文本情感分析是对带有主观感情色彩的文本进行分析、处理、归纳和推理的过程。互联网上每时每刻都会产生大量文本,这其中也包含大量的用户直接参与的、对人、事、物的主观评价信息,比如微博、论坛、汽车、购物评论等,这些评论信息往往表达了人们的各种主观情绪,如喜、怒、哀、乐,以及情感倾向性,如褒义、贬义等。基于此,潜在的用户就可以通过浏览和分析这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法。
百分点认知智能实验室基于前沿的自然语言处理技术和实际的算法落地实践,真正实现了整体精度高、定制能力强的企业级情感分析架构。从单一模型到定制化模型演变、文本作用域优化、多模型(相关度)融合、灵活规则引擎、以及基于实体的情感倾向性判定,探索出了一套高精准、可定制、可干预的智能分析框架,为舆情客户提供了高效的预警研判服务。
一、情感分析概述
文本情感分析,即 Sentiment Analysis(SA),又称意见挖掘或情绪倾向性分析。针对通用场景下带有主观描述的中文文本,自动判断该文本的情感极性类别并给出相应的置信度,情感极性分为积极、消极、中性等。
在文本分析的基础上,也衍生出了一系列细粒度的情感分析任务,如:
- 基于方面的情感分析(ABSA):一般称作 Aspect Based Sentiment Analysis。旨在识别一条句子中一个指定方面(Aspect)的情感极性。常见于电商评论上,一条评论中涉及到关于价格、服务、售后等方面的评价,需要区分各自的情感倾向。
- 基于实体的情感倾向性判定(ATSA): 一般称作 Aspect-Term Sentiment Analysis。对于给定的情感实体,进行情感倾向性判定。在一句话中不同实体的情感倾向性也是不同的,需要区别对待。
▶ 核心目标和价值
舆情系统的最核心需求,是能够精准及时的为客户甄别和推送负面,负面识别的准确性直接影响信息推送和客户体验,其中基于文本的情感分析在舆情分析中的重要性不言而喻,下图简要展示了文本分析以及情感分析在舆情体系中的作用。
舆情数据通过底层的大数据采集系统,流入中间层的 ETL 数据处理平台,经过初级的数据处理转化之后,向上进入数据挖掘核心处理环节;此阶段进行数据标准化、文本深度分析,如地域识别、智能分词、情感判定、垃圾过滤等,经过文本处理的结果,即脱离了原始数据的状态,具备了客户属性,基于客户定制的监测和预警规则,信息将在下一阶段实时的推送给终端客户,负面判定的准确度、召回率,直接影响客户的服务体验和服务认可度。
▶ 难点与挑战
舆情业务中的情感分析难点,主要体现在以下几个方面:
1. 舆情的客户群体是复杂多样的,涉及行业多达24个(如下图所示),不同行业数据特点或敏感判定方案不尽相同,靠一个模型难以解决所有问题;
2. 舆情监测的数据类型繁多, 既有常规的新闻、微信公众号等媒体文章数据,又有偏口语化的微博、贴吧、问答数据,情感模型往往需要针对不同渠道类型单独训练优化,而渠道粒度的模型在不同客户上效果表现也差别巨大;
3. 客户对情感的诉求是有差异的,有些客户会有自己专属的判定条件。通用的情感模型难以适应所有客户的情感需求。
4. 随着时间推移,客户积累和修正的情感数据难以发挥价值。无法实现模型增量训练和性能的迭代提高。
5. 对于关注品牌、主体监测客户,需要进行特定目标(实体)情感倾向性(ATSA)判定。那么信息抽取就是一个难题。
6. 对于新闻类数据,通常存在标题和正文两个文本域。如何提取有价值的文本信息作为模型输入也是面临的困难。
二、情感分析在百分点舆情的发展历程
从2015年开始,百分点舆情便开始将机器学习模型应用在早期的负面判定中;到2020年,我们已经将深度迁移学习场景化和规模化,也取得了不错的成果;
2015年:抓取百万级别的口碑电商评论数据,使用逻辑回归进行建模,做为情感分析的BaseLine;
2016年:主要侧重于技术上的递进,进入深度学习领域。引入word2vec在大规模语料集上进行训练,获得具有更好语义信息的词向量表示,替代基于Tfidf等传统的统计特征。随后在TextCnn、TextRnn等深度学习算法进行更新迭代,尽管得到数字指标的提高,但是对于实际业务的帮助还是不足。
