2019年12月16日-19日,英伟达GPU技术大会(GTC 2019,以下简称“大会”)在苏州金鸡湖国际会议中心举行,来自Amazon、FaceBook、腾讯、平安等诸多国内外知名企业机构的专家学者汇聚一堂,就人工智能、深度学习、医疗科学、智慧金融、边缘计算等领域展开深度讨论。微众银行AI团队于19日在【智慧金融】分会场上联合星云Clustar发表了《GPU在联邦机器学习中的探索》主题演讲,详细介绍了其GPU加速联邦学习的研究成果。

伴随着计算力、算法和数据量的巨大进步,人工智能迎来第三次发展高潮,开始了各行业的落地探索。然而,在“大数据”兴起的同时,数据分散的情况也越发明显,“数据孤岛”现象广泛存在。随着政策法规的逐渐完善和公众隐私保护意识的加强,隐私安全、数据保护等原因限制着数据不能轻易互通,如何在保护数据隐私的前提下实现行业协作与协同治理,是大数据时代人工智能行业应用的一大难题。
多方获益,联邦学习破解“数据孤岛”难题
“联邦学习”(Federated Learning)指的是在满足隐私保护和数据安全的前提下,设计一个机器学习框架,使各个机构在不交换数据的情况下进行协作,提升机器学习的效果。其核心就是解决数据孤岛和数据隐私保护的问题,通过建立一个数据“联邦”,让参与各方都获益,推动技术整体持续进步。大会上,来自微众银行AI部门的高级算法工程师黄启军也为观众展示了联邦学习的落地案例之一——视觉横向联邦学习系统。
黄启军提到,在目标检测领域,已标注数据是非常珍贵的资源,各家公司一般都有各自不同场景的标注数据,但这些数据相对散乱,如想利用其它公司已标注好的数据模型来建立更优模型,只能通过拷贝聚拢数据,但这种行为不符合GDPR、《数据安全管理办法》等法律规范。而引入横向联邦学习机制以后,个体可以在本地设备中直接标注数据,无需上传。本地模型的训练数据标注完成后,客户端将自动加入联邦,等待进行训练,当有两台设备进入到等待训练状态时,则开始进行联邦学习训练模式。
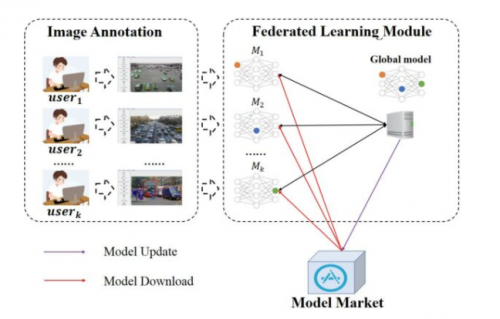
视觉横向联邦学习系统示意
这一案例真实展现了联邦学习技术的价值,相比于单点模型,联邦学习使得本地设备的mAP大幅提升,同时Lossless更加稳定。mAP平均提升15%的数据显示,整体上联邦学习远比单点模型效果更佳。
深度创新,GPU加速联邦学习再升级
作为一门具有前景的新兴技术,联邦学习为了完成隐私保护下的机器学习,使用了很多与传统机器学习不一样的方法,也因此迎来了诸多新挑战。在会上,黄启军也分享了微众银行AI部门携手星云Clustar突破的联邦学习计算三大难题:
首先就是大整数运算问题,传统机器学习一般使用的是32-bit的基本运算,这些基本运算一般都有芯片指令的直接支持,而联邦学习中的Paillier/RSA算法依赖的是1024或2048-bit 甚至更长的大整数运算,但现实情况是,GPU流处理器并不直接支持大整数运算。面对这一情况,双方基于分治思想做元素级并行,通过递归将大整数乘法分解成可并行计算的小整数乘法,从而实现“化繁为简”,间接完成GPU流处理器的大整数运算。
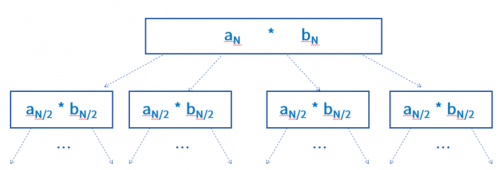
通过递归将大整数乘法分解成可并行计算的小整数乘法示意
其次,大整数运算中多是模幂、模乘等复杂运算,即ab mod c (a,b,c均为N比特大整数),而GPU做模幂等运算的代价极大,传统的朴素算法会优先计算ab,再计算值对c取模,这一算法的缺点是复杂度高达O(2^N),且中间乘积结果很大。而单一的平方乘算法则是通过ak = (ak/2)2 = ((ak/4)2)2实现,虽然复杂度下降至O(N),且中间结果大小不超过c,但因为需要做2N次取模运算,GPU在此项上花费时间极高。而双方摘取平方乘算法优势,并加入蒙哥马利模乘算法计算模乘,就完全避免了取模运算,大幅度降低了GPU的消耗。
最后,在分布式计算时,联邦学习不止涉及数据中心内网传输,也有广域网传输的场景,且密文数据体积要增加几十倍,传输的次数也是传统机器学习的几倍,双方通过RDMA网络技术加上自研的动态参数聚合模型技术以及机器学习专业的网络传输协议,对联邦学习在数据中心内通信场景以及跨广域网通信场景都进行了很好的性能优化。
走在前沿,联邦学习推动AI行业大变革
联邦学习近年来在学术研究、标准制定和行业落地等方面发展迅速,有望成为下一代人工智能协同算法和协作网络的基础,全球范围内也正在掀起“联邦学习”的热潮。从GPU加速联邦学习这样的底层技术研究,到IJCAI 2019首届联邦学习国际研讨会等学术交流,再到IEEE标准制定推动行业规范化,联邦学习在人工智能领域渐露峥嵘,在该领域的影响力显著提升。而在工具层面,也有诸多企业机构开展研发,如微众银行AI团队开源的全球首个工业级的联邦学习技术框架 Federated AI Technology Enabler(FATE),不仅提供一系列开箱即用的联邦学习算法,更重要的是给开发者提供了实现联邦学习算法和系统的范本,使大部分传统算法可以经过改造适配到联邦学习框架中,从而快速加入联邦生态。
此外,在行业应用落地方面,联邦学习也扇动了一股“变革”的飓风:在金融领域,基于该技术的多家机构联合风控模型能更准确地识别信贷风险,联合反欺诈。多家银行建立的联邦反洗钱模型,能解决该领域样本少、数据质量低问题,在微众银行的实践中AUC显著提升12%。
在智慧零售领域,该技术能有效提升信息和资源匹配的效率。例如,银行拥有用户购买能力的特征,社交平台拥有用户个人偏好特征,电商平台则拥有产品特点的特征,联邦学习能在保护三方数据隐私的基础上进行联合建模,为用户提供更精准的产品推荐等服务,从而打破数据壁垒,构建跨领域合作,经应用实践,采购备货准确率提升可达21.4%。
联邦学习是大数据使用的未来范式,也是破解数据隐私保护难题的新思路。人工智能不仅是一个工具,更应该是让社会更加公平美好的强大推动力。联邦学习势必将在未来助力更多行业、更多场景发挥无限潜能,推动AI普惠的实现。而作为致力于在全球范围内引领和推动数据隐私保护下的AI协作生态建设的微众银行AI团队,也必将与诸多企业机构一起,共建行业更美好的未来。