
全新的数据世界为实现更高级别的科学模拟开创了机会,使我们能解决过去曾经认为不可解决的棘手问题,开发高级深度学习引擎,用以改善我们的生活。为了达成这些目标,数据中心体系结构已经悄然发生了变化,新的技术正在将数据中心体系结构从以 CPU 为中心的旧概念过渡到以数据为中心的新概念。在这个过程中,一个至关重要的环节就是一些新型计算方案的出现,如智能和可编程的互连解决方案。
InfiniBand 作为一种标准互连技术,长久以来一直在高性能计算和深度学习领域保持领先地位,现在又被应用于各种云平台,为计算和数据密集型应用提供高效服务。目前,在业界领先的云平台和Hyperscale 系统中,数以万计的计算节点使用InfiniBand互连,与全球各地众多的超级计算机系统采用了相同的方案。全球用户纷纷选择 InfiniBand 作为互连技术,是因为它能提升计算密集型和数据密集型应用的性能和扩展性。在传统以太网为基础的数据中心中,越来越多地出现使用InfiniBand互连的HPC、AI、大数据等专业应用池,这些专业应用池通过高速网关连接到以太网基础网。另外,InfiniBand 网络不仅仅性价比高,而且在相同数据吞吐量的情况下,甚至比以太网成本更低。
InfiniBand 推出了创新型网络计算引擎,它内置于网络设备内,可以对网络传输中的数据执行算术运算操作 – 比如数据聚合、数据标签匹配及其他一些运算。另外,还有一些InfiniBand 设备内置标准计算核心,可以很方便地编程来实现其他相关的数据运算。正因如此,与以太网或其他私有网络(有些是隐形以太网)相比,InfiniBand显然成为首选解决方案。
显而易见,网络计算的创新在于,除了履行它在数据中心中互连的核心使命外,网络还变成了传输数据中的“协处理器”,– 也就是说,能有效和高效地移动数据,确保其余计算资源能及时接收到数据。经过多年发展,该领域涌现出大批技术和功能,比如 RDMA、GPUDirect® RDMA、QoS、动态路由和拥塞控制,这些技术都是InfiniBand标准规范的一部分。其中最后两项InfiniBand网络的基础功能,却成为了一些最新的私有网络的新技术。
我们以网络拥塞为例说明。网络拥塞主要由以下两个原因导致:1)点对点通信共用同一网络路径,而其他路径则闲置;2)在多对一通信模式下,单个接收端无法及时处理多个发送端同时发出的所有数据。
动态路由机制可克服因点对点网络通信分布不均衡导致的网络拥塞。橡树岭国家实验室使用MPIGraph 基准测试结果表明,InfiniBand 动态路由可实现 96% 的网络利用率(来源:“The Design, Deployment, and Evaluation of the CORAL Pre-Exascale Systems,” Sudharshan S. Vazhkudai, Arthur S. Bland, Al Geist, et al )。InfiniBand 可以实现细粒度动态路由,支持多种动态路由方案。可以根据系统设计和使用情况选择最合适的方案来实现优异的性能。

图 1 – 静态路由与动态路由的 mpiGraph 性能结果比较,展现出 InfiniBand 动态路由的优势,在 Summit 超级计算机上的测量结果显示,它有效地消除了点对点拥塞,实现了 96% 的网络利用率(来源:“The Design, Deployment, and Evaluation of the CORAL Pre-Exascale Systems”,Sudharshan S. Vazhkudai、Arthur S. Bland、Al Geist , el al)
多对一通信拥塞问题可通过拥塞管理或拥塞控制机制加以解决。拥塞控制的关键在于,依靠网络交换机发现多对一场景并迅速向发送端发出网络拥塞通知。发送端接到拥塞通知后,适当减少发向接收端的数据量,以确保接收端能成功处理所有数据。这样可以防止网络被数据淹没,交换机缓冲区保持为空,从而避免了多对一拥塞场景。显然,拥塞通知越及时从交换机发出和到达发送端,拥塞控制成效越显著。
