按
在“机器翻译是如何炼成的(上)”的文章中,我们回顾了机器翻译的发展史。在本篇文章中,我们将分享机器翻译系统的理论算法和技术实践,讲解神经机器翻译具体是如何炼成的。读完本文,您将了解:
· 神经机器翻译模型如何进化并发展成令NLP研究者万众瞩目的Transformer模型;
· 基于Transformer模型,我们如何打造工业级的神经机器翻译系统。
2013年~2014年不温不火的自然语言处理(NLP)领域发生了翻天覆地的变化,因为谷歌大脑的Mikolov等人提出了大规模的词嵌入技术word2vec,RNN、CNN等深度网络也开始应用于NLP的各项任务,全世界NLP研究者欢欣鼓舞、跃跃欲试,准备告别令人煎熬的平淡期,开启一个属于NLP的新时代。
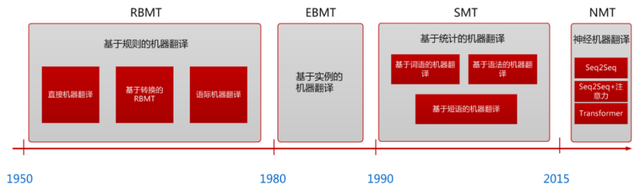
在这两年机器翻译领域同样发生了“The Big Bang”。2013年牛津大学Nal Kalchbrenner和Phil Blunsom提出端到端神经机器翻译(Encoder-Decoder模型),2014年谷歌公司的Ilya Sutskerver等人将LSTM引入到Encoder-Decoder模型中。这两件事标志着以神经网络作为基础的机器翻译,开始全面超越此前以统计模型为基础的统计机器翻译(SMT),并快速成为在线翻译系统的主流标配。2016年谷歌部署神经机器翻译系统(GNMT)之后,当时网上有一句广为流传的话:“作为一个翻译,看到这个新闻的时候,我理解了18世纪纺织工人看到蒸汽机时的忧虑与恐惧。”
2015年注意力机制和基于记忆的神经网络缓解了Encoder-Decoder模型的信息表示瓶颈,是神经网络机器翻译优于经典的基于短语的机器翻译的关键。2017年谷歌Ashish Vaswani等人参考注意力机制提出了基于自注意力机制的Transformer模型,Transformer家族至今依然在NLP的各项任务保持最佳效果。总结近十年NMT的发展主要历经三个阶段:一般的编码器-解码器模型(Encoder-Decoder)、注意力机制模型、Transformer模型。
下文将逐步深入解析这三个阶段的NMT,文中少量的数学公式和概念定义可能充满“机械感”,如果您在阅读过程感到十分费劲,那烦请您直接阅读第4部分,了解百分点如何打造自己的工业级NMT系统。
01 新的曙光:Encoder-Decoder模型
上文已经提到在2013年提出的这种端到端的机器翻译模型。一个自然语言的句子可被视作一个时间序列数据,类似LSTM、GRU等循环神经网络比较适于处理有时间顺序的序列数据。如果假设把源语言和目标语言都视作一个独立的时间序列数据,那么机器翻译就是一个序列生成任务,如何实现一个序列生成任务呢?一般以循环神经网络为基础的编码器-解码器模型框架(亦称Sequence to Sequence,简称Seq2Seq)来做序列生成,Seq2Seq模型包括两个子模型:一个编码器和一个解码器,编码器、解码器是各自独立的循环神经网络,该模型可将给定的一个源语言句子,首先使用一个编码器将其映射为一个连续、稠密的向量,然后再使用一个解码器将该向量转化为一个目标语言句子。
编码器Encoder对输入的源语言句子进行编码,通过非线性变换转化为中间语义表示C:
在第i时刻解码器Decoder根据句子编码器输出的中间语义表示C和之前已经生成的历史信息y₁,y₂,……,yᵢ-₁来生成下一个目标语言的单词:
每个yᵢ都依次这么产生,即seq2seq模型就是根据输入源语言句子生成了目标语言句子的翻译模型。源语言与目标语言的句子虽然语言、语序不一样,但具有相同的语义,Encoder在将源语言句子浓缩成一个嵌入空间的向量C后,Decoder能利用隐含在该向量中的语义信息来重新生成具有相同语义的目标语言句子。总而言之,Seq2Seq神经翻译模型可模拟人类做翻译的两个主要过程:
- 编码器Encoder解译来源文字的文意;
- 解码器Decoder重新编译该文意至目标语言。
02 突破飞跃:注意力机制模型
2.1. Seq2Seq模型的局限性
Seq2Seq模型的一个重要假设是编码器可把输入句子的语义全都压缩成一个固定维度的语义向量,解码器利用该向量的信息就能重新生成具有相同意义但不同语言的句子。由于随着输入句子长度的增加编解码器的性能急剧下降,以一个固定维度中间语义向量作为编码器输出会丢失很多细节信息,因此循环神经网络难以处理输入的长句子,一般的Seq2Seq模型存在信息表示的瓶颈。
一般的Seq2Seq模型把源语句跟目标语句分开进行处理,不能直接地建模源语句跟目标语句之间的关系。那么如何解决这种局限性呢?2015年Bahdanau等人发表论文首次把注意机制应用到联合翻译和对齐单词中,解决了Seq2Seq的瓶颈问题。注意力机制可计算目标词与每个源语词之间的关系,从而直接建模源语句与目标语句之间的关系。注意力机制又是什么神器,可让NMT一战成名决胜机器翻译竞赛呢?
