2019年8月, 网络界两大盛会,ACM Sigcomm2019和APNet’19在北京相继召开,来自世界各地精英齐聚北京,共同分享他们在网络研究中的成果和面临的挑战。两个大会都从如何解决传统TCP协议面临的问题入手,提出了各种不同层面的解决方案,从4G/5G无线网络,到边缘数据中心网络,到核心数据中心,再到跨数据中心的网络等。
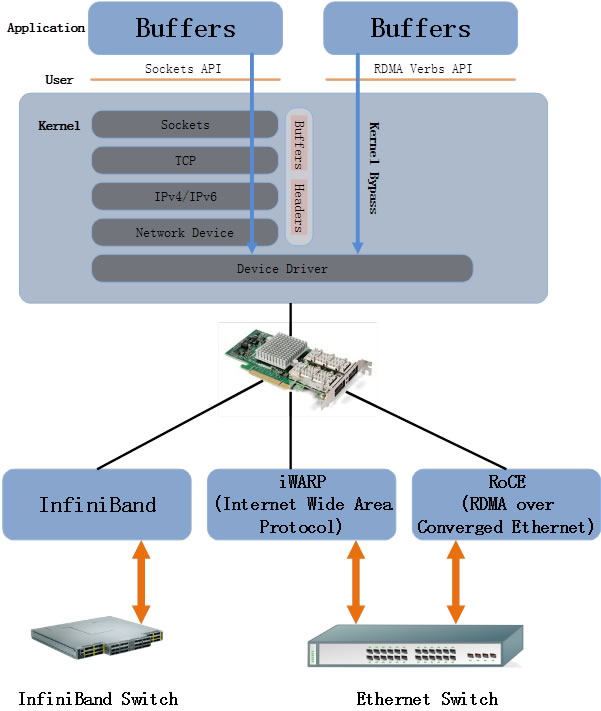
在数据中心网络的报告中,RDMA的大规模应用和网络拥塞控制成为了两个大会上的热门话题,多篇论文谈到了这个问题和他们的解决方案。其中的两篇论文《HPCC: High Precision Congestion Control》和《Gentle Flow Control: Avoiding Deadlock In Lossless Networks》收到了格外的关注。
《HPCC: High Precision Congestion Control》是由哈佛大学、阿里巴巴公司和剑桥大学联合发表,该论文介绍了由于RDMA技术的性能优势,基于RDMA技术的网络已经在数据中心中得到大规模部署,但是随着部署规模的越来越大,传统的拥塞控制CC(Congestion Control)机制暴露出了其局限性,如收敛速度、稳定性、配置复杂等。为了解决这个问题,本论文中介绍了HPCC(High Precision Congestion Control)技术,利用交换机网络遥测技术(INT)来获得精确的链路负载信息,并通知到发送端,由发送端根据链路负载进行流量调整;同时通过将Per-ACK的Reaction做成Per-RTT的Reaction,来确保高性能的传输下不会出现Over-React。从而实现了高速且高精度的拥塞控制- High Precision Congestion Control。这个实现对于RDMA技术的大规模应用起到了很重要的作用,为广大的RDMA用户提供了新的思路和方向。随着数据中心的规模增大,RDMA技术成为了保障数据中心性能的重要手段,传统的TCP网络中的很多技术已经不能适应高速RDMA网络的需求,新技术的涌现推动力RDMA技术在大规模数据中心中应用的成熟。
清华大学代表在介绍其论文《Gentle Flow Control: Avoiding Deadlock In Lossless Networks》时强调,无论是计算还是存储,分布式系统已经成为了提升性能的必经之路,很多基于分布式系统的应用都需要无损网络的支持。传统的无损网络实现方案(如PFC等)有时会带来网络的死锁,目前面向解决网络死锁的方案增加了网络配置的复杂度,同时也影响到了网络的性能。针对这个问题,清华大学提出了温和流量控制(GFC)的方式来控制端口速率,使所有端口都能保持数据包的流动,即使存在循环缓存区的依赖关系,也可以避免网络的死锁。清华大学还用实验和仿真验证了GFC的实现和对网络带宽的影响(小于0.5%)。
这篇文章提供了另一种实现大规模RDMA应用的思路,值得数据中心用户去借鉴。 Mellanox公司作为RDMA技术和设备的主要提供商,RDMA技术正在成为以数据为中心的计算模型的关键,如何快速、安全的传输和处理数据,直接关系到数据中心性能的好坏。在Sigcomm和APNet这两个大会中,关于对RDMA、无损网络、拥塞控制等的探索和研究,为RDMA技术的大规模应用起到了积极的推动作用,证明了RDMA大规模应用的可行性。
Mellanox的网络计算(In-Network Computing)技术,除了RDMA以外,更是添加了SHARP(Scalable Hierarchical Aggregation and Reduction Protocol, 在交换机中做通信计算) 技术, SHIELD(Self Healing Technology,网络自愈) 技术, AR(Adaptive Routing,动态路由) 等新的技术来面对传统以CPU为核心的数据中心面临的通信和计算的瓶颈问题,通过新的网络计算技术,将网络变成了IPU(I/O Process Unit),将计算工作分散到了数据中心的各个单元,计算将会发生在最合适的地方,而不是必须要发送到CPU再做计算,实现了真正的以数据为中心。
In-CPU Computing,In-Network Computing和In-Storage Computing的有效整合,将会是构建未来高性能数据中心的关键。网络作为CPU到CPU, CPU到存储以及存储到存储之间通信的必经之路,已经成为了数据中心性能的最大挑战。新的挑战需要新的技术来解决,增加蜡烛的数量不能发明电力;增加CPU的数量、网络的带宽和降低网络的延迟不再能解决目前数据中心的挑战,需要新的创意、新的技术来构建下一代的数据中心。