DataCanvas布道师团队成员之首席APS产品掌门人杨 健
携全新APS一二三系列闪亮登场
DataCanvas布道师APS一二三系列
将呈现机器学习平台全视角解析
丰富的干货知识
幽默的语言风格
带你走进机器学习的千趣世界!
呈上首篇

《APS一二三》
快随八斗先睹为快吧!
预计到2021年,全球企业在机器学习上的支出预计将达到576亿美元,复合年增长率(CAGR)为50.1%。机器学习平台,一场新的盛宴已经开始。
BI到AI的转变
伴随着大数据时代的来临几乎同时吹响了AI时代的号角,传统的BI正在被历史的车轮无情的碾压,挣扎、蜕变。由B到A两个字母轻巧的变换却蕴藏着技术变革巨大的力量,很多行业的模式在演变、颠覆并潜移默化到我们生活的细微处。金融、保险、医疗、汽车、交通、制造,AI已经无处不在,发展之快应用之深已经快像空气一样让我们感知不到它的存在了,但谁又能离得了空气呢?
说到BI和AI永远也绕不过去的就是数据挖掘和机器学习,这几乎可以是两个领域的代名词。我们就从这两个词说起。
在《数据挖掘与预测分析》一书中定义,“数据挖掘是从数据集中发现有用的模式和趋势的过程”,主要围绕着数据探索、数据统计、关联分析、离群分析这些任务开展,当然也包含了聚类、分类、预测这部分内容,但从本质上说数据挖掘的核心是“洞察”,是辅助人类完成更好的决策。
机器学习是人工智能领域最能体现智能内涵的分支,尤其是“学习”,赫尔伯特·西蒙曾对学习给出定义“如果一个系统能够通过执行某个过程改进它的性能,这就是学习”,机器学习就是通过数据和算法提高预测准确性的系统,因此我们可以看到机器学习更侧重于“预测”,是辅助机器实现更好的决策。

从人为决策转向机器决策,业务的运营效率将是指数级的提升,业务模式的创新将是颠覆性和开创性的。AI的需求已经井喷,但AI的生产力却成为了最大的瓶颈。企业在被AI强大诱惑力的吸引下把目光投向了一个新的领域:机器学习平台。
