自UCloud在5月28日的TIC大会上发布“快杰”云主机后,已经过去了近半年的时间,在这半年间,“快杰”凭借优越的性能与极高的性价比,在云主机市场中走出了自己的独特道路。在这些成果背后,我们用两个词来阐述“快杰”的技术理念:All in one & One for all。

All in one & One for all
作为云计算的基石产品,云主机的核心特性决定了云上其它能力的拓展,也直接关乎于用户的使用体验。用户选择云计算的出发点在于:简单性,速度和经济性。但是由于互联网与IT服务的场景多样化,业内大多数厂商都是分别推出适应不同场景的云主机类型,但也因此带给了用户运维和采购的复杂度。
什么是“All in one”呢?“快杰”将自己定义为“简单”的产品。简单不仅意味着使用方便,还意味着多项软硬件技术的融合,以此为用户提供超高的产品性能。也就是说,当你面对各种业务场景下CPU、网络、存储的不同性能需求时,无需考虑太多因素,“快杰”均可满足。
这是“快杰”的一组数据:全面搭载Intel最新一代Cascade Lake处理器,配备25G基础网络并采用全新的网络增强2.0方案,支持RDMA-SSD云盘,网络性能最高可达1000万PPS,存储性能最高可达120万IOPS。
在产品上线之初,我们对“快杰”进行了跑分测试,测试结果显示,同等规格的配置下,“快杰”的性能明显优于市场上同类型的云主机产品。举个例子,在同样8核16G的配置下,“快杰”的网络性能较友商高出3倍多,存储性能有着近4倍的差异。
但是在这样的高配下,“快杰”的价格提升却不超过20%,部分配置机型的价格与普通机型价格基本持平或略有下降,云盘价格仅为市场同类产品的60%或者更低。“快杰”云主机用“One for all”的价格红利将所有技术又通通回馈给了用户。
“罗马不是一天建成的”,不论是All in one 还是 One for all,在这些数据的背后,都离不开UCloud在技术上的持续探索和积累。接下来,我们就来聊聊“快杰”背后的技术进阶之路。
一、 网络增强2.0:4倍性能提升+3倍时延下降
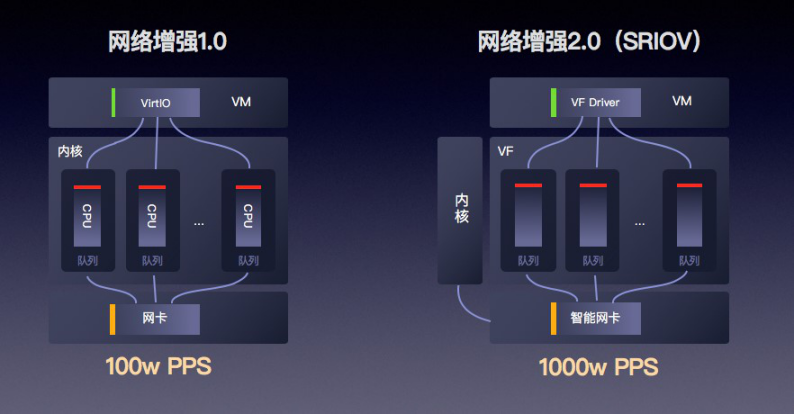
网络通道是严重制约云主机性能的瓶颈之一,在这里,值得一提的便是“快杰”在25G智能网卡网络增强能力方面做出的技术突破。
■ 硬件级别的网卡加速
基于云主机网络性能提升的需求,25G网络逐渐成为趋势。但是由于传统软件Virtual Switch方案的性能瓶颈:当物理网卡接收报文后,是按照转发逻辑发送给VHost线程,VHost再传递给虚拟机,因此VHost的处理能力就成为了影响虚拟机网络性能的关键。
