
按:12月3日,为期两天、由百易传媒(DOIT)主办的2019中国数据与存储峰会(DATA & STORAGE SUMMIT)在北京盛大开幕,与会专家对新一代关键存储技术趋势及数据创新应用进行了热议,大家一致认为数据智能将成为数字产业发展的关键推动力,驱动中国和企业数字化转型。
峰会第二天,共举行了十场分论坛。在“分布式存储与应用论坛”上,华为OceanStor分布式存储营销总监王飞应邀发表了主题演讲,主题是:“面向智能时代,打造海量多样性数据底座”,谈到了海量数据形势下华为的对策以及新一代智能分布式存储OceanStor D系列解决方案的优势等话题,并结合行业成功案例讲述了OceanStor分布式存储如何创新引领,加速行业数字化转型。
以下内容根据速记整理。
王飞:各位来宾上午好!我现在负责OceanStor分布式存储的上市和营销,今天非常高兴来到分布式存储的分论坛做一个主题的分享。

图:华为OceanStor分布式存储营销总监王飞
大家有没有注意到,今天大会所有分论坛的议题,只有分布式存储这个分论坛议题从上午下午都有贯穿整天满满一天,其他的分论坛都是半天。这从侧面反映了当前分布式存储在业界火热的程度。
云和AI时代,数据迎来海量增长
分布式存储整个产业近几年快速的发展和云计算在企业产生普及密不可分,云计算把企业各种类型的数据割裂的数据给整合到一起,必须要一个高扩展性存储架构支撑。
面向未来大数据时代智能时代,分布式存储面临哪些挑战,华为在这个领域我们是怎么做的?今天和大家简单聊一聊。
刚才讲了云计算把企业割裂的业务和离散的数据整合到一起,大数据和AI这些新的生产工具的数据价值被企业重新认可,又会带来新一轮数据增长高潮。
华为GIV报告显示,每年数据增量全球数据增量从2018年32ZB, 2025年增长到180ZB,海量数据增长来源于哪里?
一是5G,2019年整个通信行业最热的话题一定是5G,在中国5G网络已经商用了,全球其他TOP运营商也开始了部署,5G通过高带宽、低时延、多接入的能力,让万物互联成为可能,而海量的连接,给运营商的业务和数据带来十倍以上的压力。
二是超高清产业。我们知道,4K已经走进了寻常百姓家,今年双十一我想买75寸的电视,当然是4K的,发现现在75寸4K电视,只需要 3999元,侧面说明了4K这个产业其实已经普及了。今年春晚央视通过4K+5G进行了春晚直播,给我们带来不一样的体验,华为OceanStor分布式存储也参与了央视高清制作岛的建设。而8K的标准也已经基本建立,今年上半年华为和中国联通发布了8K+5G技术白皮书,8K视频每一个小时数据量达到10TB,是1080高清的40倍以上。
自动驾驶是当前整个制造行业、汽车行业最火的话题,在自动驾驶汽车研发过程中,车企需要部署几台最多几十台的测试车辆开展路测,车上遍布各种激光雷达、毫米波雷达和视频摄像头,实时采集各种路况信息,这些数据汇总到数据中心进行AI训练,每一辆车每天采集的数据可能达到30到60TB,一个汽车要商用,通常需要2000万公里路测数据,整个数据量可以达到EB级。
最后看一下基因测序,二十世纪人类有三大工程,第一个是曼哈顿原子弹工程,第二个阿波罗登月工程,第三类人类基因组工程。从1990—2003我们花了13年时间,很多国家参与,耗资30亿美元,得到了3TB的人类基因组测序数据,这还不是所有物种里面最大的,小麦水稻全基因组比人类基因组更大。现在基因测序不需要30亿美元那么多,几百美元就可以做一次基因测序。华大基因桌面级的基因测序级就是一个PC的大小,价格大概十多万元,他们最先进的基因测序仪每天日产数据量可以达到6个TB,一年下来就是两个PB,这仅仅是一台基因测序仪产生的数据量。