2017年:结合舆情全业务特点,需要能做到针对品牌、主体的情感监测。提出 Syntax and Ruler-based Doc sentiment analysis的方式,依据可扩充的句法规则以及敏感词库进行特定的分析。该方式在敏感精准度指标上是有提升的,但是却有较低的召回。同时在进行规则扩充时,也比较繁琐。
2019年上半年:以Bert为代表的迁移学习诞生,并且可以在下游进行fine-tune,使用较小的训练数据集,便能取得不错的成绩。进行以舆情业务数据为基础,构建一个简易的文本平台标注平台,在其上进行训练数据的标注,构建了一个通用的情感模型分类器。评测指标 F1值为 0.87,后续对 ERNIE1.0 进行尝试,有两个百分点的提升。
2019年下半年:主要从舆情的业务问题入手,通过优化提取更加精准、贴近业务的情感摘要作为模型输入,使用定制化模型以及多模型融合方案,联合对数据进行情感打标。并提出基于情感实体(主体)的负面信息监测,下述统称ATSA(aspect-term sentiment analysis),使用 Bert-Sentence Pair 的训练方式, 将 摘要文本、实体联合输入,进行实体的情感倾向性判定。在定点客户上取得不错的成绩,最后的F1值能达到 0.95。
2020年:将细化领域做到客户级别,定制私有化情感模型。同时将加大对特定实体的细粒度情感分析(ATSA)的优化;同时,通过内部 AI训练平台的规模化应用,做到模型的全生命周期管理,简化操作流程,加强对底层算力平台的资源管控。
三、预训练语言模型与技术解析
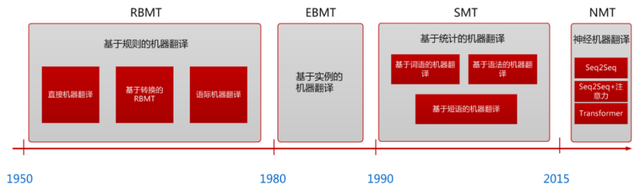
下图大致概括了语言模型的发展状况(未完全统计):
在2019年度情感分析实践中,率先使用预训练语言模型 Bert,提高了情感分析的准确率。后来具有更小参数量的ALBERT的提出,使生产环境定制化情感模型成为可能。这里就主要介绍BERT以及ALBERT。
▶ BERT
BERT(Bidirectional Encoder Representations from Transformerss)的全称是基于 Transformer 的双向编码器表征,其中「双向」表示模型在处理某一个词时,它能同时利用前面的词和后面的词两部分信息(如下图所示)。
在BERT中, 主要是以两种预训练的方式来建立语言模型。
1.MLM(Masked LM)
MLM可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]。此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,具体处理如下:
- 80%是采用[mask],my dog is hairy → my dog is [MASK]
- 10%是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
- 10%保持不变,my dog is hairy -> my dog is hairy
之后让模型预测和还原被遮盖掉或替换掉的部分。
2.NSP(Next Sentence Prediction)
首先我们拿到属于上下文的一对句子,也就是两个句子,之后我们要在这两段连续的句子里面加一些特殊 token: [cls] 上一句话,[sep] 下一句话. [sep]
也就是在句子开头加一个 [cls],在两句话之中和句末加 [sep],具体地就像下图一样:
- Token Embeddings:是词向量,第一个单词是CLS标志,可以用于之后的分类任务。
- Segment Embeddings:用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务。
- Position Embeddings:让BERT学习到输入的顺序属性。
BERT在文本摘要、信息检索、数据增强、阅读理解等任务中,也有实际的应用和发展。更多关于Bert相关介绍,请参照百分点认知智能实验室往期文章。
