人工智能的最新趋势是,更大的自然语言模型可以提供更好的准确性,但是由于成本、时间和代码集成的障碍,较大的模型难以训练。微软日前开源了一个深度学习优化库 DeepSpeed,通过提高规模、速度、可用性并降低成本,可以在当前一代的 GPU 集群上训练具有超过 1000 亿个参数的深度学习模型,极大促进大型模型的训练。
同时,与最新技术相比,其系统性能可以提高 5 倍以上。

根据微软的介绍,DeepSpeed 库中有一个名为 ZeRO(零冗余优化器,Zero Redundancy Optimizer)的组件,这是一种新的并行优化器,它可以大大减少模型和数据并行所需的资源,同时可以大量增加可训练的参数数量。研究人员利用这些突破创建了图灵自然语言生成模型(Turing-NLG),这是最大的公开语言模型,参数为 170 亿。
ZeRO 作为 DeepSpeed 的一部分,是一种用于大规模分布式深度学习的新内存优化技术,它可以在当前的 GPU 集群上训练具有 1000 亿个参数的深度学习模型,其吞吐量是当前最佳系统的 3 到 5 倍。它还为训练具有数万亿个参数的模型提供了一条清晰的思路。
ZeRO 具有三个主要的优化阶段,分别对应于优化器状态、梯度和参数分区。
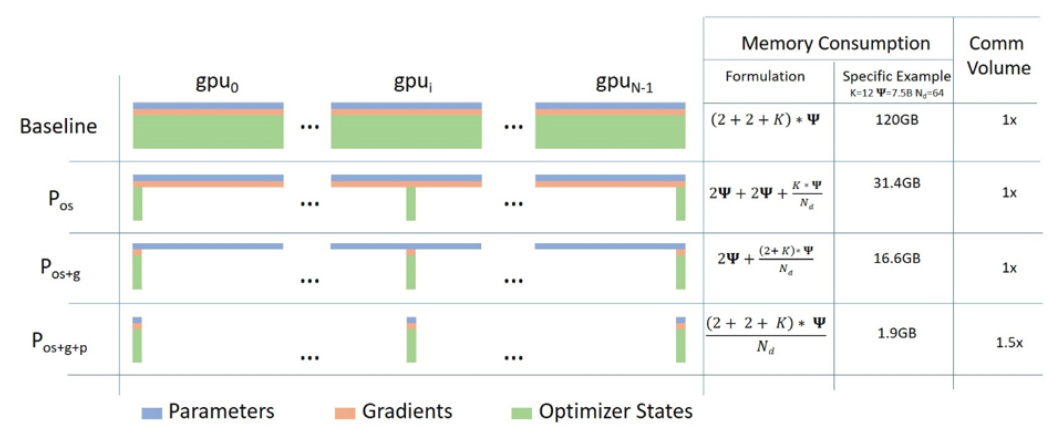
ZeRO 克服了数据并行和模型并行的局限性,同时实现两者的优点,它通过跨数据并行进程将模型状态划分为上图所示的参数、梯度和优化器状态分区,而不是复制它们,从而消除了数据并行进程之间的内存冗余。在训练期间使用动态通信规划(dynamic communication schedule),在分布式设备之间共享必要的状态,以保持数据并行的计算粒度和通信量。
目前实施了 ZeRO 的第一阶段,即优化器状态分区(简称 ZeRO-OS),具有支持 1000 亿参数模型的强大能力,此阶段与 DeepSpeed 一起发布。
DeepSpeed 与 PyTorch 兼容,DeepSpeed API 是在 PyTorch 上进行的轻量级封装,这意味着开发者可以使用 PyTorch 中的一切,而无需学习新平台。此外,DeepSpeed 管理着所有样板化的 SOTA 训练技术,例如分布式训练、混合精度、梯度累积和检查点,开发者可以专注于模型开发。同时,开发者仅需对 PyTorch 模型进行几行代码的更改,就可以利用 DeepSpeed 独特的效率和效益优势来提高速度和规模。