2.2. 注意力机制的一般原理
通俗地解释,在数据库里一般用主键Key唯一地标识某一条数据记录Value,访问某一条数据记录的时候可查询语句Query搜索与查询条件匹配的主键Key并取出其中的数据Value。注意力机制类似该思路,是一种软寻址的概念:假设数据按照<Key, Value>存储,计算所有的主键Key与某一个查询条件Query的匹配程度,作为权重值再分别与各条数据Value做加权和作为查询的结果,该结果即注意力。因此,注意力机制的一般原理(参考上图):首先,将源语句中的构成元素想象成是由一系列的<Key, Value>数据对构成,目标语句由一序列元素Query构成;然后给定目标语句中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数;最后,可对Value进行加权,即得到最终的Attention数值。因此,本质上注意力机制是对源语句中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。一般性计算公式为:
在机器翻译中Seq2Seq模型一般是由多个LSTM/GRU等RNN层叠起来。2016年9月谷歌发布神经机器翻译系统GNMT,采用Seq2Seq+注意力机制的模型框架,编码器网络和解码器网络都具有8层LSTM隐层,编码器的输出通过注意力机制加权平均后输入到解码器的各个LSTM隐层,最后连接softmax层输出每个目标语言词典的每个词的概率。
GNMT如何计算让性能大幅提升的注意力呢?假设(X,Y)为平行语料的任一组源语句-目标语句对,则:
- 源语句长度为M的字符串:
- 目标语句长度为N的字符串:
- 编码器输出d维向量作为h的编码:
利用贝叶斯定理,句子对的条件概率:
解码时解码器在时间点i根据编码器输出的编码和前i-1个解码器输出,最大化P(Y|X)可求得目标词。
GNMT注意力机制实际的计算步骤如下:
读到这里,您也许开始倦意十足,甚至唾弃本文不知所云。请多给点耐心阅读,因为至此激动人心的时刻才开始:文章的主角Transformer(变形金刚)同学出场了!
03 高光时刻:基于自注意力机制的Transformer模型
第2部分我们提到基于seq2seq+注意力机制比一般的seq2seq的模型架构取得了更好的效果,那么这种组合有什么缺点呢?事实上循环神经网络存在着一个困扰研究者已久的问题:无法有效地平行运算,但不久研究者就等来了福音。2017年6月Transformer模型横空问世,当时谷歌在发表的一篇论文《Attention Is All You Need》里参考了注意力机制,提出了自注意力机制(self-attention)及新的神经网络结构——Transformer。该模型具有以下优点:
- 传统的Seq2Seq模型以RNN为主,制约了GPU的训练速度,Transformer模型是一个完全不用RNN和CNN的可并行机制计算注意力的模型;
- Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行计算,并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,提升模型准确率。
下面我们深入解析Transformer模型架构。
3.1. Transformer模型架构
Transformer模型本质上也是一个Seq2Seq模型,由编码器、解码器和它们之间的连接层组成,如下图所示。在原文中介绍的“The Transformer”编码器:编码器Encoder由N=6个完全相同的编码层Encoder layer堆叠而成,每一层都有两个子层。第一个子层是一个Multi-Head Attention机制,第二个子层是一个简单的、位置完全连接的前馈网络Feed-Forward Network。我们对每个子层再采用一个残差连接Residualconnection,接着进行层标准化Layer Normalization。每个子层的输出是LayerNorm(x+Sublayer(x)),其中Sublayer(x)是由子层本身实现的函数。
“The Transformer”解码器:解码器Decoder同样由N=6个完全相同的解码层Decoder Layer堆叠而成。除了与每个编码器层中的相同两个子层之外,解码器还插入第三个子层(Encoder-Decoder Attention层),该层对编码器堆栈的输出执行Multi-HeadAttention。与编码器类似,我们在每个子层再采用残差连接,然后进行层标准化。