在调研了业界主流的智能网卡方案之后,我们最终采用了基于Tc Flower Offload的OpenvSwitch开源方案,为“快杰”提供了硬件级别的网卡加速。虚拟机网卡可直接卸载到硬件,绕过宿主机内核,实现虚拟机到网卡的直接数据访问。相较于传统方案,新的智能网卡方案在整个Switch的转发性能为小包24Mpps,单VF的接收性能达15Mpps,使得网卡整体性能提升10倍以上,应用在云主机上,使得“快杰”的网络能力提升至少4倍,时延降低3倍。
■ 技术难点突破:虚拟机的热迁移
在该方案落地之时,我们遇到了一个技术难题:虚拟机的热迁移。因为各个厂商的SmartNIC都是基于VF passthrough的方案,而VF的不可迁移性为虚拟机迁移带来了困难,在此将我们的解决方案分享给大家。
我们发现,用户不需要手工设置bonding操作或者制作特定的镜像,可以妥善的解决用户介入的问题。受此启发,我们采用了 VF+standby Virtio-net的方式进行虚拟机的迁移。具体迁移过程为:
1、创建虚拟机自带Virtio-net网卡,随后在Host上选择一个VF 作为一个Hostdev的网卡,设置和Virtio-net网卡一样的MAC地址,attach到虚拟机里面,这样虚拟机就会对Virtio-net和VF网卡自动形成类似bonding的功能,此时,在Host上对于虚拟机就有两个网络Data Plane;
2、Virtio-net backend的tap device在虚拟机启动时自动加入到Host的OpenvSwitch bridge上,当虚拟机网卡进行切换的时候datapath也需要进行切换。VF attach到虚拟机后,在OpenvSwitch bridge上将VF_repr置换掉tap device;
除此以外,UCloud针对25G智能网卡的其他技术创新可查看:https://mp.weixin.qq.com/s/FUWklPXcRJXWdrWpsQHzrg
二、RDMA-SSD云盘:提供120万IOPS存储能力
在云盘优化方面,我们主要从IO接入层性能优化、RDMA网络加速及后端存储节点提升三方面来完成RDMA-SSD云盘的技术实现,最终为“快杰”提供120万IOPS的存储能力。
■ 基于SPDK的IO接入层性能优化
