2020年,如果再有人问我推荐选什么专业的话,我推荐的一定跟数据相关领域,希望更多人成为数据科学家,数据工程师,数据库管理员,做一些有关数据建模的事儿,2020年,虽然比这类工作更有价值的工作还有很多,但我知道,这些与数据相关的工作其实非常有价值。
数据相关工作能力可能更多来自实践,而不是课本知识。数据相关的方案琳琅满目,成熟的商业化方案财务门槛高,开源的方案需要花费的额外精力太多,越来越多的人意识到应该或多或少具备数据分析能力,以避免在数据洪流中进退失据,在降低数据分析门槛的方案中,云计算是首选,在数据分析的最佳实践中,云计算还是首选,在众多云厂商的方案中,AWS的数据湖方案是不错的选择。
从数据挖掘价值是一件非常有价值的事情
古人用“学富五车”形容一个人博学多识,其实,古代的五车竹简所能传递的信息量非常有限,随便一部智能手机都能顶上几百甚至上千个“五车”。
也有人会说了,虽然我们接触的信息量多,但能记住的并不多。人们特别希望有好的记忆力,小时候特别羡慕金庸小说里黄蓉的妈妈过目不忘背《九阴真经》的能力,这种戏剧化的设定代表的只是一种美好的愿望,就跟现在人想尽可能存下数据的想法是一样的。
事实上,古人精读少量内容之后的领悟其实更深,与单单的记录相比,人们真正关心的是从已有的信息中心获取经验、结论和洞察,如今,数据越来越多,过几年的数据量相当于以前所有数据的总合,这种说法太吓人了,如何在信息的洪流中不随波逐流迷失自我,从中找到有用的东西呢?
这就是如今大数据和人工智能在极力塑造的能力,他代表了人们了解世界,认识世界的愿望。
技术的发展就是让原本看似高大上的东西变成人人都能用到的东西,要么降低获取的成本,要么降低使用的门槛,要么两者兼有。
技术发展下,越来越多的人开始使用大数据技术,比如,企业市场人员需要用大数据了解消费者的分类,商品门类的分类,客户忠诚度信息,客户流失率等,金融人要用大数据做风险管控,检测异常交易,欺诈交易,医疗行业有人靠数据研究疾病的传播模式,研究药物,看临床反应测试数据,大数据无所不在。
不少人都遭遇过手机空间不够用的尴尬,在清除空间的时候经常会发出这样几个疑问:32GB变成128GB了怎么还不够用?照片怎么占了这么多空间?社交软件怎么占了这么多空间?XXX软件怎么也占了这么多空间?怎么全删了还占这么大空间?
总之,数据在你我不知不觉间产生了,个人手机里的数据类型多种多样,企业里的数据类更是多种多样,而且数据规模也不在一个数量级。更可怕的是,企业内部不同业务之间往往还存在数据孤岛,就是财务,人事行政,业务等各个不同的系统相互没有联系,在外部看起来这家公司是一个整体,而实际上公司里是一个个独立松散的部门。
数据湖是洞悉数据Insight的正确选择
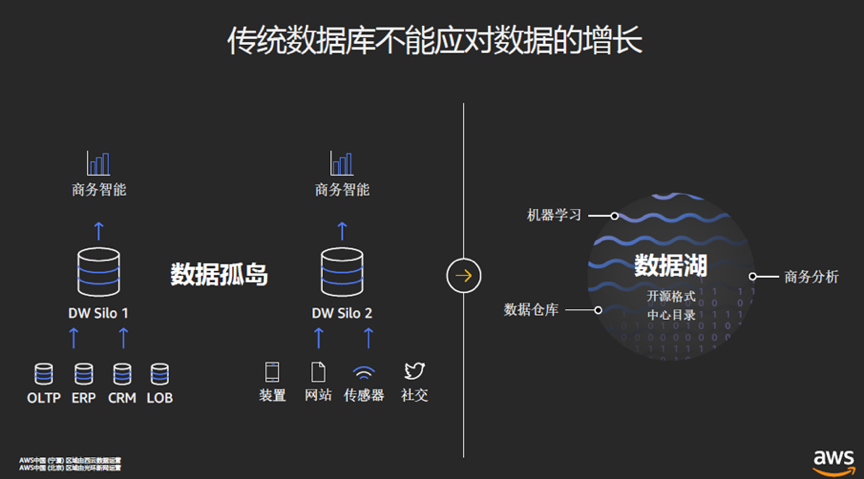
为了应对数据管理和数据应用的问题,越来越多的企业选择了数据湖方案(DataLake)。