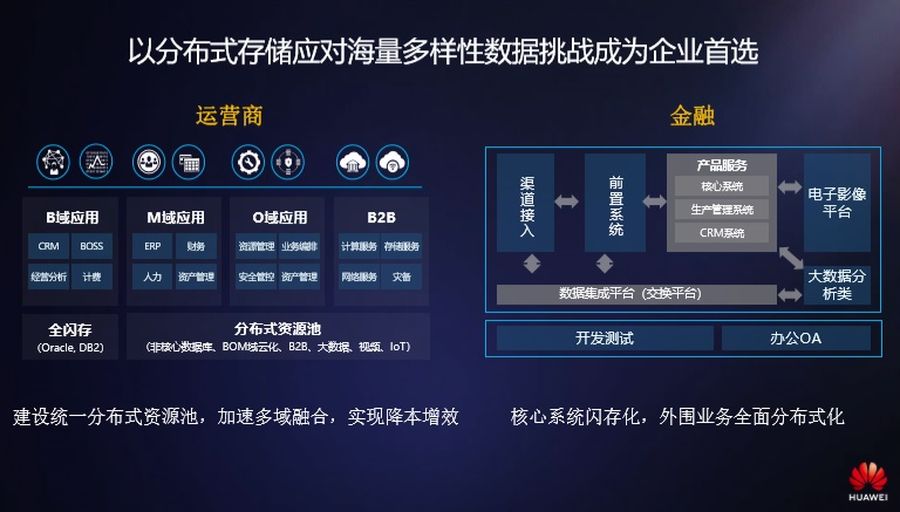
以分布式存储应对海量多样性数据挑战成为企业首选
再来聊一聊数据多样化的问题。
随着企业数字化转型深入,越来越多业务如雨后春笋一样出现,带来业务的多样性数据多样性,各种不同类型的数据同时存在,以前对企业来说最核心的数据是以数据库为代表的传统结构化数据,比如说企业的财务系统、计费系统、客户关系管理系统等等。其实企业还有80%数据是非结构化数据,这些数据以文档、音视频形式存在。比如说视频监控、一些系统设备运行的日志,这些数据被认为是价值相对来说比较低的。海量多样性的这些数据,如何去有效的承载,也是企业未来面对的问题。
1.数据存储,全生命周期每bit成本最优
针对于海量多样性数据的挑战,业界各个行业怎么应对的?这里选了两个比较典型的,一个运营商一个金融。大家可以发现一个共同点:在他们核心的业务系统里,基本上继续走着高端路线,逐渐走向闪存,非核心外围的系统,分布式存储已经成为首选。比如说运营商BOM非核心业务,承载资源池里采用这种分布式存储承载,还有金融渠道接入业务、票据影像业务,需要弹性规模扩展。
讲到这里,当前业界大家争论比较多的是关于集中式存储和分布式存储定位的问题。
集中式存储分布式存储某些场景确实存在交叉的,但产品定位各有侧重,集中式存储定位在以数据库为代表的关键业务,然后分布式存储更多考虑非关键的非结构化的数据。传统这种关键业务分布式存储能不能承载,要是能力有也可以做,并不意味着这是主要方向。
我觉得大家还是应该把场景给区分开。
分布式存储解决企业存储扩展性问题,让企业有能力去把这些海量的数据存下来,还有一个关键的问题没有解决,就是企业有没有意愿存这么多数据,背后最关键的因素就是数据存储的成本问题。不解决成本问题,所有的扩展性都是空谈,因为在当前,绝大多数企业来说,他们IT系统更多是一个成本中心而不是利润中心,成本中心必须考虑建设成本维护成本。
2.数据挖掘,融合分析让每bit价值最大
基于成本的压力,很多数据企业没有办法长期保存,原来想要保存六个月,成本降到三个月,很多数据直接丢弃了。所以我觉得分布式存储这个产业下一阶段如何降成本。怎么降?两个方面,第一个开源第二个节流。
先讲一下节流。降低数据生命周期的存储成本,让成本更优。首先解决的问题就是多样性数据存储问题,以前要存一种设备一种协议,到一种设备多种协议,我们通过一套设备一个架构支撑这种不同类型,同时降低数据中心采购和维护的成本。其实现在业界三核心四核心讲的比较多,很多企业落地了相应的产品和能力。
第二个要关心的就是承载企业更高的业务能力。以前绝大多数客户对分布式存储的印象是低成本、低性能、低可靠。这个现象我们必须要去扭转,低成本高性能高可靠,或者说用最合适的成本解决用户承载不管是认为可靠性比较低,性能比较低的业务,还是承载可靠性高性能高数据满足需求。
数据增长带来的海量设备的问题,如何更高效管理,用自动化手段解决,降低企业运维成本也是带来的价值。
下一个,开源。我们知道,这个开源不是软件开源,而是通过各种分析挖掘,让数据更多体现价值,当数据有了价值之后,企业才有意愿去存更多的数据。