机器学习平台的由来
2015前后BI市场发生了显著的变化,用户对BI的需求从描述性、诊断性分析开始转向预测性、指导性分析,从对传统的报表、仪表盘、可视化的需求转向预测分析工具的需求。
2015年和2016年Gartner把《高级分析平台的魔力象限》从《商业智能的魔力象限》中分离出来单独发布了行业分析报告。
Gartner对高级分析平台的定义是:
使用统计、描述性、预测性数据挖掘,机器学习等方法对各种数据进行分析,以产生洞见。
这里已经出现了预测性数据挖掘和机器学习的身影,用户的需求时刻驾驭着市场的风云变换。到了2017年Gartner索性把《高级分析平台魔力象限》直接改为《数据科学平台魔力象限》,彻底斩断了和BI之间的纠缠。到了2018年进一步改为《数据科学和机器学习平台魔力象限》正式为“机器学习平台”在市场上确立了名份。
市场格局
附图是2015~2019这几年的魔力象限,上面的各个厂商的位置变化很有意思
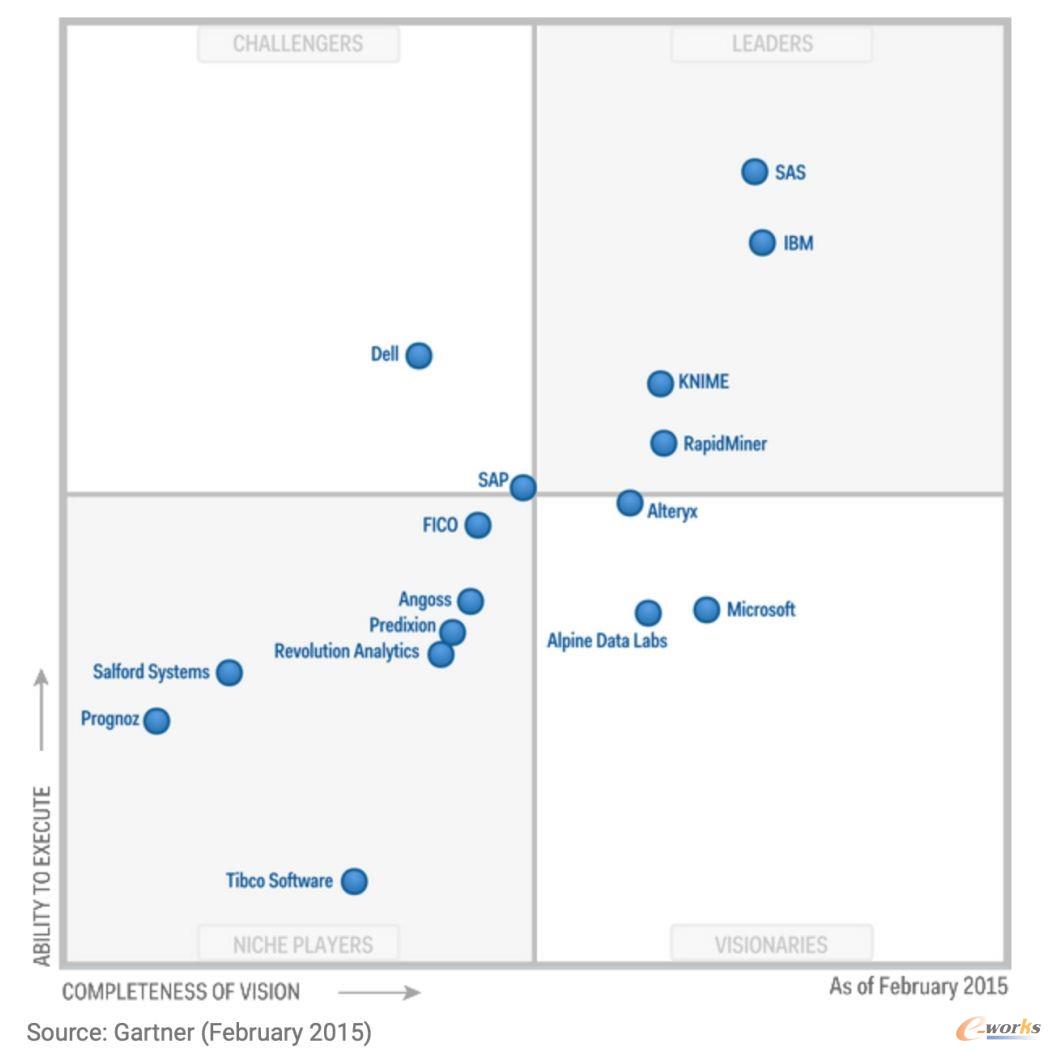
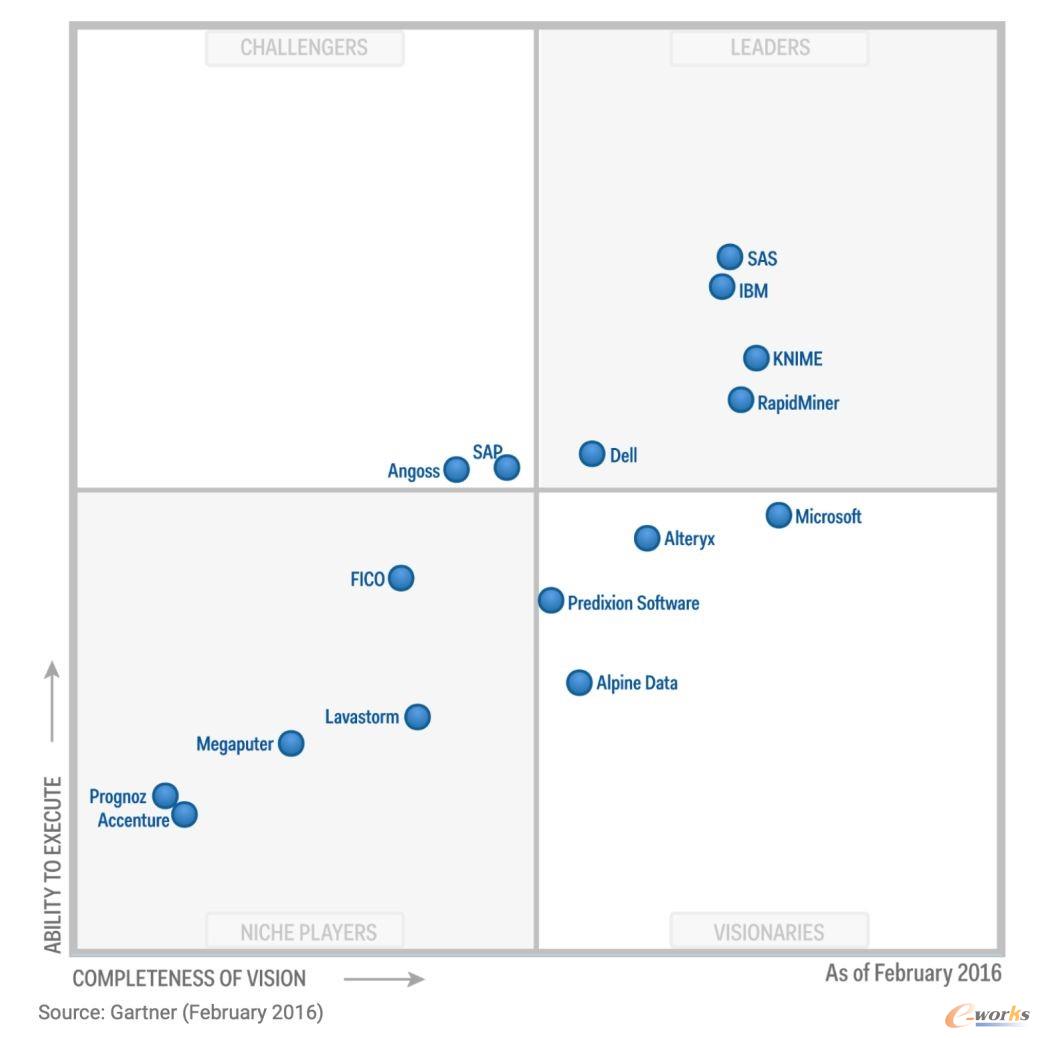
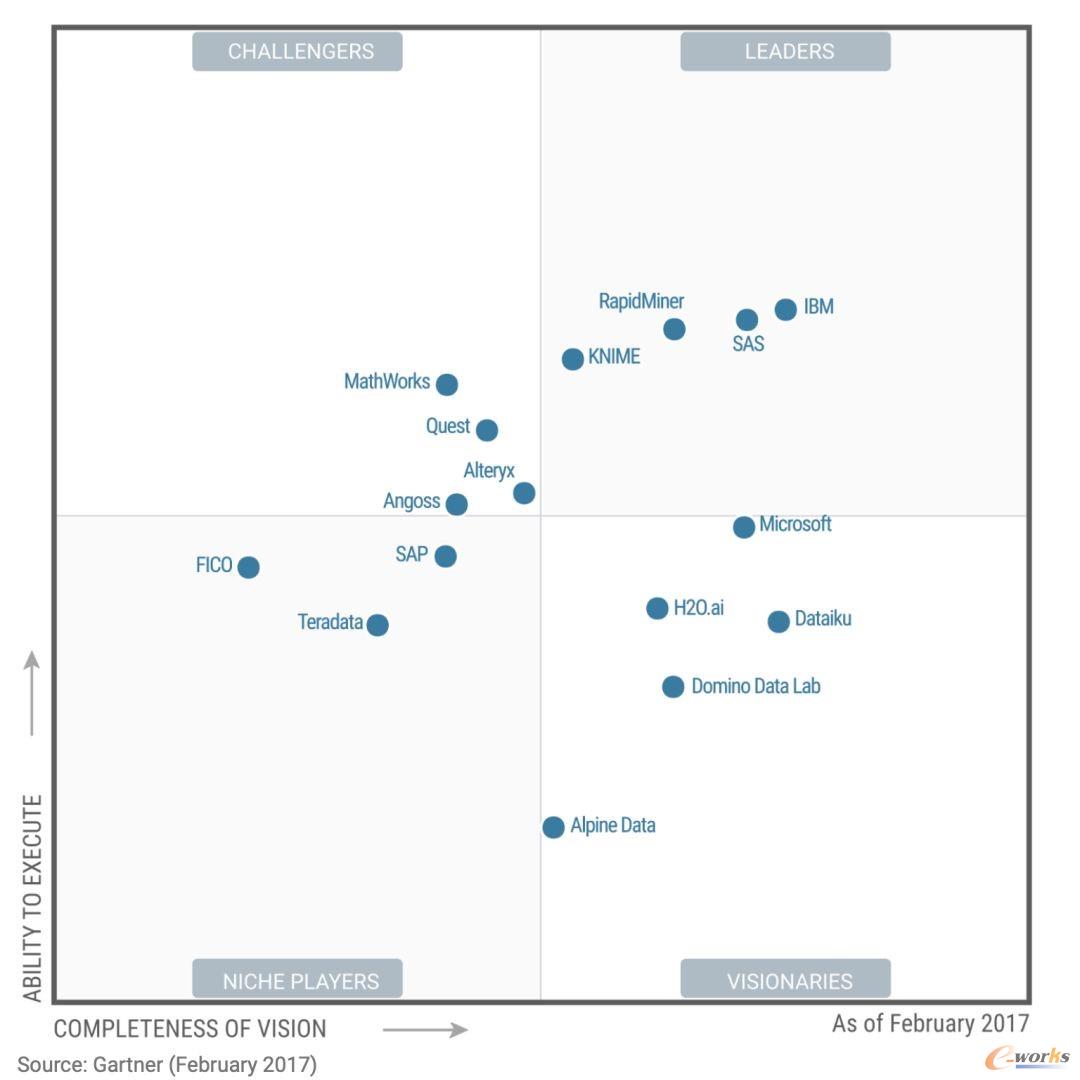
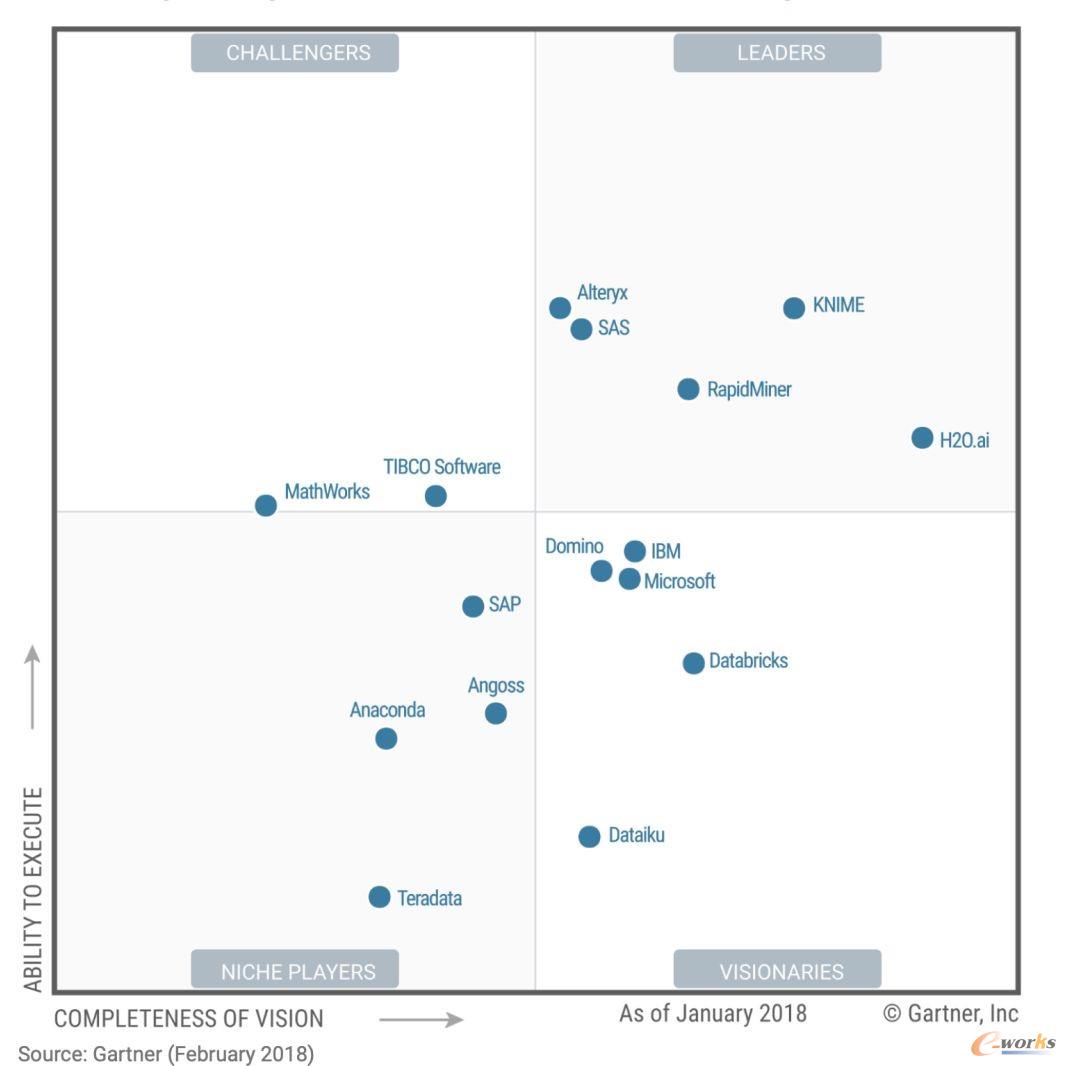
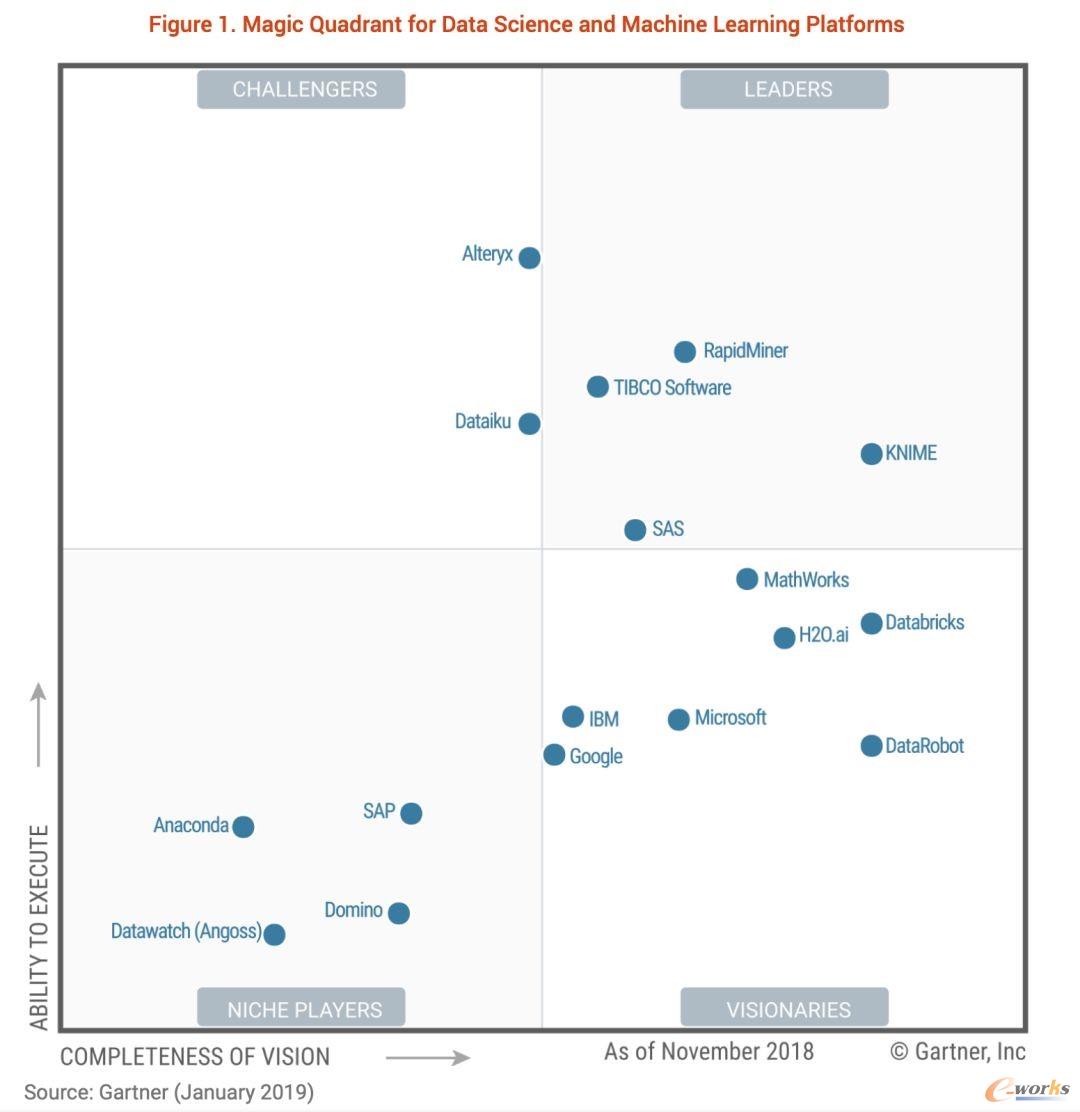
引用自Gartner
SAS、IBM、RapidMiner、KNIME这些豪强长期盘踞在领导者象限,Alteryx、Dataiku、Datarobot这些新星在远见者和挑战者象限不断向领导者发起冲击,开源阵营H2O.ai、Anaconda也保持这强劲的势头,值得注意的是左下角利基者象限里却是城头变幻大王旗你方唱罢我登场。