我一直觉得DataLake的中文翻译非常传神,在汉语文化中,“江河湖海”哥儿四个,个顶个儿的非常大,数据湖也如上图所示,功能很强大,能做的事情非常多,而且,还有很强的包容性。
包容性体现在三个方面:
首先,容量特别大,互联网时代数据洪流经常有突发性和不可预测性,比如新浪微博上的明星恋爱、结婚、分手、离婚新闻就有突然性。从数据的角度看,好比夏天突如其来的暴雨,它可能会带来洪涝灾害,而有个湖就能将降水蓄积起来,数据湖能做到这点,来多少数据都不怕。
其次,能容纳的数据类型非常多,无论是原始的未经处理的数据,还是结构化的数据,还是非结构化的数据,只要是能以0101的方式存在硬盘里的数据,数据湖都能存进来。
第三点,能干的事儿多,数据湖不仅能做以前数据仓库(DataWareHouse)做的工作,包括数据分类提炼还有数据分析之类的,而且还有各种方法对这些数据可以进行查询,所以能对接机器学习,人工智能这类新型应用。
数据湖这么强大,强大意味着复杂,如何以最简单的方式构建数据湖呢?答案是基于云的数据湖方案。
AWS的云上数据湖方案
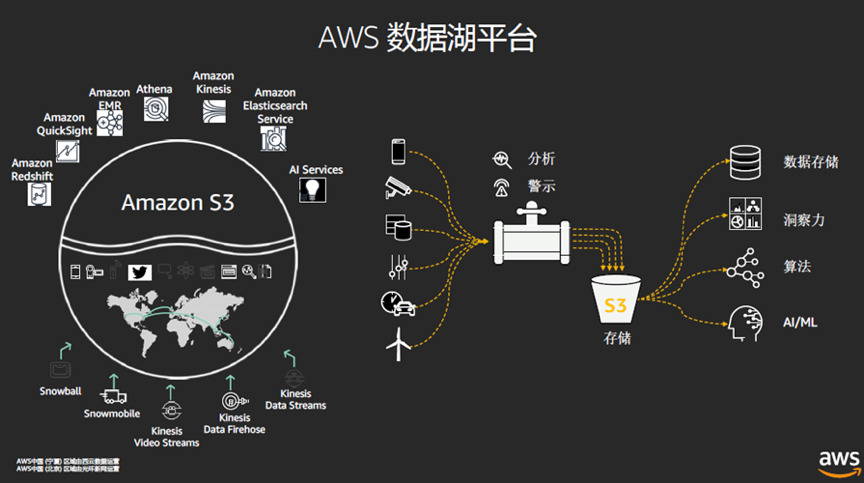
作为公有云领头羊的AWS在许多技术方案方面都非常有代表性,是许多云厂商争相研究和对比的标杆,AWS的数据湖是怎样的存在呢?
AWS的数据湖平台有多种多样的服务,能以多种多样的方式获取多种多样来源的数据,然后存起来进行多种多样的分析利用。
首先,解决数据从哪儿来的问题。
AWS有一系列的数据迁移工具,比如做数据库迁移的AWS Database Migration Service数据库迁移服务 (DMS),还有数据快递箱AWS Snowball (雪球),还有混合云场景下的AWS Storage Gateway存储网关,还有AWS Backup数据备份方案。
然后,解决数据存储的问题。
AWS的数据湖方案的核心是Amazon S3存储,作为AWS第一个云服务,AWS的S3树立了对象存储的标准,另外,S3 Bucket(桶)的概念也是一个神命名,桶作为生活常用容器可以装各种东西,作为数据存储可以存各种二进制的数据。
作为一个能存放大量数据的容器,价格自然得亲民,为了降低价格,S3衍生出的Amazon Glacier让价格降了一大截儿,后来又推出了Amazon S3 Glacier Deep Archive归档方案,价格又降了一大截儿。
数据湖方案里的数据库类型可以说是应有尽有,包括有键值数据库Amazon DynamoDB,还有支持SQL Server、Oracle、MariaDB、PostgreSQL和MySQL托管的关系型数据库服Amazon 务RDS,还有AWS专属的Amazon Aurora数据库,AWS一再强调Amazon Aurora是增长最快的一个服务,但目前尚不清楚与别的数据库相比的概况。
以上几个方面,包括S3存储和各种数据库解决了数据存的问题。第三点,数据要如何使用起来呢?