如下图,为传统的OEMU Virtio方案示意,在第3步时, QEMU里的驱动层通过Gate监听的Unix domain socket的转发IO请求时,存在额外的拷贝开销,因此成为IO接入层的性能瓶颈。
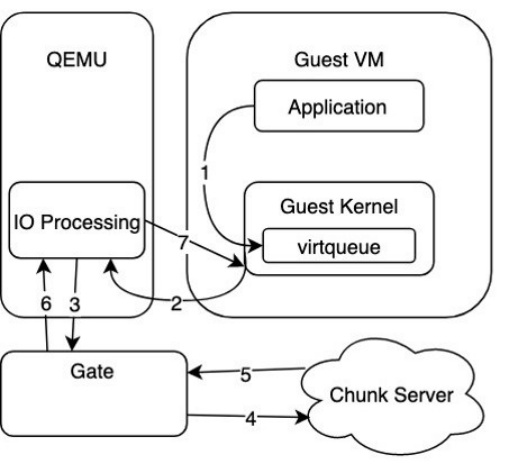
图:QEMU Virtio方案示意
针对该问题,UCloud使用了SPDK VHost来优化虚拟化IO路径。
(1)SPDK VHost:实现转发IO请求的零拷贝开销
SPDK(Storage Performance Development Kit )提供了一组用于编写高性能、可伸缩、用户态存储应用程序的工具和库,基本组成分为用户态、轮询、异步、无锁 NVMe 驱动,提供了从用户空间应用程序直接访问SSD的零拷贝、高度并行的访问。
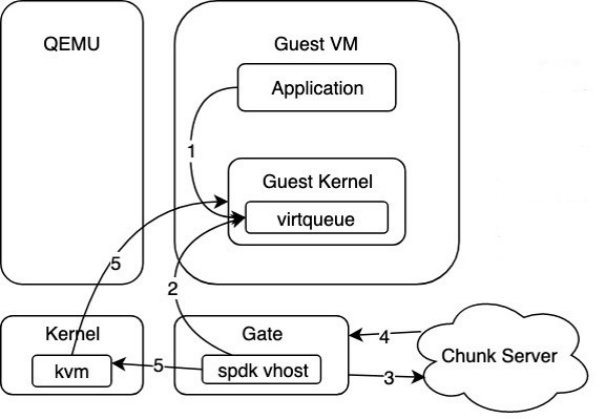
图:SPDK VHost方案
如上图,在应用SPDK VHost方案后,IO路径流程如下:1、提交IO到virtqueue;2、轮询virtqueue,处理新到来的IO;3-4、后端存储集群处理来自Gate的IO请求;5、通过irqfd通知Guest IO完成。
最终SPDK VHost通过共享大页内存的方式使得IO请求可以在两者之间快速传递这个过程中不需要做内存拷贝,完全是指针的传递,因此极大提升了IO路径的性能。
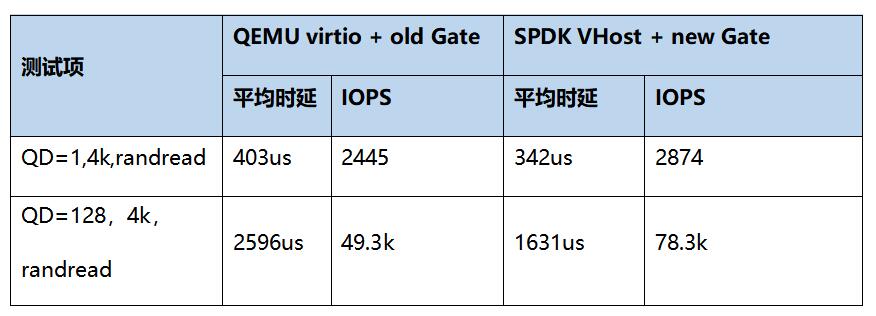
如下表,我们对新老Gate的性能做了测试对比。可以看到,在应用SPDK VHost以后,时延和IOPS得到了显著优化,时延降低61us,IOPS提升58%。
(2)开源技术难点攻破:SPDK热升级
在我们使用SPDK时,发现SPDK缺少一项重要功能——热升级。我们无法100%保证SPDK进程不会crash掉,一旦后端SPDK重启或者crash,前端QEMU里IO就会卡住,即使SPDK重启后也无法恢复。
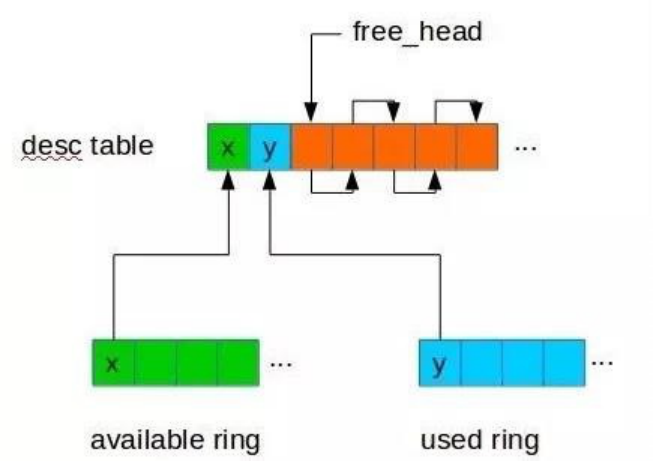
图:virtio vring机制示意
通过深入研究virtio vring的机制,我们发现在SPDK正常退出时,会保证所有的IO都已经处理完成并返回了才退出,也就是所在的virtio vring中是干净的。而在意外crash时是不能做这个保证的,意外crash时virtio vring中还有部分IO是没有被处理的,所以在SPDK恢复后需要扫描virtio vring将未处理的请求下发下去。