数据湖建设是很多企业新的数据基础建设的方向,分布式存储作为数据湖的底座支撑,未来需要做哪些事来让数据分析效率更高?我们认为有这三个方面。
第一,在数据多协议合一的前提下实现数据的互通,一个数据用对象存进来,大数据系统直接分析,用文件存进来,对象去读出,直接用于发布。一份数据多种用途,而不需要像原来在不同的协议不同的存储之间做数据的迁移,做数据的格式转换,这种方式使得我们分析效率大幅度提升。
第二,数据库存算融合,我们知道,数据库有一些算子,所做的操作把数据从存储面读出来读到计算里面,有一读一写的过程;我们将这个算子下移到了存储层实现,数据库调用存储接口,存储内部进行操作,反馈回结果就可以了,这是数据库算子下推。
第三,大数据存算分离。这不是新的概念。为什么前几年没有普及起来,一个很大的问题,原来企业大数据的建设还没有普及,即使到了现在,运营商,公安,金融,这三个行业的大数据有非常广泛的应用,而其他行业还是零零星星的应用,随着大数据普及,以前企业大数据平台也是存在孤岛,各个平台之间数据割裂的,没有办法做全量分析,导致数据分析效率不高。通过分布式存储提供原生大数据接口,支撑所有大数据放在一个资源池里面,任何大数据平台都可以调用,这种方式,可以实现数据全量的分析,不需要倒来倒去,也是数据价值提升的一个手段。
OceanStor D系列:新一代智能分布式存储
来看看华为怎么做的。
今年五月份,华为面向全球发布了FusionStorage智能分布式存储,这也是我们分布式存储一直以来的名字。从明年1月1日开始华为分布式存储将改名为OceanStor分布式存储,后续华为所有存储品牌会统一归到OceanStor,这个品牌下面有集中式存储有分布式存储,这是我们战略上的变化,对我们产品规划其实没有任何影响。
分布式存储怎么对应刚才的两点提升的效率,第一个是Storage for AI,通过智能的算法,通过协议的智能融合,打破数据孤岛,汇聚数据激发价值。另一方面是AI in Storage,把AI融入分布式存储全生命周期的智能管理,让管理更高效,最终实现极简融合极速体验极致效率。
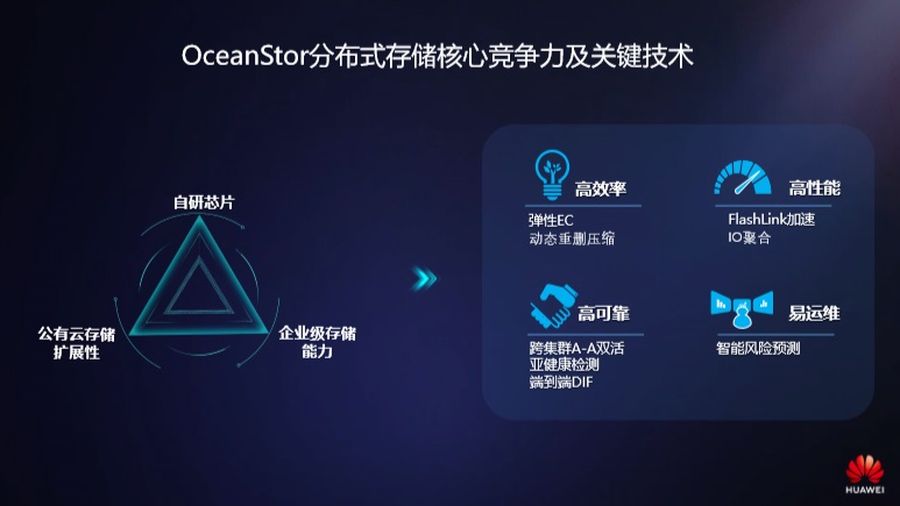
OceanStor分布式存储核心竞争力及关键技术
华为分布式存储的核心竞争力在于三个方面。
一是我们做公有云,分布式存储为我们的公有云提供块、对象、文件和大数据服务,天然具备有公有云所需要的海量扩展能力。二是企业级的存储能力,华为从十多年前进入存储领域,早已经是中国区领头羊,现在分布式存储也做到国内的市场连续多年第一的位置。在集中式存储里面有很多高级的能力,比如说可靠性、性能、可维护性相关的。这些能力我们都继承下来,平滑移植到分布式存储里。三是华为自研的芯片,我们的鲲鹏处理器融入到分布式存储硬件里。
可能有人有疑问,自研的芯片就是好的吗?未必,需要看软件和硬件做了哪些不一样的内容?我们常用的算法,比如压缩、DIF算法等,我们把算法逻辑做到CPU里,通过硬件逻辑实现,效率时延比通用高很多。在硬件层面,我们有自己的X86服务器,但鲲鹏处理器架构是我们主推的产品。
讲到这里,我顺便提一下现在业界争论比较多的,分布式存储到底是软硬结合还是软硬分离。