Amazon Redshift是AWS的数据仓库,据说成本是传统数据仓库的十分之一;Amazon EMR是AWS的MapReduce集群,可以运行包括Spark,Hadoop,Hive,Hbase等大数据分析工具。Amazon Elasticsearch是做一些运维分析;Amazon Kinesis可以做实时的数据分析。
AWS的数据分析方案并不是简单把别人做过的开源的方案放到云上,同时,AWS也按照自己的理解提供自己独有的分析方案,这是AWS在很多方案上都惯用的策略。
比如,AWS Glue(胶水)是一个专业的ETL工具,能做数据分析的准备工作。AWS Glue首先是一个Servless服务,成本比较低,它能为数据生成数据目录(DataCatalog),能自动完成ETL操作将数据传递给数据仓库,它支持对AWS上的各种关系型数据库,S3对象存储的数据进行操作,作为一个ETL工具,Glue非常简单易用。
ETL是一个非常复杂,非常难的操作,基于数据仓库的工作中,大部分时间可能都在做ETL,ETL的工具非常多,好用的特别贵,便宜的非常不好用,AWS的AWS Glue把一些共性的东西做出来,以Serveless的方式提供,可以说是AWS数据湖方案里的一大亮点了。也可以说是很多人想用AWS数据湖方案的一个原因。
又比如,Amazon Athena是一个Servless服务,它提供的是一个交互式的数据查询服务,可以用它对S3里的数据进行查询,支持用标准的SQL语句进行查询,做数据分析用,使用起来非常简单。3月24日,AWS宣布AWS Glue和Amazon Athena在中国(宁夏)区域上线,已经可以上手使用了。
数据湖是处理数据的技术,而人工智能是非常依赖数据的,如果想用数据湖的数据做一些人工智能的项目,Amazon SageMaker等AI服务也支持从数据库拿数据进行训练。这点在AWS上也是水到渠成的。

以上,就是AWS数据分析组件的大部分内容,大致的逻辑关系可以参照上图。
AWS提供的各种服务之间可以在云上相互协作,从而组合而成数据湖方案,不过,光是看到有这么多服务就知道这事儿其实还是有点费劲。为了简化数据湖的构建过程,AWS还推出了一个叫AWS Lake Formation的服务,可以自动构建一个数据湖。目前中国区暂时还不提供Lake Formation,AWS首席云计算企业战略顾问张侠博士表示中国区很快就会有。
他们怎么用AWS数据湖方案
迁移上公有云的用户越来越多了,云计算也越来越成熟了,包括Amazon EC2,Amazon S3等基础性服务用户已经非常熟悉了,在AWS上,像数据库已经能对Oracle进行替代了。这些都已经经过亚马逊电商平台的实战验证了,AWS推出的方案成熟度非常高。

张侠博士介绍说,亚马逊曾经是Oracle全球数据库最大的用户,它用了75PB的数据库容量,7500多个数据库,整个亚马逊里1000多个不同的团队原本都是用Oracle的数据库。过去一年半到两年时间,亚马逊全方位将Oracle数据库迁移到了自己对应的产品,不仅如此,迁移过程并不困难,费用方面,数据库成本减少60%,管理费用减少70%,性能提升高达40%。