早在 2010 年,我有幸与挪威 Simula 实验室团队合作展示 InfiniBand 拥塞控制机制。我们搭建了一个小型实验环境,其中包含七台服务器和两台交换机,通过 DDR 20Gb/s InfiniBand 链路将各服务器连接到交换机(其中三台服务器连接到一台交换机,其余四台服务器连接到另一台交换机),再通过一条 QDR 40Gb/s InfiniBand 链路连接两台交换机。我们构造了一个多对一网络拥塞场景,和牺牲流(Victim Flows)(牺牲流是指其数据流不属于多对一通信组,但因拥塞导致性能受损)。结果证明了 InfiniBand 拥塞控制不仅可以消除网络拥塞,还能防止产生牺牲流。

图 2 – 采用 InfiniBand 拥塞控制与不采用 InfiniBand 拥塞控制的网络性能 – 证明 InfiniBand 拥塞控制在消除多对一拥塞和牺牲流方面的成效(来源文章:“first experiences with congestion control in InfiniBand hardware ”,2010 年)
毋庸置疑,自 2010 年以来,InfiniBand 硬件拥塞控制机制又进行了多次改进和增强。例如,最新 HDR 200Gb/s InfiniBand 交换机和网卡的 面向更有效和高效拥塞控制的快速发现和通信机制。
最近,我们注意到一种名为GPCNeT (Global Performance and Congestion Network Test – 全局性能和拥塞网络测试)的新型网络测试基准。GPCNeT 基准测试是一项 MPI 级测试,旨在衡量后台流量对于 Random Ring 延迟和带宽以及小数据 MPI Allreduce 操作的影响。这引起我们的思考:为什么创建此类基准测试突然变得如此重要?为什么没在十年前做这件事?主要原因在于直到最近那些私有网络才刚开始支持拥塞控制,还把它作为一个技术创新来进行介绍。
简单而言,GPCNeT 基准测试可测量三种 MPI 操作,分别在两种场景下进行每种操作测试:第一种场景,部分集群节点运行任一种MPI操作测试,其余节点闲置;第二种场景,相同节点运行同一种 MPI 操作测试不变,在其余节点上注入背景网络流量,构造多对一通信操作和网络拥塞。最后对每项测试在两种场景的结果进行比较,得出 GPCNeT 基准测试评分。
实际上,GPCNeT 基准测试衡量的是有载相对性能,而不是绝对网络性能。因此,GPCNeT 无法用来比较一种网络相对另外一种网络的快慢。举例来说,如果在一个网络上测试GPCNeT看到无拥塞时 MPI Allreduce 延迟 是2us(微秒)、有拥塞时延迟是 3us,而另外一个网络上测试GPCNeT看到无拥塞时延迟 是100 us、有拥塞时延迟 是110us,根据GPCNeT得分,会得出错误的结论,认为第二个网络更好(但是众所周知,延迟越小,网络性能越好)。这就是GPCNeT 基准打分机制的问题:它掩盖了真实的网络延迟性能。
此外,这个基准测试将 8 字节 的数据视为MPI Allreduce的重要测试数据,而背景拥塞流量则基于大消息。并不是说 8 字节 MPI Allreduce 性能不重要,而是大消息的聚合和归约对应用程序性能的影响更大 – 例如深度学习场景。深度学习已经成为很多 HPC 应用的重要组成部分,可用于提高 HPC 模拟的精确度。当然,应用程序中还会用到 8 字节数据交换,但大消息(从几百字节到几千字节乃至数百万字节大小)使用程度更高,且对应用程序性能的影响也更显著。
基于上述种种事实(还可以列出更多其他理由),我们可以得出结论:GPCNeT 是一个非常牵强的基准测试,其作用极为有限,无法用它的结果来比较现实网络性能。
最后,如果我们想看一下 HDR 200Gb/s InfiniBand 在 GPCNeT 基准测试中的表现究竟如何,测试结果再次印证了 HDR InfiniBand 的世界顶尖性能,几乎没有抖动!事实证明,InfiniBand 拥塞控制机制完美解决了 GPCNeT 基准测试营造的拥塞问题,GPCNeT 拥塞因子得分几乎为1 – 而1是GPUNeT拥塞因子理论最好成绩。
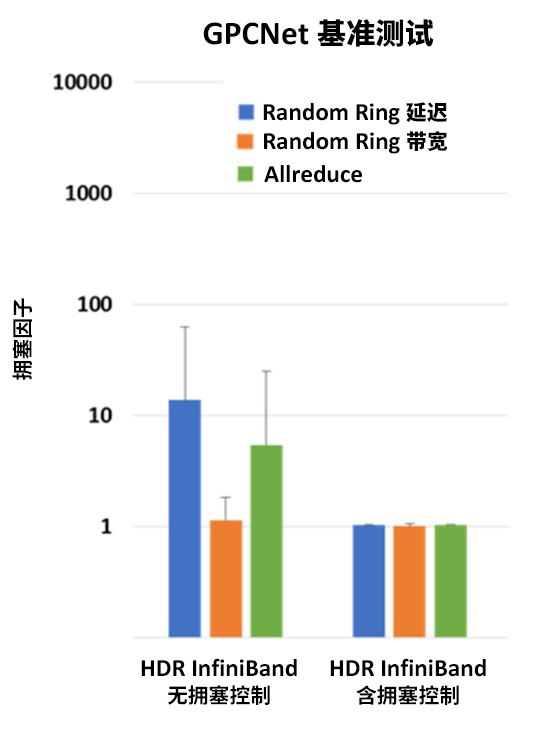
图 3 – 启用拥塞控制与不启用拥塞控制的 HDR 200Gb/s InfiniBand 的 GPCNeT 基准测试结果。在启用拥塞控制的情况下,InfiniBand 呈现出世界领先的性能结果。
当评估高性能计算系统或互连产品时,业界有很多更有效的基准测试可选。如果能够将用户实际应用作为基准进行测试,显然更有利于确定系统或网络的性能与功能。GPCNeT 基准测试的缺点远超过优点,是否应该称其为GPCNoT 呢?







