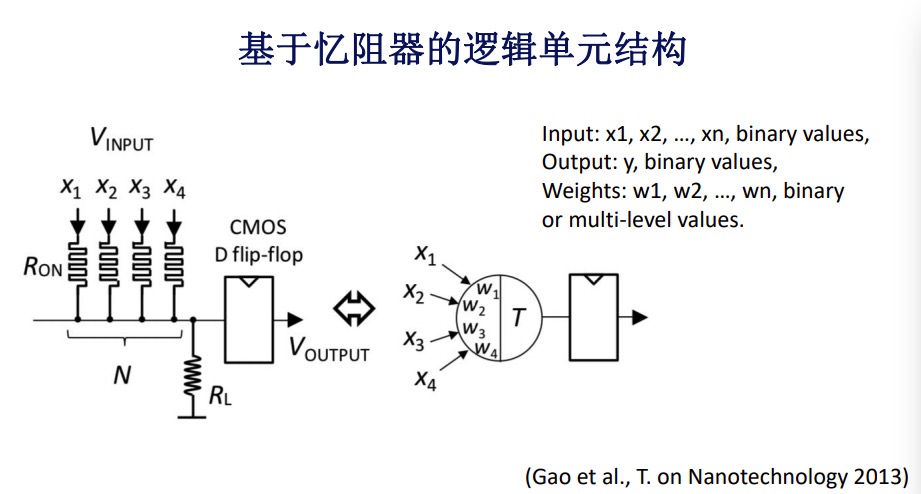
早先的存内计算希望能通过这种新型存储器完成逻辑单元,它的基本趋势把这些输入,主要是电流,当它们相加的时候大于某个阈值,通过调整每一个上面的组织和阈值可以完成不同逻辑的运算,这是一个例子。大家可以看到根据不同输入的数目,以及不同阈值的选择,我可以完成像逻辑学运算,这是早期存内计算的方式。
但在最近的应用中,大家发现作为存内计算,我们如果把它应用范围缩小到像人工神经网络范围,实际上我们可以用更简单的架构来完成。我们知道基本的计算单元在神经网络里面就一个向量跟一个矩阵相乘,而这个向量可以通过输入的电信号来表示,矩阵可以通过互联结构,在每一个点上的组织变化来表示。
当我有一个输入的电压,乘上互联结构上每一个点的电导,再把它的相加得到输出的电流,实际上就是一个向量和矩阵相乘的结果,这是非常有革命性意义的一个设计,最早是惠普提出的。
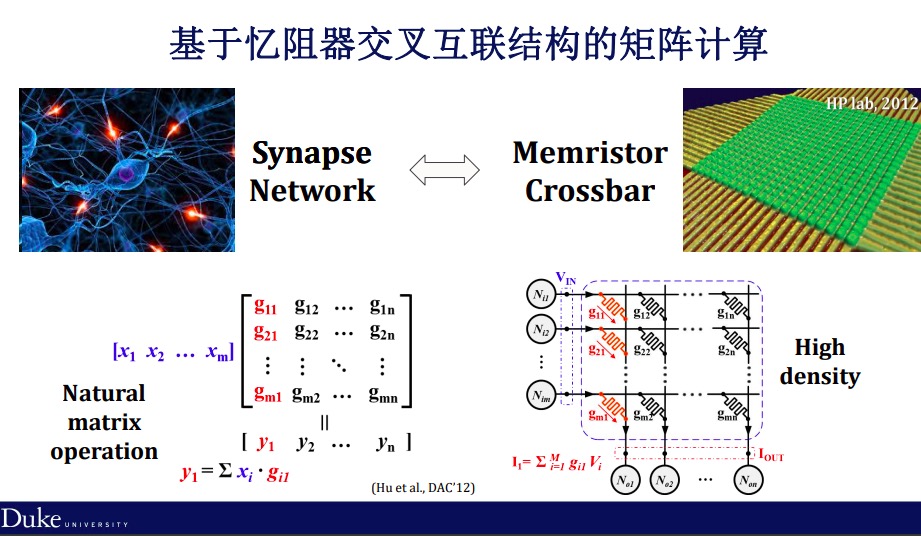
根据这个想法我们可以做很多的应用,比如根据忆阻器交叉互联结构可以做深度学习的加速器。在每一个框架下面都是这样的互联结构,有输入、输出的变化。同时,一些存内架构允许你把神经网络存在里面时,不需要把它挪到别的地方,然后通过计算直接得到输出,不需要经过任何像传统CPU、GPU的过程。
当然,网络参数组织形势可以是非常多样的,比如说在做卷积的时候,全部都展开,放在不同的行和列之间。而且中间有一些交叉,这些交叉可以极大地提高变形度,当然会有一些数字不同的拷贝,同时去进行运算。
我们刚才讲到可以提高并行度,实际上并行度和功耗本身是一对可调的参数,并行度越高,功耗就越大,反过来,计算程度越短,实际上在设计上带来了很多的灵活性。
除此之外,最近的一些研究,大家在关于数据流的优化方面,简单讲如果有这样的架构,在输入过程中很多数据可以重复使用,我们可以通过重复使用降低数据本身的管理要求,提高并行度。比如可以在更小的颗粒度上去做这样的数据并行管理,使得一个数据进来之后可以同时满足不同的计算要求,使得计算效能能够成倍的提高,当然也提高功耗。
其它适合存内计算的应用还有很多,比如像脉冲神经网络,刚才讲原来数字实际上是用电压或者电流来表示的,但是在人的神经网络里面实际上所有的数据都是通过脉冲来表示的。脉冲本身幅度,相互之间的时间不同关系,甚至包括出现的频率本身都是可以用来做编码的,这种编码极大地丰富了计算之间的灵活性,使得资源的能效有所提高。