技术的变革让传统巨头SAS倍感压力,新兴的数据科学领域更加青睐使用Python、R这样开源生态语言来完成建模分析,SAS虽然也极力向新的阵营靠拢,但SAS语言是它的核心,就像统治者和革命者之间天生的矛盾难以调和。
开源社区的活跃也让这个领域迅速发展,不仅是开发语言方面:
● 开源的机器学习框架,如Tensorflow、Scikit-Learn、SparkML、PyTorch
● 开源的Notebook交互式分析工具,如Jupyter、Zeppelin
● 开源的大数据平台,Hadoop、Spark
● 开源的机器学习算法,H2O、DL4J
● 开源的可视化工具,D3、Plotly
这些开源力量不断为数据科学领域注入新鲜的能量,这里也正好引出一个话题,很多产品中会频繁的出现一些开源组件的身影,包括DataCanvas APS也集成了不少开源组件。我曾经遇到客户问了一个这样的问题,“DataCanvas APS是不是就是把一些开源组件攒到一起的产品?”,我想他隐含的问题应该还包括:“那我们企业为什么不直接使用开源组件?采购APS的价值是什么?”,这些问题我会在后面的系列专门来回答。请各位关注后续的更新。
前几天听一个节目我觉得很有意思,是说对于斑马我们身边大多数人第一印象是有着黑色斑纹的白马,但据说在非洲普遍认为是有着白色斑纹的黑马。任何事物在不同的本位都能观察到不同的内容,体察到不同的内涵,就“机器学习平台“来说:
● 对行业从业者来说这是饭碗,会关注它的行业发展、市场规模、技术生态、客户需求、未来趋势;
● 企业的领导者会把它当作生产力要素,更关注它如何提升企业的竞争力和盈利能力;
● 平台的使用者会把它作为工具,而更关注它是否能有效提高工作效率;
我们会分成市场篇、概念篇、故事篇、工具篇、价值篇、技术&架构篇、本质篇等几个不同的专题来全方位的定义和诠释什么是机器学习平台。本文既这个系列的第一篇。
Q&A
八斗:关于DataCanvas APS机器学习平台,使用者们都关心哪些问题?