▶ ALBERT
ALBERT的全称是A Lite BERT for Self-supervised Learning of Language Representations(用于语言表征自监督学习的轻量级BERT),相对于Bert而言,在保证参数量小的情况下,也能保持较高的性能。当然同样的模型还有 DistilBERT、TinyBERT。
1.ALBERT 和BERT的比较
下图是BERT和ALBERT在训练速度和性能上的整体比较:
- ALBERT-xxlarge的表现完全超过BERT-large,同时参数量只有其占比的70%,但是Bert-large的速度要比ALBERT-xxlarge快三倍左右。
- BERT-xlarge的性能相对于Bert-base是低效的,表明大参数模型相对于小参数模型更加难训练。
2.ALBERT的目标
在基于预训练语言模型表征时,增加模型大小一般可以提升模型在下游任务中的性能。但是通过增加模型大小会带来以下问题:
- 内存问题
- 训练时间会更长
- 模型退化
在将Bert-large的隐层单元数增加一倍, Bert-xlarge在基准测试上准确率显著降低。
ALBERT核心目标就是解决上述问题, 下面就来介绍ALBERT在精简参上的优化。
3.ALBERT模型优化
明确参数的分布,对于有效可靠的减少模型参数十分有帮助。ALBERT同样也只使用到Transformer的Encoder阶段,如下图所示:
图中标明的蓝色方框和红色方框为主要的参数分布区域:
- Attention feed-forward block(上图中蓝色实线区域):
- 参数大小: O(12 * L * H * H)
- L:编码器层数 eg:12
- H:隐藏层大小 eg:768
- 参数量占比:80%
- 优化方法:采用参数共享机制
- Token embedding projection block(上图中红色实线区域):
- 参数大小:(V * E)
- V:词表大小 eg:30000
- E:词嵌入大小 eg:768
- 参数量占比: 20%
- 优化方法:对Embedding进行因式分解
具体参数优化如下:
Factorized embedding parameterization(对Embedding因式分解)
ALBERT认为,token embedding是没有上下文依赖的表述,而隐藏层的输出值不仅包括了词本身的意思还包括一些上下文信息,因此应该让H>>E,所以ALBERT的词向量的维度是小于encoder输出值维度的。在NLP任务中,通常词典都会很大,embedding matrix的大小是E×V。
ALBERT采用了一种因式分解(Factorized embedding parameterization)的方法来降低参数量。首先把one-hot向量映射到一个低维度的空间,大小为E,然后再映射到一个高维度的空间,当E<<H时参数量减少的很明显。如下图所示:
可以看到,经过因式分解。参数量从O(V * H) 变为O(V*E + E*H),参数量将极大减小。如下图所示:在H=768条件下,对比E=128和E=768,参数量减少17%,而整体性能下降0.6%。
在后续的实验环境(所有的优化汇总后),对 embedding size 的大小进行评估,得出在 E=128时,性能达到最佳。
Cross-layer parameter sharing(跨层参数共享)
下图是对BERT-Base Attention分布的可视化。对于一个随机选择的句子,我们可视化来自不同Layer的Head的Attention分布。可以看到,底层的Attention分布类似于顶层的Attention分布。这一事实表明在某种程度上,它们的功能是相似的。
Transformer中共享参数有多种方案,只共享feed-forward层,只共享attention层,ALBERT结合了上述两种方案,feed-forward层与attention层都实现参数共享,也就是说共享encoder内的所有参数。但是需要主要的是,这只是减少了参数量,推理时间并没有减少。如下图所示:在采用 all-shared模式下,参数量减少70%,性能下降小于3%。