Transformer模型计算attention的方式有三种:
- 编码器自注意力,每一个Encoder都有Multi-Head Attention层;
- 解码器自注意力,每一个Decoder都有Masked Multi-Head Attention层;
- 编码器-解码器注意力,每一个Decoder都有一个Encoder-Decoder Attention,过程和过去的seq2seq+attention的模型相似。
3.2.自注意力机制
Transformer模型的核心思想就是自注意力机制(self-attention),能注意输入序列的不同位置以计算该序列的表示的能力。自注意力机制顾名思义指的不是源语句和目标语句之间的注意力机制,而是同一个语句内部元素之间发生的注意力机制。而在计算一般Seq2Seq模型中的注意力以Decoder的输出作为查询向量q,Encoder的输出序列作为键向量k、值向量v,Attention机制发生在目标语句的元素和源语句中的所有元素之间。
自注意力机制的计算过程是将Encoder或Decoder的输入序列的每个位置的向量通过3个线性转换分别变成3个向量:查询向量q、键向量k、值向量v,并将每个位置的q拿去跟序列中其他位置的k做匹配,算出匹配程度后利用softmax层取得介于0到1之间的权重值,并以此权重跟每个位置的v作加权平均,最后取得该位置的输出向量z。下面介绍self-attention的计算方法。
▶可缩放的点积注意力
可缩放的点积注意力即如何使用向量来计算自注意力,通过四个步骤来计算自注意力:
从每个编码器的输入向量(每个单词的词向量)中生成三个向量:查询向量q、键向量k、值向量v。矩阵运算中这三个向量是通过编解码器输入X与三个权重矩阵Wᴼ̴、Wᴷ、Wᵛ相乘创建的。
计算得分。图示例子输入一个句子“Thinking Machine”,第一个词“Thinking”计算自注意力向量,需将输入句子中的每个单词对“Thinking”打分。分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。分数是通过打分单词(所有输入句子的单词)的键向量k与“Thinking”的查询向量q相点积来计算的。比如,第一个分数是q₁和k₁的点积,第二个分数是q₁和k₂的点积。
缩放求和:将分数乘以缩放因子1/√dₖ (dₖ是键向量的维数dₖ=64)让梯度更稳定,然后通过softmax传递结果。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。
将每个值向量v乘以softmax分数,希望关注语义上相关的单词,并弱化不相关的单词。对加权值向量求和,然后即得到自注意力层在该位置的输出zᵢ。因此,可缩放的点积注意力可通过下面公式计算:
在实际中,注意力计算是以矩阵形式完成的,以便算得更快。那我们接下来就看看如何用通过矩阵运算实现自注意力机制的。
首先求取查询向量矩阵Q、键向量矩阵K和值向量矩阵V,通过权重矩阵Wᴼ̴、Wᴷ、Wᵛ与输入矩阵X相乘得到;同样求取任意一个单词的得分是通过它的键向量k与所有单词的查询向量q相点积来计算的,那么我们可以把所有单词的键向量k的转置组成一个键向量矩阵Kᵀ,把所有单词的查询向量q组合在一起成为查询向量矩阵Q,这两个矩阵相乘得到注意力得分矩阵A=QKᵀ;然后,对注意力得分矩阵A求softmax得到归一化的得分矩阵A^,这个矩阵在左乘以值向量矩阵V得到输出矩阵Z。
▶多头注意力
如果只计算一个attention,很难捕捉输入句中所有空间的信息,为了优化模型,原论文中提出了一个新颖的做法——Multi-Head Attention。Multi-Head Attention是不能只用嵌入向量维度d(model)的K,Q,V做单一attention,而是把K,Q,V线性投射到不同空间h次,分别变成维度dq,dₖ,dᵥ再各自做attention。
其中,dq=dₖ=dᵥ=d(model)/h=64就是投射到h个Head上。Multi-Head Attention允许模型的不同表示子空间联合关注不同位置的信息,如果只有一个attention Head则它的平均值会削弱这个信息。
Multi-Head Attention为每个Head保持独立的查询/键/值权重矩阵Wᴼ̴ᵢ、Wᴷᵢ、Wᵛᵢ,从而产生不同的查询/键/值矩阵(Qᵢ、Kᵢ、Vᵢ)。用X乘以Wᴼ̴ᵢ、Wᴷᵢ、Wᵛᵢ矩阵来产生查询/键/值矩阵Qᵢ、Kᵢ、Vᵢ。与上述相同的自注意力计算,只需八次不同的权重矩阵运算可得到八个不同的Zᵢ矩阵,每一组都代表将输入文字的隐向量投射到不同空间。最后把这8个矩阵拼在一起,通过乘上一个权重矩阵Wᵒ,还原成一个输出矩阵Z。