杨健:使用者们从发现DataCanvas APS到交付使用,很像是一对未婚男女相处,从雾里看花、眉来眼去到恋爱磨合、结婚生子。不同阶段对APS的了解层次由浅入深,从第一印象的好感,到身世背景家底细节的追问,每一次接触中的提问如果不能完美解答俘获芳心,随时都有被灭灯的危险。我有幸在以上部分环节中扮演过追求者的角色,这里就把各种挑剔的女友、刁钻的丈母娘常常用来拷问的话题总结一二??
01
刚开始接触通常会问一些比较开放性的问题,考察你的三观人品个人魅力,比如:
● 什么是机器学习平台?–你是干啥的?
● 机器学习平台对企业有什么价值?–为啥要嫁给你?
● APS和其他的产品有什么不同,有什么优势?–为啥放弃别的追求者,选择你?
02
进一步会关注产品功能,考察你的相貌学识生活能力,比如:
● APS支持哪些算法?APS支持哪些开发语言?用户可以添加自己开发的算法吗?
● APS支持深度学习吗?Tensorflow行不行?还支持哪些框架?
● APS可以接入哪些数据源?可以和大数据平台对接吗?有什么要求和限制?
● APS支持可视化建模吗?预置了多少个算法模块?
● APS可以自动建模吗?有什么特点?比人类的建模水平高吗?
● APS训练的模型怎么使用呢?产品可以把模型上线成服务吗?如何监控?
● APS训练的模型可以导出吗?是什么格式?
● 用户用其他系统训练的模型可以导入到APS中并上线成服务吗?
● APS是如何管理用户权限的?团队如何协作呢?
03
这个阶段如果还算满意的话会进一步关注产品特性方面,考察体能耐力综合素质,比如:
● APS支持分布式吗?可以支持TB级的大规模数据全量训练吗?
● APS支持使用GPU训练吗?
● APS的训练模型需要多长时间,需要多少资源?
● APS部署需要什么样的配置?一台16c 32G的虚拟机可以部署吗?为什么不可以?
● APS的模型服务可以支持多大的吞吐量?时延可以达到毫秒级吗?
● APS支持企业级特性吗?APS高可用是怎么实现的?
● APS支持二次开发吗?提供什么样的接口?前台页面可以定制开发扩展吗?
04
再有一些是关注产品的技术细节的,盘问你的住房大小工资收入余额宝位数,比如:
● APS是如何调度GPU资源的?GPU可以共享使用吗?
● APS是如何对接Hadoop集群的?可以直接部署到Hadoop集群上吗?
● APS的数据是如何隔离的?安全性怎么保证?Docker就能保证安全隔离吗?
● APS的工作流可以对接用户的调度引擎吗?
● APS的数据抽象层是做什么的?是如何实现的?
● APS的模型服务是如何对接用户的应用系统的?支持什么样的接口和模型格式?
● APS的训练环境和生产环境是如何规划的,如何和用户的基础设施融合?
● APS如何实现自迭代?
● APS如何实现线上模型的A/B测试,冠军挑战策略的?
05
当然,还会拿前任前前任或者别人家的男友说事,比如:
● Google开源的Kubeflow也很不错,APS比他还优秀吗?
● xx产品的自研算法性能非常不错,APS也会提供一些自研算法吗?
● xx产品支持自动衍生高维特征,APS能做到吗?
● xx产品可以自迭代,APS能够实现吗?
● xx产品可以支持图数据库,APS可以吗?
● APS是不是就是攒了几个开源组件的产品?–你到底是低调奢华有内涵,还是穿着西服装大蒜,我跟着你下半辈子有前途吗?
……
八斗:Σ(っ°Д °;)っ连环问这么多,客户也太会提问了吧!
杨健:以上这些话题在《APS一二三》中基本都会涉及到,当然不限于此,欢迎大家留言把感兴趣的问题分享给我,我会把有代表性的内容整理出来一起加到这个系列中来。
八斗:想知道答案的小伙伴们,记得跟八斗一起追《APS一二三》的连载哦!