针对该问题,我们在QEMU中针对每个virtio vring申请一块共享内存,在初始化时发送给SPDK,SPDK在处理IO时会在该内存中记录每个virtio vring请求的状态,并在意外crash恢复后能利用该信息找出需要重新下发的请求,实现SPDK的热迁移。具体可查看https://mp.weixin.qq.com/s/UBRJhN58VQwDCHYZyDP02w了解。
2、RDMA网络加速
(1)TCP瓶颈
在解决了IO路径优化问题后,我们继续寻找提高云盘IO读写性能的关键点。在协议层面,我们发现使用TCP协议存在以下问题:
■ TCP收发数据存在网卡中断开销,以及内核态到用户态的拷贝开销;
■ TCP是基于流式传输的,因此通常网络框架(libevent)会使用一个缓冲区暂存数据,等到数据达到可处理的长度才从缓冲区移除,同样地,发包过程为了简化TCP缓冲区满引起的异常,网络框架也会有一个发送缓冲区,那么这里就会产生二次拷贝。
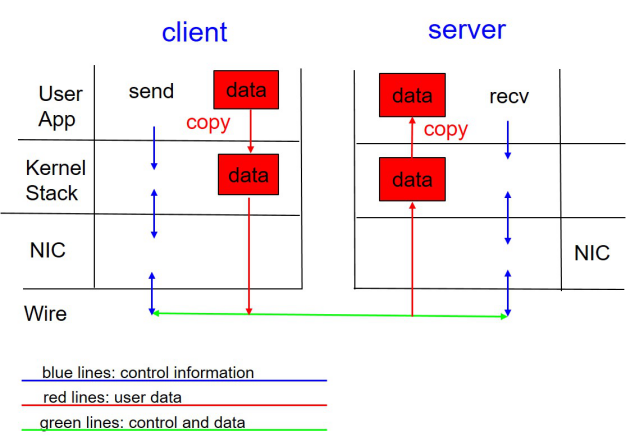
图:TCP协议原理示意
针对这个问题,我们用RDMA协议来代替TCP协议,来达到提升IOPS和时延的能力。
(2)RDMA代替TCP
RDMA(Remote Direct Memory Access)技术全称远程直接数据存取,是为了解决网络传输中服务器端数据处理的延迟而产生的。
使用RDMA代替TCP的优点如下:
■ RDMA数据面是bypass kernel的,数据在传输过程中由网卡做DMA,不存在数据拷贝问题。
■ RDMA收发包过程是没有上下文切换的,发送时将数据post_send投递到SQ上,然后通知网卡进行发送,发送完成在CQ产生一个CQE;接受过程有一些差异,RDMA需要提前post_recv一些buffer,网卡收包时直接写入buffer,并在CQ中产生一个CQE。
■ RDMA为消息式传输,即假设发送方发送一个长度为4K的包,接收方假如收到了,那么这个包的长度就是4K,不存在只收到一部分的情况。RDMA提供的这种能力可以简化收包流程,不需要像TCP一样去判断数据是否收全了,也就不存在TCP所需的缓冲区了。
■ RDMA的协议栈由网卡实现,数据面Offload到网卡上,解放了CPU,同时带来了更好的时延和吞吐。
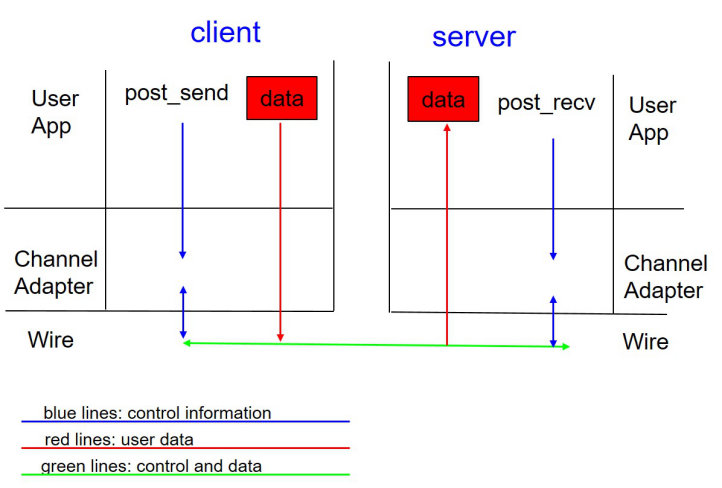
图:RDMA协议原理示意
3、后端存储节点IO Path加速
除了在IO路径接入与传输协议方面做了改进之外,UCloud还针对云硬盘后端存储节点进行了优化。