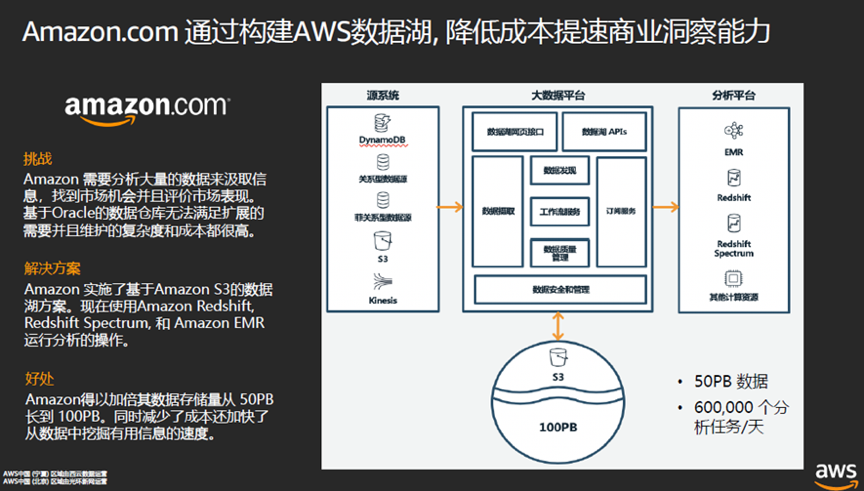
亚马逊电商的核心竞争之一就是在内部使用的一个叫Galaxy(银河)的数据湖,这就是亚马逊有时候比你自己还了解你自己的秘密武器。这个数据湖里有50PB到100PB数据,可以把亚马逊的数据进行整合后做大数据分析,亚马逊每天有60多万的分析任务,从用户推荐、运营信息、库存信息、购买信息、物价信息等等,都依赖于数据湖。这个数据湖就是AWS数据湖方案构成的。

FINRA是一家美国的金融监管机构,每天有超过1500亿的事件,每天要监测20PB的市场活动数据,FINRA使用AWS的数据湖方案,把所有金融交易的信息都整合在一起进行分析,与原来相比,每年节省1000万美元到2000万美元的费用。
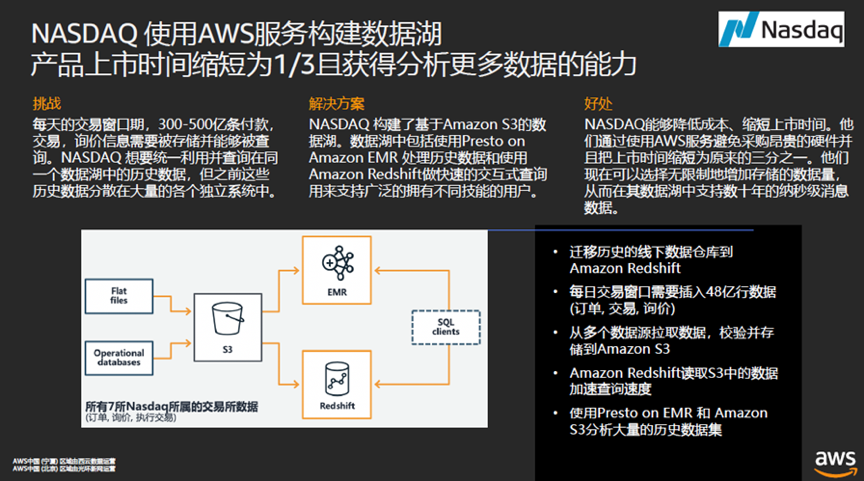
纳斯达克每天要处理300-500亿次付款、交易、询价操作,而且要能查询这些记录,此前,多种数据散落在不同的系统中,在采用AWS的数据湖方案之后,能处理历史数据并进行交互式查询,对纳斯达克来说,不仅降低了成本,而且把上市时间缩短为原来的三分之一。

Club Factory是一家中国的跨境电商平台,它的业务需要做个性化推荐、内部运营分析以及供应商管理等场景,每天要处理15亿条行为日志,支撑180个活跃数据分析调度,每天需要把4000多个业务数据同步到AWS的数据仓库Redshift。AWS的数据湖满足了其业务增长需求,同时成本也有优化,Club Factory还特别提到了Glue自动化ETL操作带来的便利性。
AWS的数据湖方案也是不错的选择
云体验好就好在,它极大降低了安装部署方案的复杂性,云计算本身就是最佳推荐配置和方案,云上方案的安装部署配置能满足绝大多数人的需求,而且,在规模效应的加持下,成本会越来越有竞争力。
从个人学习或者企业尝试新方案的角度讲,在不够充分了解一些新事物的时候,在云端走一遍是最快捷,最廉价,最高效的学习途径。当然,理论上技术爱好者自己搭建一些方案也是可行的,但企业生产环境容不下尝试性的方案。
笔者一直以来都认为,云上的数据分析是数据分析的最佳实践环境,无论是企业还是个人,如果致力于从数据中挖掘价值,那么云上数据分析一定是绕不开的。
云计算是讲究规模效应的,不是因为选择AWS的用户多AWS就一定好,用户多,规模大,AWS可以用更先进的技术进行降本增效,AWS的Nitro和即将推出的ARM服务器都是降本增效的典型例子,这让AWS的方案更有成本优势。
云计算作为公开的服务形式,用户可以对其服务进行评价和反馈,AWS的企业文化能接受这些反馈并作用于产品中,AWS从不画大饼讲未来的Roadmap,有的只是听需求,然后评估之后做产品方案,这会让产品和服务的体验变得越来越好。
有鉴于这两点,我觉得AWS云计算是一个不错的选择,数据湖方案里,AWS的数据湖方案也是不错的选择。