本文转自公众号——安特飞敏捷数据服务,作者:毛立峰
搞IT的基本都知道微盟的删库事件了,微盟市值从事件发生前的138亿港币(2月21日收盘价)下跌到现在的122亿港币,直接损失16亿市值。
出了问题不怕,怕的是同样的事再次出现;而更怕的是,各位看官嘻嘻一笑,以为这种事不会出现在自己身上。
即使没人故意作案,也会有各种各样的偶然事件导致同样的后果,如误删、病毒等。
因此,作为严肃的IT从业人员,看到八卦,可以会心一笑,但别人的教训,还是要汲取。
基于从公开的信息上,本人尽可能分析出微盟可能存在的问题,并提出出应对机制,从而抛砖引玉
一、运维底线思维的缺失
先看一张微盟运维架构图,注意,这是运维架构图,不是系统架构图。
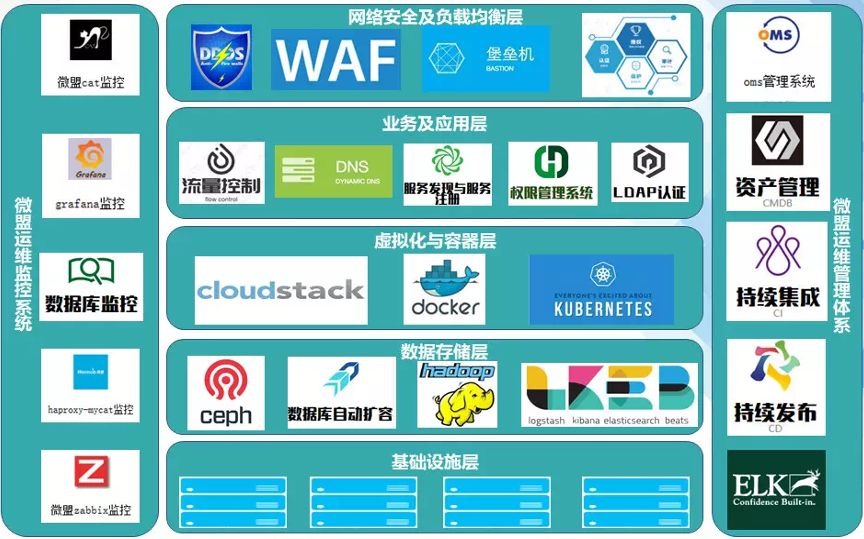
有底线思维的运维人员,一定会将业务连续性或者备份、容灾等放在这张图里,但很可惜,没有。这只能说明,微盟对IT运维最后一道防线(业务连续性)很不重视。
当然,这不是说没有备份容灾机制,实际上是有的。很明显的证据是,目前微盟和腾讯云在恢复数据,如没备份,就不会有这个操作,微盟也就直接关门了。
但显然没有将备份容灾上升到业务连续性的高度和广度,这是观念的问题。任何一家公司,都需要重视这道防线,无论重视的程度有多高,都不为过。
二、运维权限管理的问题
显然,一个人就可以造成这样的后果,运维的权限管理出现了问题。
通过权限的三权分立(操作、授权、审计),不经过审计员监控下的安全员的授权,操作人员无权操作,而实际操作只有操作员可以操作,可以直接避免这个事件的发生。除非团伙做案。
以上二个问题是可以直接得出结论的,不难分析。
下面来做一些更深层次的分析
先看这个

从恢复时间看, 第一阶段 已在25日24点恢复系统,新用户可以使用系统,持续了53小时。第二阶段 将在28日24点恢复老用户的数据,将持续125小时。
再看看微盟的系统规模:

个人认为,贺某的操作有二种可能,第一是执行了rm -rf /*,但不仅仅对数据库的主备库的服务器执行了操作, 还把其他的应用服务器、Web服务器都做了操作。因为,互联网公司的数据库架构,应该是横向扩展的(上面运维架构图中的数据库自动扩容功能),可以分钟级部署一个新的数据库来服务于新增的客户,也就是说,如果只是数据库出问题,其实只要分钟级就可以恢复了,不需要53小时(从出问题到可以对新客户进行服务)
第二种可能是,贺某直接把所有虚拟机干掉了,不管什么服务器,无差别删除。效果和第一种是一样的
基于以上系统损坏的覆盖面的分析基础,开始存在的问题分析
53小时的第一阶段修复,引出了第三个问题
三、应用或者公有云敏捷性问题
第一阶段的恢复要53小时那么长的时间,有点出乎我对互联网公司的想象
要实现只对新客户提供服务,不需要恢复到原有的规模,假定需要恢复到十分之一,即重新部署400套系统、100套数据库,由于采用的都是云原生的基础架构及管理软件,53小时显然过于漫长了(除非我对云原生技术的想象太美好)
造成这种情况的可能性有二种,一是应用开发没做到无状态化,需要大量的配置,耗费了时间。二是该公有云不够敏捷或操作不够熟练
怎么解决呢?这就要提起老生常谈的灾难恢复演练,基于底线思维,从0状态开始演练,从而暴露技术储备、应用开发、基础架构等等方面的种种问题,并加以改进
作为IT运维老大哥的全国4大行经常做容灾演练,就是基于这种底线思维。互联网公司是小青年,有冲劲,有想象力,这非常好,但老大哥们走过的桥(踩过的坑)比小年轻走过的路还长,有必要好好学习的
四、 备份的问题
第二阶段的恢复时间很有问题
前面说了,微盟是有备份,否则已经关门了
公有云都提供备份解决方案的,实现原理基本都是对虚拟机做快照,然后将快照数据保存到对象存储内,而作为运行在公有云上SAAS互联网公司,一般缺省都会直接使用公有云的备份
4.1 公有云的备份原理造成黄金时间的丧失
在原理上,备份快照可以即时恢复,但如果可以即时恢复,也就没有第一、第二阶段了,显然,快照失去了作用或者快照内的数据是脏数据。