对于原有的Libaio with Kernel Driver,我们采用了SPDK NVMe Driver进行了替代,下图为Fio对比测试两者的单核性能情况,可以看到应用SPDK NVMe Driver后性能有了较大的提升。
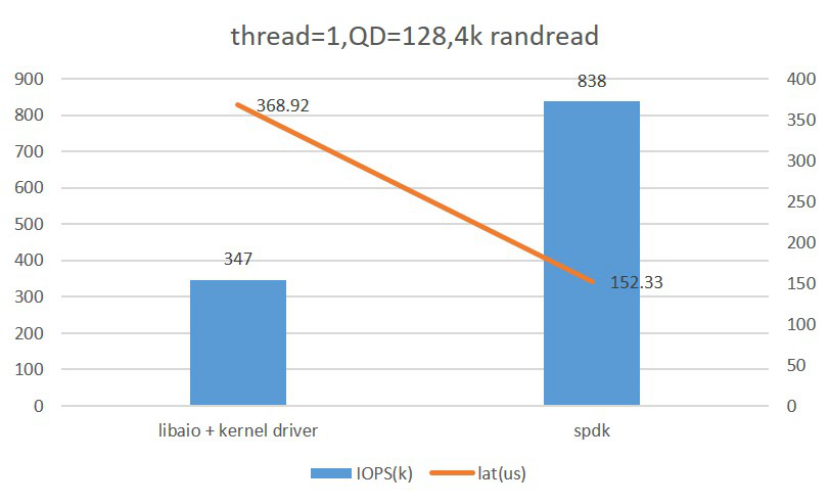
图:Libaio with Kernel Drive & SPDK NVMe Driver单核性能比较
此外,SPDK NVMe Driver使用轮询模式,可以配合RDMA发挥出后端存储的最佳性能。
综上,我们实现了云盘的全面优化:使用SPDK VHost代替QEMU,实现虚机到存储客户端的数据零拷贝;使用高性能RDMA作为后端存储的通信协议,实现收发包卸载到硬件,使得RSSD云盘的延迟降低到0.1毫秒,体验几乎和本地盘一致;存储引擎由SPDK代替libaio,高并发下依然可以保持较低的时延。再配合全25G的底层物理网络,使RDMA-SSD云盘的随机读写性能达到最佳,实现120万IOPS。
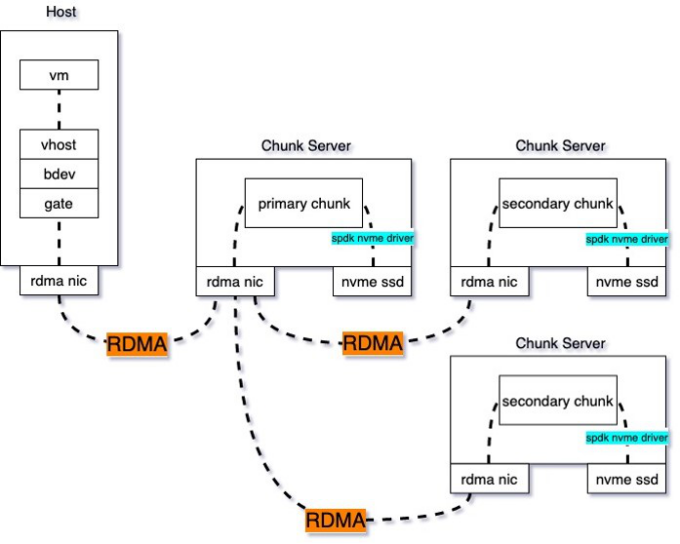
图:RDMA-SSD云硬盘原理图
三、内核调优:产品综合性能提升10%
提起云主机,更多的会想到计算、存储、网络,甚少有人关注内核。然而,内核构建是一个云主机的核心工作,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统等,对云主机性能和稳定性至关重要。
未优化之前,我们对云主机中特定业务场景进行了基准性能测试。在测试过程中,利用perf、systemtap、eBPF等多种动态跟踪技术,在Host内核、KVM和Guest内核等不同观测层级上,对影响性能的因素进行了指令级别的分析。
在此基础上,我们针对性的进行了内核增强和优化工作。
■ CPU增强&漏洞修复
我们在QEMU和KVM中添加了Intel 新一代Cascade Lake虚拟CPU的支持,相比上一代Skylake,增加了clflushopt、pku、axv512vnni等指令集,在特定场景下性能表现更加出色。此外,针对CPU漏洞方面,我们利用硬件解决了Meltdown,MDS,L1TF等漏洞,同时针对Spectre_v2补丁添加了代价更小的Enhanced IBRS增强修复机制,在虚拟化层面对漏洞进行了修复。
最后,我们将硬件修复能力赋予”快杰”,使得云主机可以避免Guest内核在软件层面修复安全漏洞,消除这方面引起的性能开销和业务指标下降。
