从Excel、报表系统到传统BI,企业数据分析工具进化的同时,背后需要支持的数据承载量也在以更快的速度一路攀升。
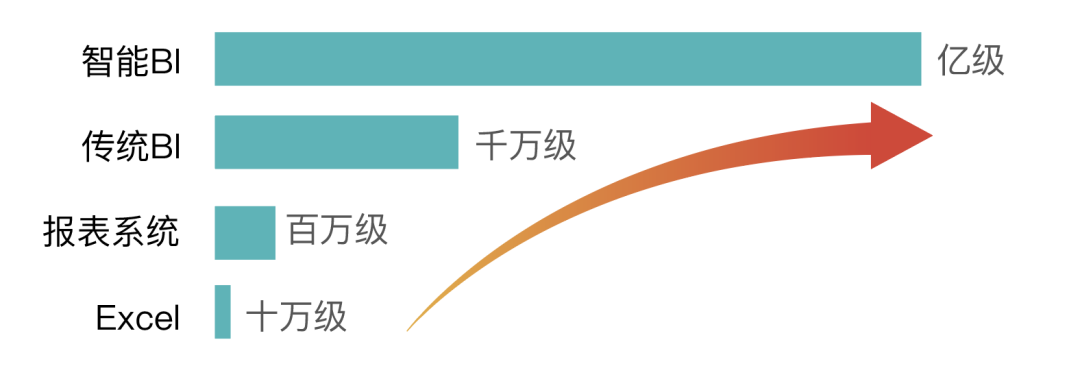
(各数据分析工具适合承载的数据量)
以一家连锁零售企业为例,如果门店有2000家,在售SKU有5000个,一天单店单品库存数据量就达到了1000万,一周就可能破亿。
为了能让性能跟上企业数据发展的速度,确保用户在亿级、十亿级数据集的基础上还能做丝滑的拖拽式数据分析和动态查询,同时又不会给IT人员带来额外的数据管理与运维压力。观远数据在2019开始研究基于海量数据计算查询的加速组件,并于2020年3月正式推出“极速分析引擎”黑科技功能,真正做到十亿级数据秒级响应。

“极速分析引擎”是嵌入在观远一站式智能数据分析平台中的一套计算查询加速组件,在集群模式下最快支持十亿级以上数据秒级响应速度。适用于零售行业大数据量、大宽表、高并发的数据分析情况,比如海量库存数据聚合分析与查询、订单分析、商品分析等场景。可以满足业务人员持续的探索式自助分析、即席查询、动态分析的需求,保持连贯的分析思路,打造沉浸式分析体验,深挖数据价值,高效洞悉业务。
“极速分析引擎”到底有多快?我们在实验室环境下做了一个性能测试。测试的机器为16核128G内存的单节点,未做加速组件的独立部署(实际上加速组件可单独部署,加速效果更明显)。
Demo1:极速查询演示
以上案例中,我们模拟了某零售客户基于订单商品明细数据的任意时间区段销量、销售额、成本的聚合分析。
可以看到,左右两张表都是基于同一张1亿行的订单明细表进行聚合分析。区别在于左边的表是使用的是Guan-Index数据集,是利用Spark计算引擎来进行计算的。而右边的表则是使用“高性能查询表”,利用“极速分析引擎”来做加速查询的。不难发现,在切换日期区间时,右侧表格基本上能够在2~3秒内返回计算结果,而左侧表格则需要10秒才能返回,整体的性能提升达到3~5倍,真正做到亿级数据秒级响应。
Demo2:一亿行数据自由拖拽式分析
还是基于以上数据,我们再做一下自由拖拽式的数据分析进行测试。从Demo中可以看到,基于1亿行订单明细数据的自由拖拽分析,也可以做到秒级响应,丝滑体验。
如此强大的功能要怎么使用?
当用户导入千万级以上Guan-Index数据集,或者通过Smart ETL生成同等体量的数据集后,想要使用“极速分析引擎”来进行查询加速时,我们可以大致分三步进行操作。
1、配置数据集
我们可以进入到数据集详情页“高级选项”栏,将数据集配置为“高性能查询表”。
2、设置分区字段
用户需要设置分区字段——分区是为了数据在存储时能合理地分片,以减少数据查询时的数据扫描。一般建议使用日期字段来做分区,分区方式建议设置为“月”或者“日”。使用日期字段做分区,可以有效地控制分区数量,不至于把分区做得过粗或者过细。如果没有日期字段,也可以谨慎选择其他字段进行分析,这时需要控制好分区字段的枚举数量,一定不要选择类似订单ID之类的流水号,或者数值类字段作为分区字段。
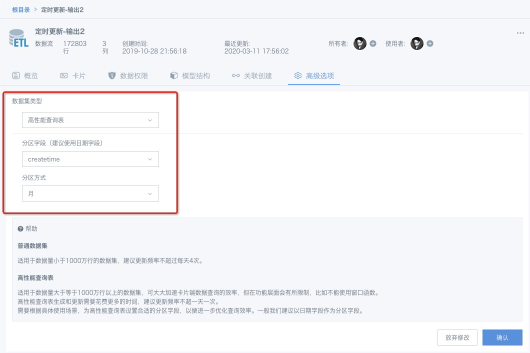
3、确认执行
配置完分区字段后,点击“确认”即可以开始模式切换。数据集数据量大的时候,数据导入需要花费一定的时间,请耐心等候。内部测试,3亿行*26列的数据集导入花费12min左右。数据集更新也会触发数据重新导入,因此一般建议高性能查询表更新频率不超过一天一次。
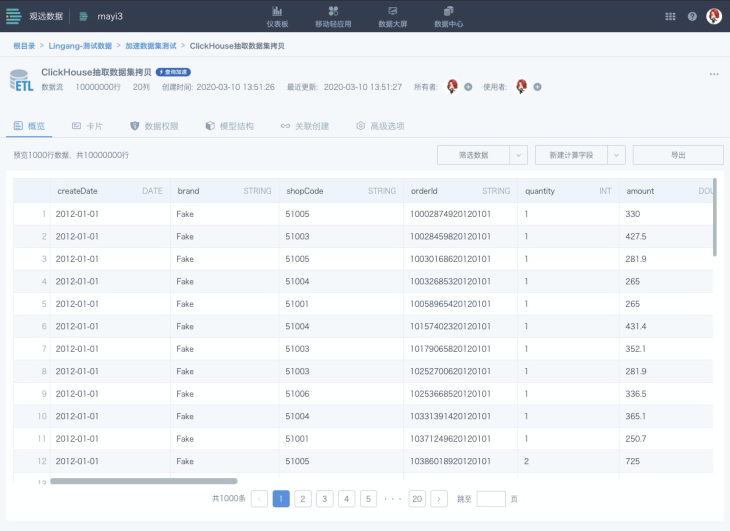
以下就是一个配置了“高性能查询表”的ETL输出数据集,我们看到表面看起来它似乎与一般的ETL输出数据集并无二异。但我们在使用它创建卡片时,却是利用“极速查询引擎”来查询数据,能够提供飞一般的体验。
“极速分析引擎”适用于哪些场景?
目前,“高性能查询表”适用于数据量大于等于1000万行以上的数据集,可大大加速卡片端数据查询的效率。并且特别适合海量数据下的OLAP查询,适合在大宽表上做任意维度的数据聚合、切片(筛选),也可以做明细数据的查询。这些查询相比直接使用Spark作为计算引擎,一般都能提供3~5倍的性能提升,如果硬件资源宽裕,将加速组件独立部署,将能获得更为优越的极速体验。