这种情况是怎么产生的呢?快照是定期执行并有保留周期的,假定每2小时执行一次快照,并保留2份快照。那么,从现在开始,我删除数据,过四小时后,快照内的数据就是脏数据了,因为二份快照都是数据被删除后的虚拟机状态,没用了。所以这四小时,就是“黄金时间”
是否可以延长“黄金时间”呢,很不幸,基于公有云的快照备份原理,如果延长黄金时间,会对生产造成很大的性能影响、成本及数据丢失量。有二种调整黄金时间的选择
1、增加快照的保留份数:
快照会对生产虚拟机产生性能影响(假定快照采用Copy On Write的机制),保留的份数越多,性能影响越大,并产生更多费用。因此不会有人保留很多份。
2、延长执行快照的时间间隔:
比如一天做一次快照,那么就有二天的黄金时间。但这会造成二天的数据丢失量(RPO)。也就是说最近二天的客户数据将无法恢复。在正常情况下,没人会选择这么长时间的RPO。当然,微盟现在的心态,应该很希望用二天的RPO来换小时级的业务恢复。
具体微盟的黄金时间有多长,我们不知道,从公告中,可以看出,微盟需要和腾讯云技术团队一起研究数据恢复,这一研究,黄金时间就过去了。
如何解决这一问题,建议采用第三方的备份软件,并直接从数据库层面去备份,而不是对虚拟机做快照。
第三方备份软件,可以在不影响生产性能的前提下,将备份数据的保留周期设置很长。其实,当数据库、应用服务器都出现问题时,备份作业也就不会发起,就不会有脏数据。
其次,通过对数据库归档日志的备份,可以将RPO缩短到分钟级。
当然,在选择备份软件时,RTO必须重点考虑,如果也要125小时,就和公有云的备份效果没什么区别了。
4.2 把快照作为备份,违背了备份的铁律
对虚拟机做快照的备份方式,还隐藏着公有云本身可靠性带来的风险,如果虚拟机的存储出现问题,生产数据与快照数据会一起损坏,专业备份软件厂商都不会建议生产存储的快照作为备份的,这是备份架构设计的铁律。
去年,某云就因为存储问题造成某企业数据丢失,当时沸沸扬扬,现在大家可能都忘了吧
公有云公司也都知道这一点,所以,他们都会将快照数据保存到对象存储,甚至再复制一份到另一区域的对象存储。
4.3 125小时的对象存储还原时间
现在微盟正在恢复的数据在哪里呢? 在COS对象存储或CAS归档存储内。快照执行后,快照内的数据可以自动放入对象存储或归档存储内,并设置很长的保留周期
从对象存储内进行恢复,预估时间是125小时,这个RTO真是长啊,目前还不知道会丢失多少数据,我预估在一天,因为从快照到对象存储的数据复制的频率,不会很频繁,估计是一天一次
现在要做的操作是:先从对象存储内将数据库服务器的备份数据还原到块存储,再基于块存储的备份数据生成虚拟机,然后就是起数据库,并和第一阶段起来的应用服务器进行连接配置
这里,最花时间的就是还原操作,由于对象存储的特性,这个速度会很慢
我们假定需要恢复125TB的数据,125TB怎么来的呢?一般互联网公司的单个数据库会保持在500GB,官网上说有1000+个数据库,主备比率假定为1:3。数据量为 1000/4*500GB=125TB
如果还原速度是1TB/小时,那就需要125小时
如果还原速度是2TB/小时,那就需要62.5小时
1TB/小时快不快?对于对象存储来说,其实已经很快了。腾讯云的技术人员肯定在想尽办法提高这个速度:网络带宽、还原并行度等等。这次的服务费应该可以让一家小公司好好的吃上一年了
有办法大幅减少这个还原时间吗?
有,如果备份数据,无论是在块存储上还是在对象存储上,都不需要还原操作,直接通过挂载方式恢复数据库。那么,250个数据库(共125TB数据库),很有可能100分钟内就完成恢复
这种技术就不展开讲了,有兴趣的人,自会找到谁可以提供
总结一下
其实上述各种问题的引起和解决方案,20年前就广泛提倡的业务连续性管理,就是答案。底线思维、领导意识、备份、容灾、RTO、RPO、灾难恢复演练等等,都包含在业务连续性管理的框架中
领导重视,然后有顶层设计,全面审视业务连续性方面可能存在的问题,再建设应对方案。就能消灭年年都在媒体上曝光的这类事件
希望微盟能顺利恢复
发展很重要,但后方安稳才是你前进的基础。
秦人不暇自哀,而后人哀之;后人哀之而不鉴之,亦使后人而复哀后人也