在经过上述的参数优化后,整体参数量有了极大的缩减,训练速度也极大加快。后续作者又在模型变宽和模型变深上做了几组实验。如下:
模型变宽
当我们增加 H 大小时,性能会逐渐提高。在H=6144时,性能明显下降。如下图所示:
模型变深
在以ALBERT-large为基础参数,设置不同的layer大小,发现layer=48的性能要差于layer=24的性能,如下图所示:
一些实验表示NSP(BERT-style)非但没有作用,反而会对模型带来一些损害。作者接着提出SOP(ALBERT-style)的优化模式。具体如下:
Inter-sentence coherence loss(句子连贯性)
在ALBERT中,为了去除主题识别的影响,提出了一个新的任务 sentence-order prediction(SOP),SOP的正样本和NSP的获取方式是一样的,负样本把正样本的顺序反转即可。SOP因为是在同一个文档中选的,只关注句子的顺序并没有主题方面的影响。并且SOP能解决NSP的任务,但是NSP并不能解决SOP的任务,该任务的添加给最终的结果提升了一个点。
在后续的实验中, ALBERT在训练了100w步之后,模型依旧没有过拟合,于是乎作者果断移除了dropout,没想到对下游任务的效果竟然有一定的提升。
当然作者对于增加训练数据和训练时长也做了详尽的对比和测试,这里不再进行描述。
在最初的 ALBERT发布时,是只有中文的。感谢数据工程师徐亮以及所在的团队,于 2019 年 10 月,开源了首个中文预训练的中文版 ALBERT 模型。
项目地址: https://github.com/brightmart/albert_zh
四、情感分析在舆情的应用实践
▶ 业务调研
2019上半年,舆情服务的整体情感判定框架已经迁移到以Bert训练为基础的情感模型上,得出的测试指标 F1 值为 0.86,相较于旧版模型提升显著; 但是虽然数据指标提升明显,业务端实际感受却并不明显。因此我们对代表性客户进行采样调查,辅助我们找出生产指标和实验室指标差异所在。同时针对上文提到的关于舆情业务中情感分析的痛点和难点,进行一次深度业务调研:
1.客户情感满意度调查
2.文本作用域(模型输入文本选择)调研
这里将文本作用域分为以下几个层次,分布情况如下图所示:
- 标题:正常文章的标题
- 全文: 标题和正文的统称
- 情感摘要:依据客户的输入特征词,从文章中抽取一段摘要;长度在256字符内。
- 关键词周边:只关注所配置关键词周边的文本作用域,一般是一句话。
- 主体(实体)词周边:依据客户所配置的品牌词、主体词,选取对应的文本作用域。
3.情感判定因素
这里对判定因素做以下介绍:
- 自然语义:是指符合人们的情感判定标准,像 色情、暴力、违禁、邪教、反动等言论都是敏感信息的范畴。比如:”#28天断食减肥[超话]#美柚说我还有4天就来姨妈了,所以是快要来姨妈了体重就掉的慢甚至不掉了吗,心塞。” 属于敏感。
- 主体(实体)情感:一般涉及到的是 人名、地名、机构名、团体名、产品名、品牌名、”我“、”作者“等; 如果监测主体为美柚,那么上述文本的情感倾向性就是非敏感。再举例如下:”墨迹天气又忘记签到了,这个记性越来越差“,墨迹天气是监测主体,那么属于非敏感。
- 业务规则: 是指以一种可表示、可量化、可总结、可表达的形式总结知识和规则,已经不符合自然语义的理解范畴。
- 业务规则&自然语义:客户的负面信息判定是结合业务规则,并且是符合自然语义判定标准的。
我们针对上述调研结果进行详尽分析,最终确定走情感细粒度模型的道路。
▶ 情感分析的落地实践
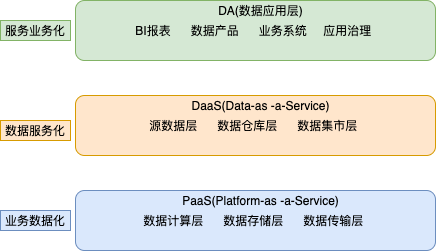
精简版本的情感架构概览如下:
接下来会基于此进行讲述,大致分为如下几个层次:
1.输入层
这里主要是获取相应文本输入,以及客户的文本作用域规则和检索词、主体词,供下游的文本作用域生成提供对应的条件。
2.文本作用域