Multi-Head Attention的每个Head到底关注句子中什么信息呢?不同的注意力的Head集中在哪里?以下面这两句话为例“The animal didn’t crossthe street because it was too tired”和“The animal didn’t cross the street because it was too wide”,两个句子中”it”指的是什么呢?“it”指的是”street”,还是“animal”?当我们编码“it”一词时,it的注意力集中在“animal”上和“street”上,从某种意义上说,模型对“it”一词的表达在某种程度上是“animal”和“street”的代表,但是在不用语义下,第一句的it更强烈地指向animal,第二句的it更强烈的指向street。
3.3.Transformer模型其他结构
▶残差连接与归一化
编解码器有一种特别的结构:Multi-HeadAttention的输出接到Feed-forward layer之间有一个子层:residual connection和layer normalization(LN),即残差连接与层归一化。残差连接是构建一种新的残差结构,将输出改写为和输入的残差,使得模型在训练时,微小的变化可以被注意到,该方法在计算机视觉常用。
在把数据送入激活函数之前需进行归一化,因为我们不希望输入数据落在激活函数的饱和区。LN是在深度学习中一种正规化方法,一般和batch normalization(BN)进行比较。BN的主要思想就是在每一层的每一批数据上进行归一化,LN是在每一个样本上计算均值和方差,LN的优点在于独立计算并针对单一样本进行正规化,而不是BN那种在批方向计算均值和方差。
▶前馈神经网络
编解码层中的注意力子层输出都会接到一个全连接网络:Feed-forward networks(FFN),包含两个线性转换和一个ReLu,论文是根据各个位置(输入句中的每个文字)分别做FFN,因此称为point-wise的FFN。计算公式如下:
▶线性变换和softmax层
解码器最后会输出一个实数向量。如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是softmax层。线性变换层是一个简单的全连接神经网络,它可以把解码器产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。
不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。接下来的softmax层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。
▶位置编码
Seq2Seq模型的输入仅仅是词向量,但是Transformer模型摒弃了循环和卷积,无法提取序列顺序的信息,如果缺失了序列顺序信息,可能会导致所有词语都对了,但是无法组成有意义的语句。作者是怎么解决这个问题呢?为了让模型利用序列的顺序,必须注入序列中关于词语相对或者绝对位置的信息。在论文中作者引入Positional Encoding:对序列中的词语出现的位置进行编码。下图是20个词512个词嵌入维度上的位置编码可视化。
将句子中每个词的“位置编码”添加到编码器和解码器堆栈底部的输入嵌入中,位置编码和词嵌入的维度d(model)相同,所以它俩可以相加。论文使用不同频率的正弦和余弦函数获取位置信息:
其中pos是位置,i是维度,在偶数位置使用正弦编码,在奇数位置使用余弦编码。位置编码的每个维度对应于一个正弦曲线。
Transformer模型毋庸置疑是当前机器翻译的主流模型,面对谷歌等科技巨头公司强大的实力,百分点认知智能实验室如何采用Transformer模型研制具有市场竞争力、工业级的多语言神经翻译系统呢?第4部分将为您娓娓道来。
04 工业级多语言神经翻译模型实践
4.1. 多语言模型翻译框架
谷歌GNMT采用对多种语言的巨大平行语料同时进行训练得到一个可支持多种源语言输入多种目标语言输出的神经翻译模型,但该方法需要昂贵的计算资源支持训练和部署运行。
百分点的神经翻译系统Deep Translator
百分点的神经翻译系统Deep Translator目前支持中文、英文、日文、俄文、法文、德文、阿拉伯文、西班牙文、葡萄牙文、意大利文、希伯来文、波斯文等20多个语言数百个方向两两互译,如何在有限的服务器资源的条件下进行模型训练与在线计算呢?