我们也知道神经网络实际上是图计算的一种,本身就是一个拓扑结构,同样的这种架构延伸到图计算,也是非常热的关于存内计算的研究领域。这里面有一个简单的例子,当你的输入脉冲情况下并不需要通过模拟信号到输入信号的转化,而是用更多的像做积分再去产生新的数字,这样脉冲信号本身很有点类似人的神经网络,在电路上做一些相应的变化。
我们在过去的六七年里,基本每半年都会推出不同的芯片,所有的架构都有过尝试,这是其中的一些关于忆阻器的芯片,还有基于传统芯片,今天时间关系没有具体讲。
最近6月份在日本也发表了最新的AI芯片参数,基于存内计算的。大家可以看到加粗的那行,在基础功耗,尤其是在计算集成度上实际上是有非常显著优势的,这也就意味着这种技术在未来很快进入到应用里去。

多讲一个关于芯片设计的问题,我知道在座的各位专家和老师大家都是做系统的比较多,做系统的周期比较长,做芯片周期还会更长一点,大家知道一个芯片的设计周期从设计验证到制造校验,到规格设计等会持续大概1-2年的时间。现在我们遇到最大的问题,硬件设计往往跟软件的设计不匹配。
比如谷歌TPU,大家发现在谷歌TPU从 1.1-3.0版本升级时间是一年左右,但实际在神经网络开发架构上经历了7个左右的版本。换句话说,芯片本身对于像神经网络这样的应用前瞻性知识要求是非常高的。
全球忆阻器产业分布或者说是存内计算分布其实也很广。大家现在能看到,基本每个国家都有在做,以不同的形式在做。今天只是用忆阻器本身做一个例子。
大家要展望一下关于存内计算技术对未来的应用,我觉得存内计算包括机器学习在内很多新型计算里面都展现出了巨大的潜力,我所说的新型计算包括机器学习等等。
随着工业水平不断地进步,不断增长的存储密度为存内计算未来发展铺平了道路。现在已知各个公司在28纳米、22纳米,甚至有些在10纳米都已经有了相应的布局,这些布局不仅仅是在存储,也为存内计算在未来发展铺平了道路。
存内计算在功能上的多样性和可重构性带来了非常广泛的应用,虽然基础的设计可能会比较简单,凭借非一致性以及对电路设计本身可适应性,实际上对很多的应用都会事先把应用想办法映射到硬件上,所以这可能是传统存储器不具备的。
最后,我们觉得存内计算在未来两三年会越来越成熟,很多的公司研发也会有大规模投入,并逐渐过渡到新型存储器的设计形态,这是我们对于未来的预估,基本上就是这样,谢谢大家!