其实从最早分布式存储,或者软件定义存储,这个理念从互联网来的基于标准这些服务器,通过开源软件自己构建分布式存储服务,这个对互联网适用的,对企业客户适不适用?企业客户更关注可维护性,从这个角度看,我觉得是软硬一体的架构更适合,软硬分离或者基于开源的组件自己去做很难实现的,这是华为的观点。我们也会坚定走软硬一体的路线。
基于这三方面核心竞争力,我们有一些关键的技术,高效率的弹性EC,动态重删压缩,然后是高性能,FlashLink加速,高性能IO聚合,可靠性方面,跨集群的A-A双活与亚健康检测端到端DIF,以及易运维智能风预测。
首先弹性EC。EC是分布式存储通用的技术,同样的可靠性情况下,利用率可以增加很多,三副本利用率33%,通过EC,利用率可以达到66%,甚至可以做到更高。华为EC做到22+2,利用率高达91%。把EC利用率做高不是大的问题,关键一个问题需要解决,EC会带来的一个写惩罚的问题,EC高性能下降越快,如何在性能和磁盘之间的均衡。我们现在是通过弹性EC可以实现相同可靠性下EC的性能与副本持平,在利用率提升下性能还不降,这是我们独特的地方。记得今年三月份的时候深圳举办的多IT分布式存储的分会里面,也有人质疑,你不可能做到的。我们也在向大家邀请,大家有质疑的,可以到项目里面测试,到华为实验室一起测,这是一个开放的态度。
第二个是业内首个数据中心级双活:为关键业务提供99.9999%可靠性。数据真双活,是华为集中式存储两地三中心的能力移植过来的,可以实现100公里两毫秒集群的双活,现在我们在实际部署辽宁移动同城十七公里数据中心并且商用,运行到分布式存储上面来的。
第三,端到端DIF。如果存储服务器出现了数据静默错误,会导致了文件系统源数据损坏,对于初创企业丢失了创立以来业务数据和业务数据,基本上公司就毁了。数据静默错误或者对数据一致性不重视产生的教训由此可见。我们在三个方面实现端到端DIF,第一个在线校验,写入磁盘的检查校验位。磁盘本地会做周期性的校验,在业务量比较低的情况下,避免数据静默错误和跳变。在数据读出的时候主机还会做一次检验,确保读出数据和磁盘数据一致的,数据出现不一致怎么办,优先通过本地副本、EC分片恢复,本地副本和分片都坏了,通过异地容灾中心副本做恢复。
除了节点数可以增加,容量可以增加,针对对象存储,华为还关注能够承载对象的数量,华为做到单桶1000亿对象。性能衰减比较快,也是业界的难题,华为解决了这个难题,可以让通常的业界比较多的单桶千万级到十亿级,扩展到千亿级,很多地方有应用场景的,某大城市交警的卡口,有20000个交通摄像头,还有像金融、车联网,按照国家规定网联汽车每15秒钟上报一次认证信息,未来数百万上千万辆网联汽车数据每15秒上报,这个量有多大。在实现数据对象增加的同时,我们还实现性能不降的,性能稳定的,这个我们经过第三方机构测评,有真实的数据和报告。
四是智能的风险预测,这不仅仅是依赖于华为存储本地,也和云端的能力相结合,华为有超过两个P的特征数据,以及1000家业务场景,能够和本地存储的数据进行联动,在客户允许的情况下,把这些数据收上来做数据分析,可以提前14天发现可能出现硬盘的故障风险,对于性能的潮汐分析,能够提前60天识别性能瓶颈,还有精准的分析,提前365天预测存储的趋势,这个是我们AI方面的积累。
大数据存算分离方案:改变规则,重塑数据价值
前面讲的是技术,接下来讲一个方案,大数据存算分离的方案。通常大家心目中大数据就是一个服务器既有计算又有存储,计算存储离的近,确实是一个优势,但是我们大数据应用中发现,企业大数据业务计算存储不是均衡的,像运营商日志留存系统,这些数据存进来只是偶尔查询,计算需求非常低,存储需求非常高,存储不足的时候扩一台服务器,存储扩了计算也跟着扩,对资源系统很大的消耗,因此我们要做大数据的存算分离,华为提供了原生的接口,把大数据接口分出来。