不同于谷歌GNMT采用多语言单一翻译模型的架构,研发团队提出的Deep Translator的多语言翻译模型为多平行子模型集成方案。该方案有两个主要特点:一是模型独立性,针对不同语言方向训练不同的翻译模型;二是“桥接”翻译,对于中文到其他语言平行语料较少的语言方向,以语料资源较为丰富的英文作为中间语言进行中转翻译,即先将源语言翻译为英文,再将英文翻译为目标语言。
采取上述方案研发团队有何深度思考呢?第一点,不同于谷歌面向全球的互联网用户,国内企业最终用户语种翻译需求明确且要求系统本地化部署,对部分语言方向如英中、中俄等翻译质量要求较高,同时希望这些语言方向的翻译效果能持续提升,发现问题时能及时校正,而其他使用频次较低的翻译模型能保证其稳定性,这导致高频使用的语言模型更新频率会较高,低频使用的语言模型更新频率较低。若将多语言方向的模型统一在一个框架下,既增加模型复杂度也影响模型稳定性,因为升级一个语言方向,势必会对整个模型参数进行更新,这样其他语言方向的翻译效果也会受到影响,每次升级都要对所有语言方向进行效果评测,若部分翻译效果下降明显还要重新训练,费时费力。而独立的模型结构对一种语言方向的参数优化不会影响到其他语言方向的翻译效果,在保证系统整体翻译效果稳定性的基础上又大大减少了模型更新的工作量。
第二点,工业级可用的神经机器翻译模型对平行语料质量要求较高,一个可用的翻译模型需要千万级以上的平行训练语料,系统支持的语言方向相对较多,现阶段很多语言方向很难获取足够的双边训练数据。针对这个问题的解决方案一般有两种,一是采用无监督翻译模型,这种翻译模型只需单边训练语料,而单边训练语料相对容易获取,但缺点是目前无监督翻译模型成熟度较低翻译效果难以满足使用需求;二是采用“桥接”的方式,因为不同语言同英文之间的双边语料相对容易获取,缺点是经英文转译后精度有所损失,且计算资源加倍执行效率降低。通过对用户需求进行分析发现用户对翻译效果的要求大于执行效率的要求,且通过对两种模型翻译效果的测评对比,“桥接”结构的翻译效果优于目前无监督翻译模型,所以最终选择通过英文“桥接”的框架结构。
4.2. 十亿级平行语料构建
平行语料是神经机器翻译研究者梦寐以求的资源,可以毫不夸张地说在突破Transformer模型结构之前平行语料资源就是机器翻译的竞争力!不论谷歌、脸书如何从海量的互联网爬取多少平行语料,在行业领域的平行语料永远是稀缺资源,因为行业领域大量的单边语料(电子文档、图书)、专业的翻译工作者的翻译成果并不在互联网上。这些资源的获取、整理成平行语料并不免费,需要大量的人工,因此是神经机器翻译深入行业应用的拦路虎。
认知智能实验室如何构建自有的多语种平行语料库呢?除了获取全世界互联网上开放的语料库资源,开发团队设计一种从电子文档中的单边语料构建领域平行语料的模型与工具,可较为高效地构建高质量的行业领域平行语料支撑模型训练。从单边语料构建平行语料需经过分句和句子对齐,那么如何从上千万句单边语料计算语句语义的相似性?开发团队提出通过给译文分类的方式学习语义相似性:给定一对双语文本输入,设计一个可以返回表示各种自然语言关系(包括相似性和相关性)的编码模型。利用这种方式,模型训练时间大大减少,同时还能保证双语语义相似度分类的性能。由此,实现快速的双语文本自动对齐,构建十亿级平行语料。
经过整理网上开源的平行语料与构建行业级平行语料,认知智能实验室形成部分语种高质量平行语料库的数量如下。
| 语种 | 中 | 英 | 俄 | 法 | 阿 | 西 |
| 中 | —— | —— | —— | —— | —— | —— |
| 英 | 12000万 | —— | —— | —— | —— | —— |
| 俄 | 4600万 | 2600万 | —— | —— | —— | —— |
| 法 | 7600万 | 11800万 | 3300万 | —— | —— | —— |
| 阿 | 2400万 | 3500万 | 3200万 | 3240万 | —— | |
| 西 | 5600万 | 8200万 | 2800万 | 6100万 | 1400万 | —— |
4.3. 文档格式转换、OCR与UI设计
打造一款用户体验良好的面向行业领域用户机器翻译系统始终是认知智能实验室研发团队的孜孜不倦的追求。为了实现这个梦想,不仅仅要采用端到端的神经翻译模型达到当前效果最佳的多语言翻译质量,还要提供多用户协同使用的端到端的翻译系统。端到端的翻译系统主要需要解决两个问题:第一,如何解决多种格式多语言文档格式转换、图片文字OCR的技术难题?第二,如何提供多用户协同操作使用UI界面?