依据文本作用域规则,生成对应的模型输入,请参照上文对文本作用域的阐述。这里实验内容针对的是情感摘要。首先将文本进行分句,然后依据对每一个句子和检索词进行匹配,通过BM25计算相关性。这里限制的文本长度在256内。在文本域优化后, 对线上的10家客户进行对比分析,实验条件如下:
- 客户数目:10
- 数据分布:从舆情系统中按照自然日,为每个客户选取100条测试数据
- 对比条件:情感摘要、标题
进行对比分析(客户名称已脱敏),每个客户的情感摘要和文本标题效果依次展示。如下图所示:
可以发现整体效果是有极大提升的。但是也可以看到部分客户的敏感精准率是偏低的,这个和客户的敏感分布有关,大部分的敏感占比只有总数据量的 10% ~20%,有些甚至更加低。所以面临一个新的问题,如何提升非均匀分布的敏感精准度。这个会在下文进行陈述。
3.情感判定因素
由上文的情感因素分布得知, 情感对象(实体)的因素占54%,基于实体的情感倾向性判定(ATSA)是一个普适需求。如果这里直接使用通用情感分析判定(SA),在舆情的使用场景中会存在高召回,低精准的的情况。接下来会对此进行相关解决方案的的论述。
4.模型层
- 通用情感模型
在19年初, 使用Bert-Base(12L,768H)进行fine-tune,得到如下指标:情感准确性:0.866, 敏感精准率: 0.88,敏感召回:0.84,F1: 0.867;后来在ERNIE1.0上进行尝试,情感准确性能提升2个百分点。不过因为PaddlePaddle的生态问题,没有选择ERNIE。这是一个符合自然语义的情感模型, 但是对于舆情客户来说,这还远远不够。
- 相关度模型
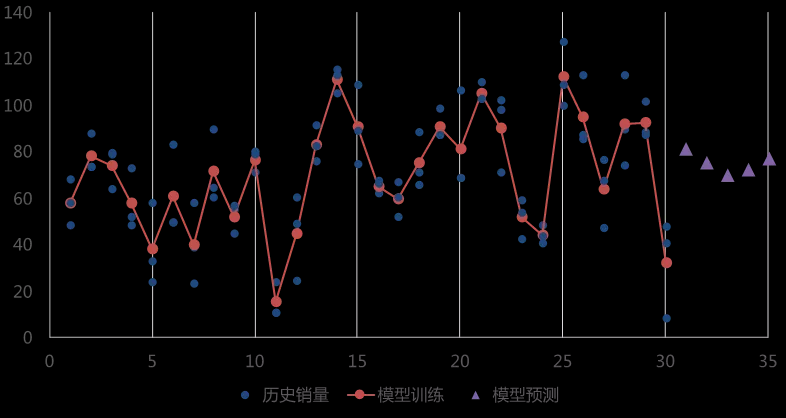
对生产环境的埋点日志分析,发现客户存在大量的屏蔽操作。选取近一个月屏蔽最多的10个话题进行分析,如下图所示:
通过调研和分析发现,这些数据虽然命中关键词,但是数据相关度比较低。在情感判定之前引入相关度判定, 对于非相关的数据,一律判定为非敏感。对于精准数据再次进行情感分析判定,大大提升敏感精准率。在工程上选取ALBERT进行模型训练可以达到部署多个模型的目的。观测到,单个模型在推理阶段,在Gpu(RTX 2080)上占用的显存大约在600MiB,极大节省资源。
部分客户相关度模型效果如下:
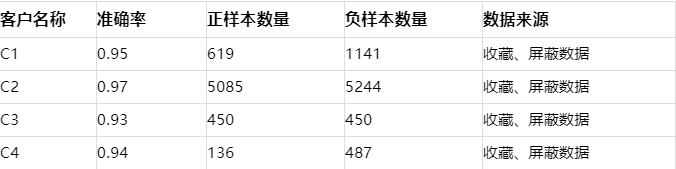
部分客户实施相关度判定,由于数据特征比较明显,可以很容易达到比较精准的数据效果,但是并不适用于所有客户。相关度模型的引入,即达到筛选相关数据的目的,也能减少情感判定噪音数据的干扰,提升敏感精准度。
5.ATSA-面向情感实体的情感倾向性分析
ATSA(aspect-term sentiment analysis) 要解决就是在特定情感实体下的情感倾向性判定问题。这里主要借鉴《Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence》文中的思想。这个工作做得非常聪明,它把本来情感计算的常规的单句分类问题,通过加入辅助句子,改造成了句子对匹配任务。很多实验证明了:BERT是特别适合做句子对匹配类的工作的,所以这种转换无疑能更充分地发挥BERT的应用优势。
舆情中要解决的问题如下:
A公司和B公司的情感倾向性是非敏感的, 而C公司却是敏感的。要解决这个问题,要面临两个问题:
- 实体识别和信息抽取问题
- 实体级别的情感倾向性判定
在舆情的业务场景中,可以简化问题,由于情感实体是提前给定的, 所以不需要做实体识别和信息抽取, 只需要对特定实体的情感倾向性进行判定。整体流程如下:
主要是利用 Bert Sentence-Pair,文本与实体联合训练,得到输出标签。目前实验证明,经过这种问题转换,在保证召回率提升的情况下,准确率和精准率都得到了提高。选取一个客户进行对比测试,如下所示:

上述是一个正负样本及其不均匀的情况,增加敏感精准率将提高客户的满意度。目前的实现的机制还略显简单,未来还将持续投入。
6.情感规则引擎