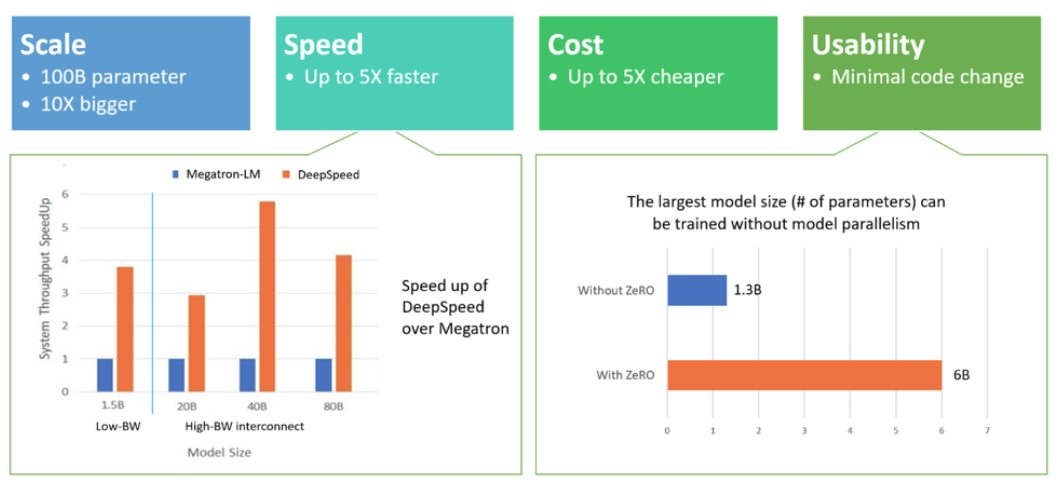
DeepSpeed 在以下四个方面都表现出色:
- 规模:目前最先进的大型模型,例如 OpenAI GPT-2、NVIDIA Megatron-LM 和 Google T5,分别具有 15 亿、83 亿和 110 亿个参数,而 DeepSpeed 的 ZeRO 第一阶段提供系统支持,以运行多达 1000 亿个参数的模型,这是比当前最先进的模型大 10 倍。未来计划增加对 ZeRO 第二和第三阶段的支持,从而提供高达 2000 亿个乃至数万亿个参数的模型的能力。
- 速度:在各种硬件上,目前观察到的吞吐量比当前最先进技术高出 5 倍。例如,为了在 GPT 系列工作负载上训练大型模型,DeepSpeed 将基于 ZeRO 的数据并行与 NVIDIA Megatron-LM 模型并行相结合,在具有低带宽互连的 NVIDIA GPU 集群上(没有 NVIDIA NVLink 或 Infiniband),与仅对具有 15 亿参数的标准 GPT-2 模型使用 Megatron-LM 相比,DeepSpeed 将吞吐量提高了 3.75 倍。在具有高带宽互连的 NVIDIA DGX-2 集群上,对于 20 至 800 亿个参数的模型,速度要快 3 到 5 倍。这些吞吐量的提高来自 DeepSpeed 更高的内存效率以及使用较低程度的模型并行和较大的批处理量来拟合这些模型的能力。
- 成本:提高吞吐量意味着大大降低训练成本,例如,要训练具有 200 亿个参数的模型,DeepSpeed 需要的资源是原来的 3/4。
- 易用性:只需更改几行代码即可使 PyTorch 模型使用 DeepSpeed 和 ZeRO。与当前的模型并行库相比,DeepSpeed 不需要重新设计代码或重构模型,它也没有对模型尺寸、批处理大小或任何其它训练参数加以限制。对于参数多达 60 亿的模型,可以方便地使用由 ZeRO 提供的数据并行能力,而无需模型并行。而相比之下,对于参数超过 13 亿的模型,标准数据并行将耗尽内存。ZeRO 第二和第三阶段将进一步增加仅通过数据并行即可训练的模型大小。此外,DeepSpeed 支持 ZeRO 支持的数据并行与模型并行的灵活组合。