■ CPU对内存读写能力的优化
针对CPU对内存读写能力的优化,我们主要从两方面来实现。
首先我们基于硬件内存虚拟化(Intel EPT),添加了定制化大页内存的支持,从而避免了之前内存虚拟化中存在的管理器/分配器开销、换页延迟等,极大减少了页表大小和TLB miss,同时保证云主机内存与其他云主机、系统软件间相互隔离,避免影响。
其次,我们增强了NUMA亲和性的使用。众所周知,跨节点访问内存的延迟远远大于本地访问所产生的,针对该问题,我们通过合理的资源隔离和分配,使云主机的VCPU和内存绑定在同一个节点。此外,对于大型云主机可能存在单个节点资源不够的情况,我们将云主机分配在两个节点,把节点的拓扑结构暴露给Guest内核,这样云主机可以更方便的利用NUMA特性对关键业务进行调度管理。
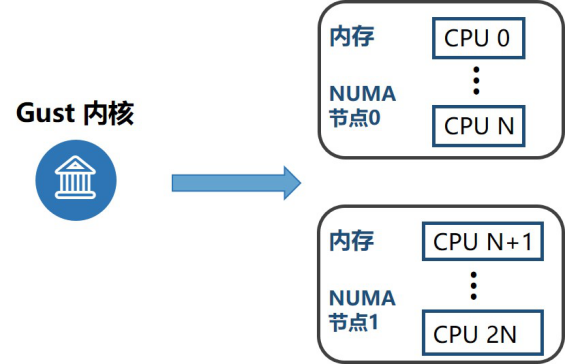
图:NUMA亲和性的使用
■ Host内核&KVM优化
结合性能分析数据,我们对Host内核和KVM也进行了大量的优化。
在VCPU调度方面,我们发现CFS调度器会在临界区内使用时间复杂度为O(n)的算法,导致调度器开销过高、Guest计算时间减少及调度延迟增大,我们在CFS中修复了这一问题。
此外,在Host/Guest上下文切换过程中,我们发现某些寄存器的上下文维护代码会引入一定开销,因此在保证寄存器上下文切换正确性的同时,我们也去掉了这些维护代码引起的开销。
在云主机运行过程中,会产生大量的核间中断(IPI),每次IPI都会引起VMExit事件。我们在虚拟化层引入了两个新的特性:KVM-PV-IPI和KVM-PV-TLB-Flush。通过KVM提供的Send-IPI Hypercall,云主机内核可以应用PV-IPI操作消除大量VMExit,从而实现减少IPI开销的目的。在云主机更新TLB的时候,作为发起者VCPU会等待其它VCPU完成TLB Shootdown,云主机内核通过PV-TLB-Flush极大减少等待和唤醒其它VCPU的开销。
以上是一些比较重要的优化工作,其它内核、KVM、QEMU功能增强和稳定性提升等内容不再赘述。总体评估下来,通过内核调优,可帮助”快杰”实现10%以上的综合能力提升。
四、三大应用场景分析
基于强大的性能,“快杰”能够轻松满足高并发网络集群、高性能数据库、海量数据应用的使用场景。我们分别选取了Nginx集群、TiDB、ClickHouse数据库三个应用场景,下面来看一下”快杰”的表现:
■ 场景1::搭建Nginx集群,突破网络限制
爱普新媒是一家从事广告DSP(Demand-Side Platform,需求方平台)业务的公司,由于业务需求,爱普新媒对于网络集群的高并发要求非常高。最终,爱普新媒选择使用“快杰”搭建Nginx集群,作为API网关对其终端客户提供服务。
Nginx是一款轻量级HTTP反向代理Web服务器,根据Nginx官网的数据,Nginx支持了世界上大约25%最繁忙的网站,包括Dropbox,Netflix,Wordpress.com等。其特点是并发能力强,而“快杰”进一步提升了其并发能力。
“快杰”突破了云主机之前的网络限制,如下图,“快杰”的应用使得爱普新媒原有集群内主机可以大幅度减少,并且在相同服务能力下,成本减半。
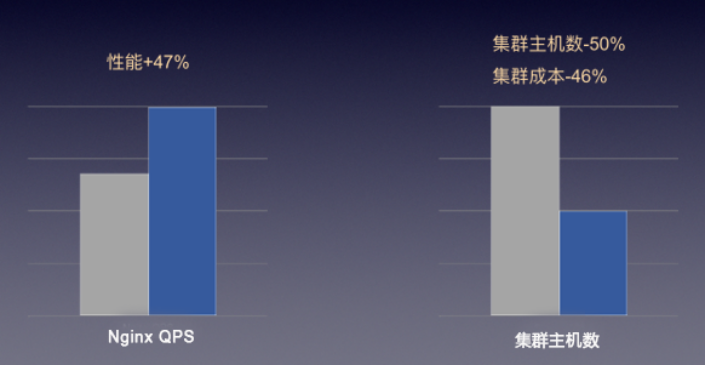
图:“快杰”在高并发网络集群场景中的表现
■ 场景2: 搭建TiDB,突破IO性能瓶颈
PingCAP的TiDB是一款流行的开源分布式关系型数据库,为大数据时代的高并发实时写入、实时查询、实时统计分析等需求而设计,对IO性能的要求无疑非常高。通常,TiDB要求底层使用NVMe SSD本地磁盘支撑其性能,但快杰云主机通过RSSD云盘即可满足TiDB的高要求,其性能得到PingCAP工程师的实测认可。
目前,已有不少UCloud客户使用快杰云主机搭建TiDB,突破了之前的数据库性能瓶颈。
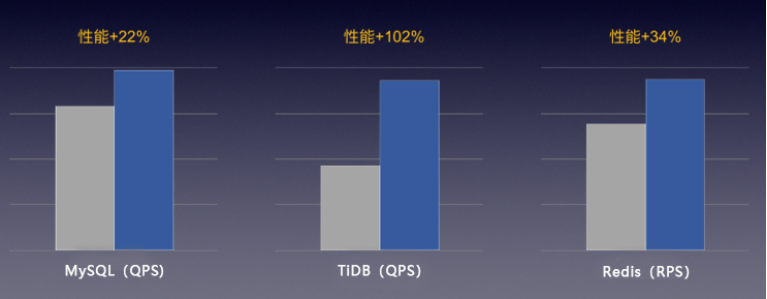
图:“快杰”在高性能数据库场景中的表现
除了TiDB,“快杰”实测能有效提升各类数据库的性能表现20%以上。
■ 场景3: 搭建ClickHouse,2倍提升数据吞吐量
TT语音是一款专门为手游玩家服务的语音开黑工具,由于业务要求需将APP埋点数据收集到大数据集群中分析。TT语音采用“快杰”搭建ClickHouse数据库作为整个大数据集群的核心,对比之前,每日增量达到8亿条记录。
除了ClickHouse场景,“快杰”还可以对大数据生态进行全方位的优化,如下图,数据吞吐提升高达2倍,助力企业大数据业务发展。

图:“快杰”在大数据应用场景中的表现
结语
基于“软硬件协同设计”的理念,“快杰”在网络增强2.0、RSSD云盘优化、内核调优等方面做到了技术的大幅进阶,为用户带来了突破性的云主机性能提升。在“快杰”的技术进阶路上,技术的更迭与升级可以用语言描述出来,但是技术实现的背后却代表了UCloud为用户创造核心价值的坚持与追求。