在部分客户场景中, 他们的业务规则是明确的或者是可穷举的。这里会做一些长尾词挖掘、情感新词发现等工作来进行辅助, 同时要支持实时的干预机制,快速响应。比如某些客户的官方微博经常会发很多微博,他们会要求都判定成非敏感。这里不再做过多介绍。
五、长期规划
▶ AI 训练平台的构建
软件开发领域和模型开发领域的流程是不同的,如下所示:
可以看到,构建模型是困难的。在舆情架构发展中,线上多模型是必然的趋势,也就意味着需要一个平台能够快速支持和构建一个定制化模型,来满足真实的应用场景。这就需要从底层的算力资源进行管控、舆情数据的标准化制定和积累、模型的生命周期管理等多方面进行衡量。关于 AI 训练平台的构建以及在舆情领域的应用实践,我们将在后续文章做进一步阐述。
▶ 持续学习,增量迭代
随着舆情客户对系统的深度使用,一般会有情感标签的人工纠正。所以需要保证模型可以进行增量迭代,减少客户的负反馈。
▶ 多实体的情感倾向分析
对包含有多个实体信息的文本,针对每一个系统识别到的实体,做自动情感倾向性判断(敏感、非敏感),并给出相应的置信度,包括实体库的构建。
▶ 提升垂直类情感情感分析效果
在垂类上(App、餐饮、酒店等)情感倾向性分析准确率上加大优化力度。
随着舆情业务的发展,各领域客户都沉淀了大量与业务贴近的优质数据,如何有效使用这些数据,形成情感效果联动反馈机制,为业务赋能,是情感分析领域面临的新的挑战。在2019年的实践中,通过场景化的情感分析框架落地应用,对情感效果做到了模型定制化干预,真正提高了客户满意度。这种机制具有整体精度高、定制能力强、业务感知明显的特点。在后续工作中,将以 模型训练自动化与人工反馈相结合的方式,将模型定制能力规模化、平台化,实现情感分析在舆情场景下千人千面的效果。
百分点舆情洞察系统
百分点舆情洞察系统(MediaForce)是一款沉淀多年的互联网公开舆情 SAAS 分析系统,覆盖全网主流资讯站点及社交媒体的公开数据,帮助企业迅速发现舆情热点,掌握负面和舆论动向,为上万客户提供精准的舆情分析服务。
参考资料:
- Chi Sun, Luyao Huang, Xipeng Qiu: Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence. NAACL-HLT (1) 2019: 380-385
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT (1) 2019: 4171-4186
- Yifan Qiao, Chenyan Xiong, Zheng-Hao Liu, Zhiyuan Liu: Understanding the Behaviors of BERT in Ranking. arXiv preprint arXiv:1904.07531 (2019).
- Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations.arXiv:1909.11942 [cs.CL]
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin:Attention Is All You Need.arXiv:1706.03762 [cs.CL]
- Linyuan Gong, Di He, Zhuohan Li, Tao Qin, Liwei Wang, Tieyan Liu ; Proceedings of the 36th International Conference on Machine Learning, PMLR 97:2337-2346, 2019:Efficient Training of BERT by Progressively Stacking
- https://github.com/thunlp/PLMpapers
- http://jalammar.github.io/illustrated-bert/
- https://www.bilibili.com/video/BV1C7411c7Ag?p=4
来源:百分点