最终用户一般希望将PDF、图片、幻灯片等不同格式的通过系统统一转换为可编辑的电子版文件并转译成最终的目标语言,并较好地保持原有文档的排版格式进行阅读。那么如何对文档的格式进行转换、对图片的文字进行识别并达到在此技术领域的最佳的效果呢?采用领先的OCR技术让Deep Translator翻译系统更加贴近用户的实际工作场景,支持对PDF、PPT、图片等多种格式、多种语言文档的直接多语言翻译而不用人工进行转换,最终输出PDF、Word、PPT等可编辑的格式并保持原有的排版风格与格式,方便用户在源文与译文之间比较阅读。
面向科研院所或公司,需要在服务器资源有限的条件下支持多用户协同操作使用并提供友好的UI操作界面。Deep Translator翻译系统经过迭代打磨,形成了四大特色:第一,提供文档翻译、文本翻译和文档转换的功能操作,满足用户不同的使用需求;第二,设计任务优先级调度与排序算法对多用户加急任务和正常任务的翻译;第三,支持单用户多文档批量上传、批量下载、参数配置、翻译进度查看等丰富的操作;第四,支持多种权限、多种角色管理及账号密码的统一认证。
4.4. 产品优势与实践经验
表1 DeepTranslator翻译评测BLEU得分
| 翻译方向 | BLEU分数(满分100) | 测试数据集 | 翻译方向 | BLEU分数(满分100) | 测试数据集 |
| 英译中 | 60.74 | UNv1.0_testset | 中译英 | 51.11 | UNv1.0_testset |
| 俄译中 | 53.05 | UNv1.0_testset | 中译俄 | 35.41 | UNv1.0_testset |
| 西译中 | 52.73 | UNv1.0_testset | 中译西 | 42.98 | UNv1.0_testset |
| 俄译英 | 52.71 | UNv1.0_testset | 中译法 | 40.14 | UNv1.0_testset |
| 西译英 | 53.97 | UNv1.0_testset | 中译阿 | 40.04 | UNv1.0_testset |
| 英译法 | 48.50 | UNv1.0_testset | 英译俄 | 46.29 | UNv1.0_testset |
| 英译阿 | 49.13 | UNv1.0_testset | 英译西 | 53.26 | UNv1.0_testset |
百分点认知智能实验室推出的多语种机器翻译系统Deep Translator支持本地化部署、定制化训练模型并达到行业最佳的工业级机器翻译水平。表1给出了Deep Translator在联合国平行语料库的官方测试集进行翻译质量评测结果,在英译中、俄译中等行业领域主流翻译方向的BLEU得分达到最佳水平。
自2017年问世以来Deep Translator已服务于数百家客户,包括在国内航空、电子等军工研究所并得到良好口碑,另外与融融网(www.rongrong.cn)合作面向上千家军工科研院所推广售卖,在推广行业机器翻译服务的道路上我们越走越远,践行用认知智能技术服务国防的使命。
参考文献:
- Nal Kalchbrenner and Phil Blunsom. 2013. Recurrent Continuous TranslationModels. In Proceedings of EMNLP 2013
- Ilya Sutskever,etc. 2014. Sequence to Sequence Learning with NeuralNetworks.In Proceedings of NIPS 2014.
- Dzmitry Bahdanau etc. 2015. Neural Machine Translation by Jointly Learningto Align and Translate. In Proceedings of ICLR 2015.
- Ashish Vaswani,etc.Attention is All You Need. In Proceedings of NIPS2017.
- Jay Alammar TheIllustrated Transformer,http://jalammar.github.io/illustrated-transformer/
- 张俊林,深度学习中的注意力模型(2017版),https://zhuanlan.zhihu.com/p/37601161
【来源:百分点】