存算分离有什么好处?最直观的计算不够扩计算,存储不够扩存储非常灵活,不会造成资源浪费,分离之后计算资源可以做云化。
以前讲大数据云化不能做,现在分离之后计算可以做虚拟化可以做云化,实现一些自动化服务化的能力,大幅度提升大数据的效率。
通过专业的存储承载,华为大数据的存储,刚才讲了我用EC做,EC磁盘可以达到91%,原来采用本地的HDFS,通常使用三副本利用率只有33%,即便现在开源也推出了EC,EC只能做到66%,基本上不能商用,这也是存算分离带来另外一个好处。
刚才前面也提到了,企业因为历史原因,大数据平台建设割裂的,有很多数据孤岛,通过华为大数据统一资源池,所有数据都放在资源池里面,任何平台都可以调用,通过这种开放方式大数据资源整合,大数据管理也简单,大数据使用也更加简单。
OceanStor分布式存储创新引领,加速行业数字化转型
无论是政府、金融、运营商、大企业,分布式存储都有非常多的应用,我这里还没有列举完,只是比较典型的比较重要的。
分布式存储的应用场景三个案例。
第一个中国移动辽宁分公司。辽宁移动和我们合作非常早,从2014年开始第一次合作在开发测试环节应用分布式存储,现在分布式存储已经达到了10多个PB。最新今年把最核心的BOSS系统迁移到分布式存储。还有经营分析,时延从九毫秒降低到两毫秒,提升了五倍,原来做一次分析需要60个小时,现在只要10个小时。经营分析对企业的价值是可以及时调整策略。第二个是招商银行,招商银行和我们合作比较早,2015年开始,开发测试环节后来分布式存储替代,VDI,数据库大数据,今年在大数据场景合作,使用存算分离,精准营销,提供四种存储类型。还有这样一个大数据存算分离的案例,新加坡S公司以前使用开源Hadoop承载研发的日志的数据。原来是需要15个机柜,EC利用率仅66%,通过OceanStor分布式存储,我们把计算和存储分开,计算只需要两个机柜,存储通过两个方式实现节省,第一个方式EC利用率提升91%;第二是使用36盘位替代,机柜数节省了46 %,单机柜节省64%。

以创新赢得认可,打造海量多样性数据底座
今年5月份,华为在东京Interop获得了金奖,了解的人都知道这是IT界奥斯卡一个奖,这个奖非常来自不易。第二是2018年中国区分布式存储市场份额NO1,2019年结果还未最终出来,华为应该也是第一。第三个今年的中国移动的三个集采,分布式文件集采,分布式块集采,还有NFV总包都获得了第一。
未来我们希望能够更多的和产业界同仁持续拓展大分布式存储的产业,通过技术创新去赢得客户的认可,一起携手打造分布式存储产业,一起打造智能时代海量数据性底座,感谢大家。

编后:本次2019中国数据与存储峰会(DATA & STORAGE SUMMIT)为期两天,包含主论坛、CIO高峰对话,以及大数据、闪存系统、分布式存储、第二存储与容灾备份、超融合与云存储、人工智能、数据创新与安全可控、容器创新与应用、SCM第五代存储与闪存控制器等十大主题论坛,超过100场的专业知识分享。初步统计,本届峰会吸引了来自政、企、产、学、研、媒体等各方参会者约2000人,在线直播观看观众再创新高,超过10万余人次。






